
Many of Meta’s products, such as search, ads ranking and Marketplace, utilize AI models to continuously improve user experiences. As the performance of hardware we use to support training infrastructure increases, we need to scale our data ingestion infrastructure accordingly to handle workloads more efficiently. GPUs, which are used for training infrastructure, tend to double in performance every two years, while the performance of CPUs, used for data reading computation, increases at a much slower pace in the same time frame.
To facilitate the level of data ingestion required to support the training models supporting our products, we’ve had to build a new data ingestion infrastructure as well as new last-mile transformation pipelines. By optimizing areas of our data ingestion infrastructure, we improved our power budget requirement by 35-45%, allowing us to support a growing number of AI models in our power constrained data centers.
Meta’s growing AI infrastructure
As our product groups continue to rely heavily on AI models to improve product experience, the AI infrastructure requirements are growing along the following dimensions:
- Number of models being trained
- Volume of data and features that models train on
- Model size and complexity
- Model training throughput
In the figure below, we observe that over the last two years we have grown:
- 1.75-2x in the amount of data we train on
- 3-4x in data ingestion throughput
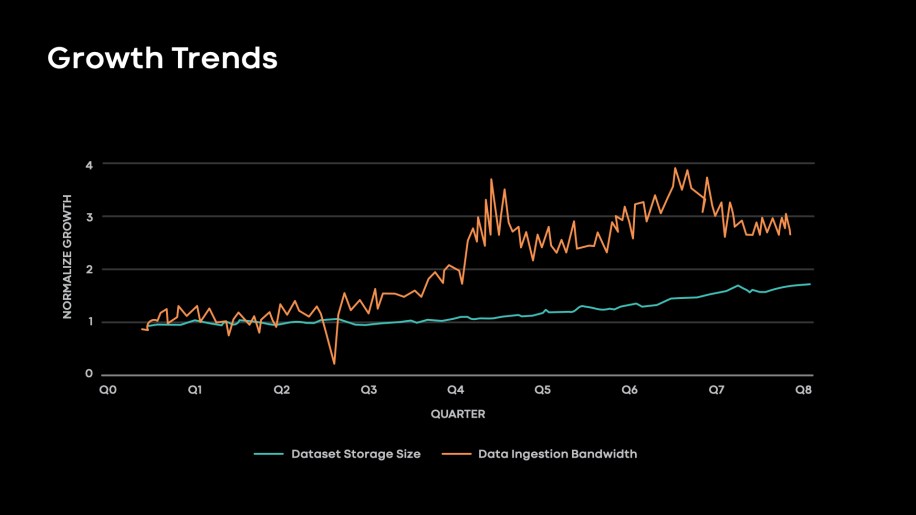
Fig. 1: Normalized dataset size growth and data ingestion bandwidth growth observed in production.
Our data centers must be provisioned to serve infrastructure that trains thousands of models, each consuming petabyte scale datasets. We must enable our engineers to have maximum flexibility when experimenting with new features and training model architectures. In the sections below, we share our experience building data ingestion and last-mile data preprocessing pipelines that are responsible for feeding data into AI training models.
Data ingestion pipeline overview
We have exabytes of training data powering our models, and the amount of training data is growing rapidly. We have a wide variety of models that train on terabyte- to petabyte-scale data, but we do not have the storage capacity at that scale to train the data locally on the training hardware. We store and serve training data from Tectonic, Meta’s exabyte-scale distributed file system that serves as a disaggregated storage infrastructure for our AI training models. Our AI training datasets are modeled as Hive Tables and encoded using a hybrid columnar format called DWRF, based on the Apache ORC format.
The process of selecting raw data and transforming it into features that can be consumed by machine learning (ML) training models is called feature engineering. This is at the core of ML training, and our ML engineers must experiment with new features on a daily basis. We model features as maps in training tables. This gives Meta’s engineers the flexibility to add and remove features easily without continuously maintaining the table schema.
We have built a disaggregated Data PreProcessing tier (DPP) that serves as the reader tier for data ingestion and last-mile data transformations for AI training.
This is responsible for:
– Fetching data from Tectonic clusters
– Decrypting and decoding data
– Extracting the features to be consumed by the model
– Converting the data to tensor formats
– Performing last-mile transformations before actual training
For content understanding models, examples of last-mile transformations could mean randomized image clips or crops to detect objectionable images, for example. With recommendation models, last-mile transformations typically trigger operations like feature normalization, bucketization, truncation, sort by score, or even operations that combine multiple features to form new features, like ngram, or categorical feature intersections and unions.
DPP allows us to scale data ingestion and training hardware independently, enabling us to train thousands of very diverse models with different ingestion and training characteristics. DPP provides an easy-to-use, PyTorch-style API to efficiently ingest data into training. It enables classes of new features by leveraging its disaggregated compute tier to support feature transformations (these operations are often computationally intensive). DPP executes in a data parallel fashion, with each compute node (DPP worker) reading, batching, and preprocessing a subset of training data rows. A lightweight DPP client module invoked in the trainer process fetches data from DPP worker nodes and transfers the data to training. DPP can also be invoked as a library on training nodes, in what we call the on-box mode, for models that do not have high throughput demands. However, in practice, many of our recommendation jobs use tens to hundreds of disaggregated nodes to ensure that we can meet the data ingestion demand of trainers . Several of our complex training jobs read massive volumes of data and can take several days to train. To avoid wasted compute due to failures, DPP has built-in support to checkpoint data cursors and resume jobs from checkpoints. Failed reader nodes are replaced transparently, without job interruption. DPP can also dynamically scale compute resources allocated for reading to ensure we can meet the data throughput demands from the trainers.
Our training infrastructure must serve a wide variety of models trained on distributed CPU and GPU hardware deployments.
The figure below shows our data ingestion architecture:
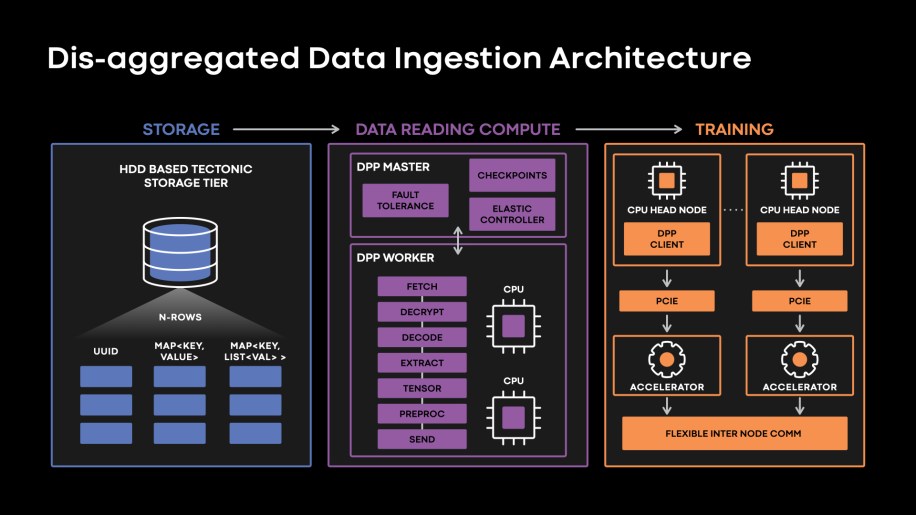
Fig. 2: Last-mile data ingestion infrastructure at Meta.
Data ingestion characteristics and optimizations
Trends in hardware evolution and data center power constraints
As mentioned above, we have a mismatch in the rate of growth for our training and ingestion hardware. Our disaggregated architecture enabled us to scale data ingestion for training needs. However, many recommendation models are ingestion-bound (Fig. 3). With a fixed power budget in our data centers, data ingestion requirements limit the training accelerators we can deploy.
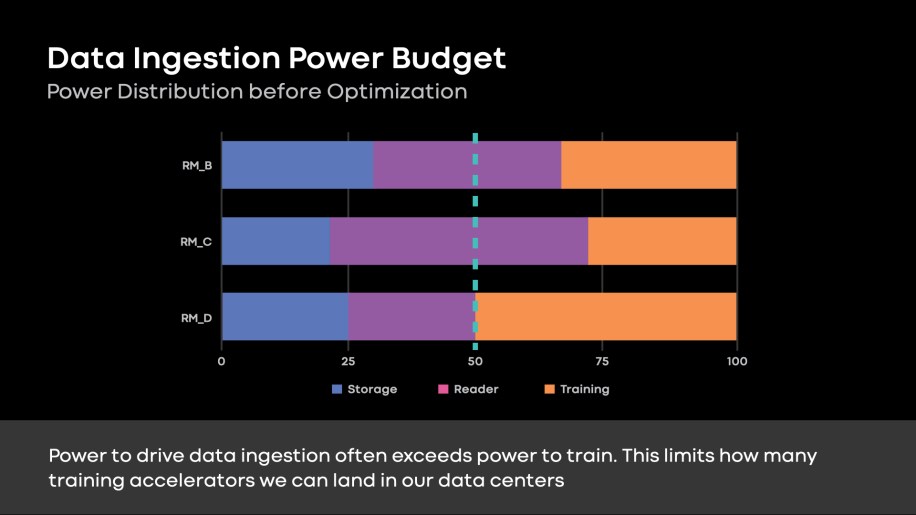
Fig. 3: Storage, reader compute, and training power distribution across three recommendation models. The sum of power allocation for storage and reader tiers is dominant for many ranking models. This limits the training accelerators we can land in our data centers, where we have fixed power budget constraints.
Data reading tier characterizations and optimizations
We have profiled several production recommendation models, and we’ve summarized the lessons learned around efficient data reading:
Optimizing algorithmic efficiency in readers:
Training datasets are often shared across multiple jobs, and a single training job often reads only a subset of the available features. This could mean reading as low as 20-37 percent of the stored bytes in many of our prominent ranking models.
The original map column layout did not provide efficient ways to read a subset of features from the available features (see Fig. 4). The data layout of the features in the original map meant we had to fetch, decrypt, and decode the entire map object to extract the features needed by the model.
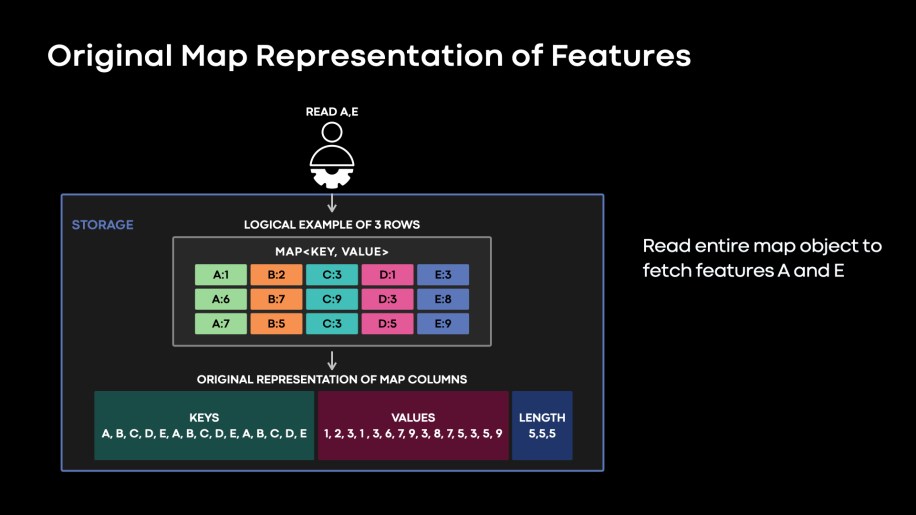
Fig. 4: Original data layout of the feature maps. We need to fetch, decode, and decrypt entire Keys, Values, and Lengths columns to extract desired features of A and E.
We implemented a new storage format called feature flattening, which represents each feature as a stream on a disk, as if we had n columns instead of a map of n features. This columnar feature representation enables reading subsets of features more efficiently. We call this reading functionality as “feature projection.”
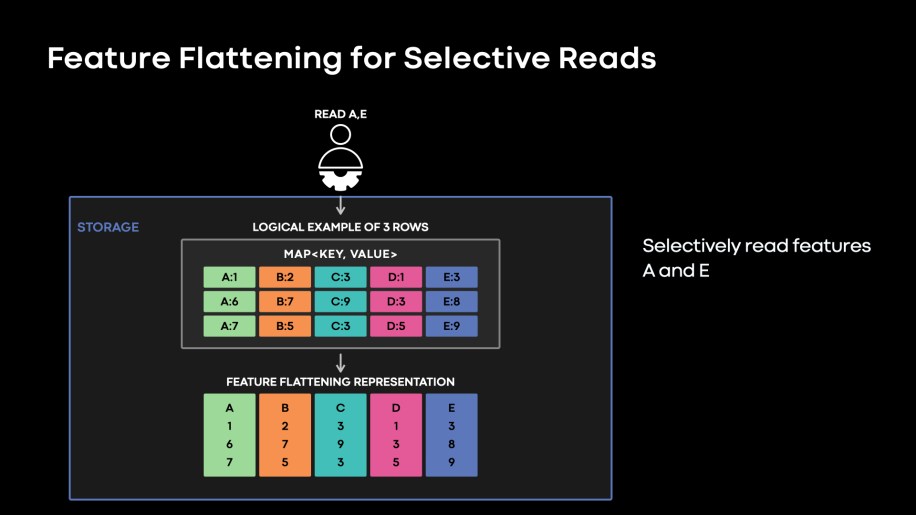
Fig. 5: Feature flattening stores individual features in contiguous streams. This format is more efficient when the goal is to selectively read a subset of features.
Since most of our production workloads were selective in terms of features consumed by models compared with features stored in storage, feature projection yielded high data reading efficiency wins, to the tune of 2-2.3x. The normalized throughput gains metric shown in the figure below indicates the improvements in the rows/s metric as executed b by each DPP reader.
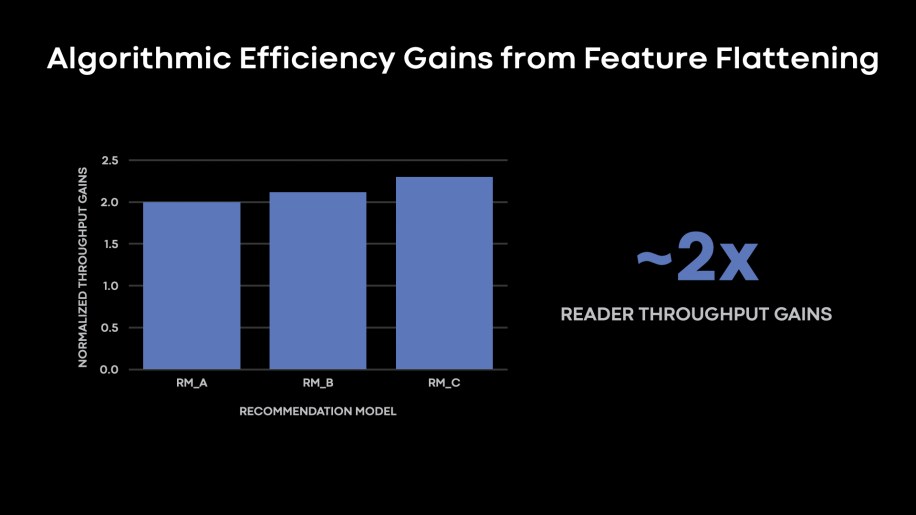
Fig. 6: Normalized throughput gains from feature flattening rollouts in three sample ranking models in our production fleet. Models that selectively read a smaller subset of features in the storage tier (which is typical in our AI training production environment) benefit from feature flattening representation of data.
Optimizing memory consumption for the data reading tier: The DPP readers provide batches of data for training, or, a number of input rows to be consumed in one training iteration. As training infrastructure onboarded more powerful accelerators, we observed the trend of increasing batch -sizes to increase the training throughput of rows/s on the beefier training nodes. We found several use cases where DPP workers that executed on simpler CPU nodes became memory-bound to support larger batch sizes. We observed that most users mitigated this by launching readers with fewer threads to avoid out-of-memory (OOM) errors. Reducing reader node threads resulted in reduced per-node efficiency, or reduced rows/s as executed by each reader node. To support large batches, we proposed DPP client-side rebatching, where we still read smaller batches with hardware concurrency on our reader tier nodes. However, our client on the beefier training node is responsible for appending batches to support large batch exploration.
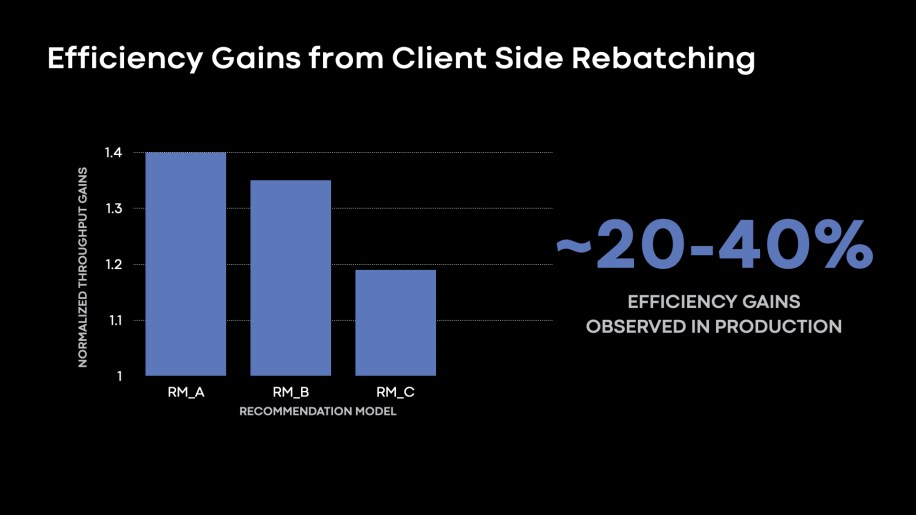
Fig. 7: Around 20-40 percent improvements in the rows/s throughput as executed by each reader node by enabling DPP Client side rebatching to support large batch explorations.
Optimizing memory bandwidth for the data reading tier
We expect most of our DPP nodes to be memory bandwidth-bound as we upgrade our data centers with newer CPU versions with more cores (and without a proportional increase of the available memory bandwidth). Many of our data reading workloads in production are memory bandwidth-bound. We also have identified scope to improve our memory bandwidth utilization in preprocessing/transformation operators we executed on the readers. In this section, we will discuss the project of FlatMaps, which yielded improvements in terms of memory bandwidth utilization on the DPP readers.
As explained in the section above, with feature flattening we changed the physical layout of our features in the storage tier. However, due to legacy reasons of reading unflattened tables, we identified that our in-memory representation of a batch in the DPP reader worker was obsolete, triggering unnecessary format transformations. This is illustrated in Fig. 8, below.
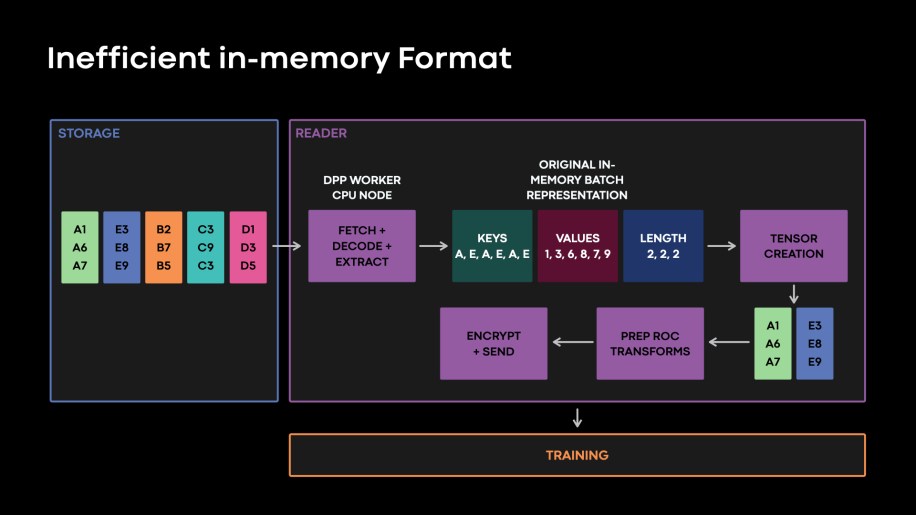
Fig. 8: Our original in-memory batch data representation manifested the original map layout of features shown in Fig. 4. Reading flattened features from storage, translating this data to the legacy in memory batch representation and then converting the data to tensors triggered unnecessary data format transformations.
By identifying a column major in-memory format to read flattened tables, we avoided unnecessary data layout transformations as illustrated in Fig. 9, below.
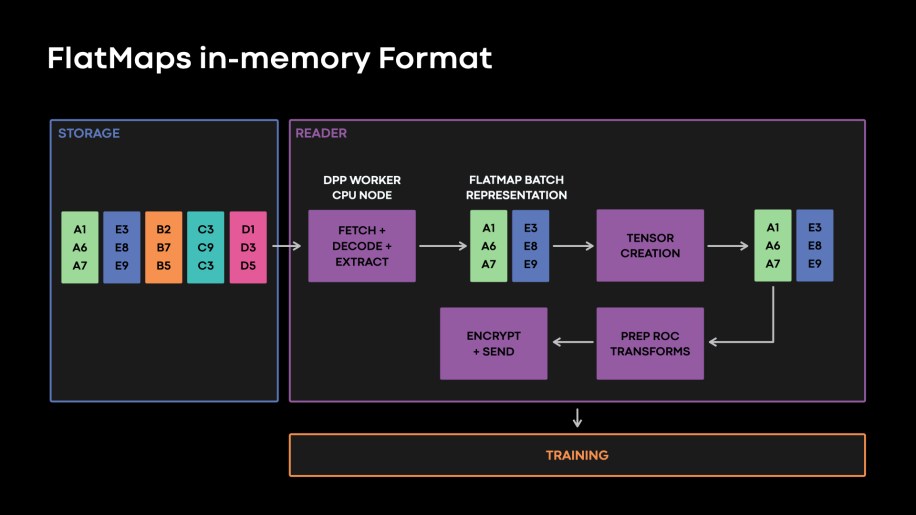
Fig. 9: Illustration of data format and Flatmap in-memory representation in readers. This in-memory format eliminates unnecessary data layout transformations from features in our storage tier to tensors that training must consume.
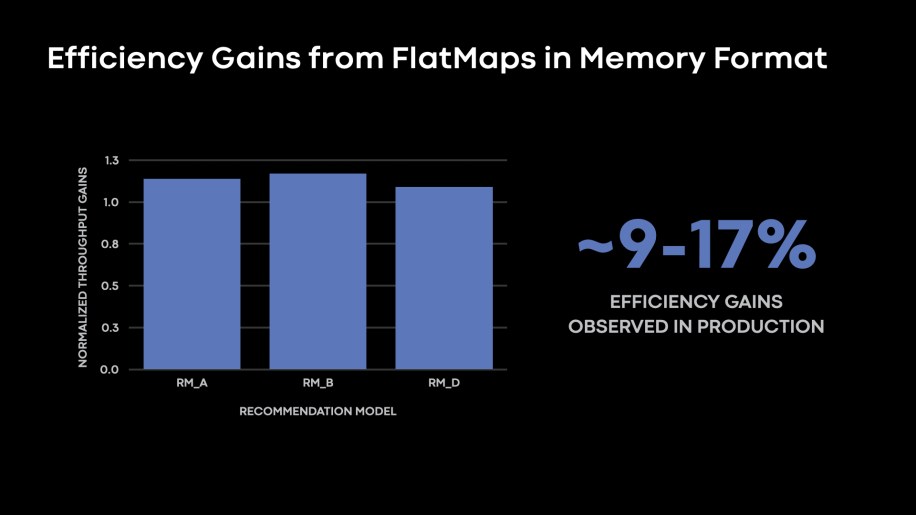
Fig. 10: 9-17 percent the Rows/s throughput as executed by each reader node by applying the FlatMaps in-memory data representations.
In general, optimizing data reading tier memory bandwidth utilization remains one of the most compelling areas we continue to invest in to efficiently utilize the newer CPU versions landing in our data centers.
Scaling the storage tier to serve AI access patterns
Let us take a look at what drives storage tier power cost. Despite individual models training on terabyte- to petabyte-scale data, we find that many of our models training on accelerators are IO bound due to massive training throughput demand. One reason for this is that models train on a subset of features that are saved in our dataset. Selectively seeking features consumed by models results in smaller IOSize for our disk accesses, thus increasing IOPs demand. On the other hand, if we overread consecutive features in the storage block to minimize seeks, we end up reading bytes that eventually get dropped by training. This is illustrated in Fig. 11, below.
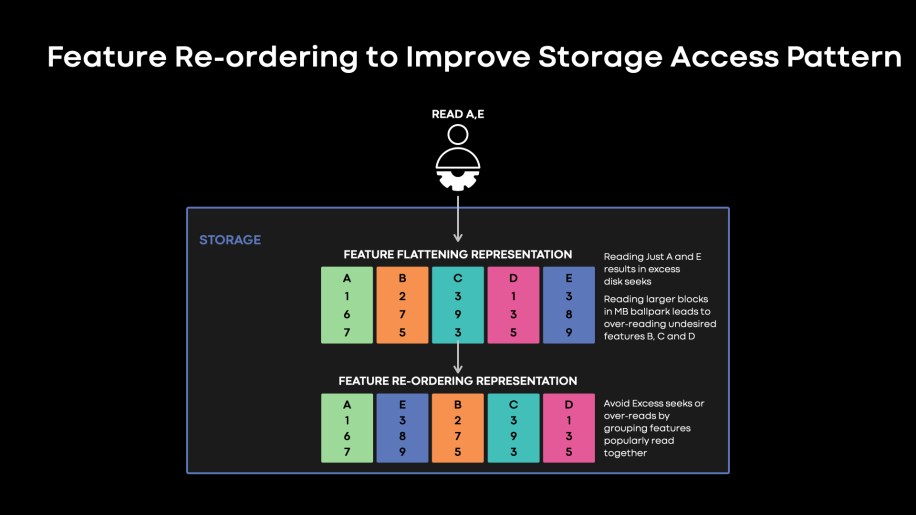
Fig. 11: Feature Re-ordering illustration. Feature re-ordering writes features that are popularly consumed together in continuous blocks in our storage tier.
In fact, we had some production models that were NIC-bound at the reader ingress due to high overreads from the storage tier. By eliminating over-reads, we were able to further improve data reading algorithmic efficiency for these models as we observed these models moving from being NIC-bound on the readers to memory bandwidth-bound. In the figure below, we present the reduction we observed in storage tier to reader tier data transfer and improvement in storage tier service time once we applied feature reordering.
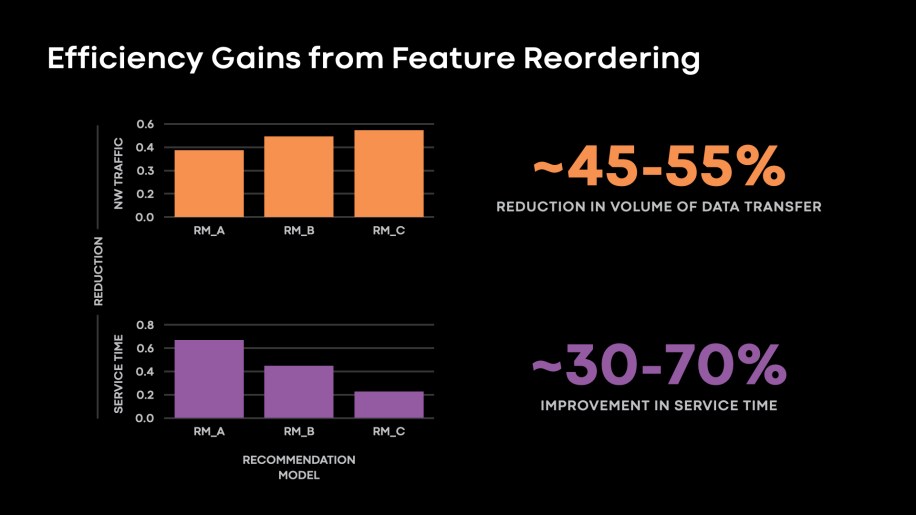
Fig. 12: Feature Re-ordering yielded 45-55% reduction in volume of data transferred between storage tier and reader tiers. We also observed 30-70% improvement in service time for several of our models.
Applying the optimizations discussed in this post, Fig. 13, below, illustrates the improvements in data ingestion power budget observed in our recommendation models.
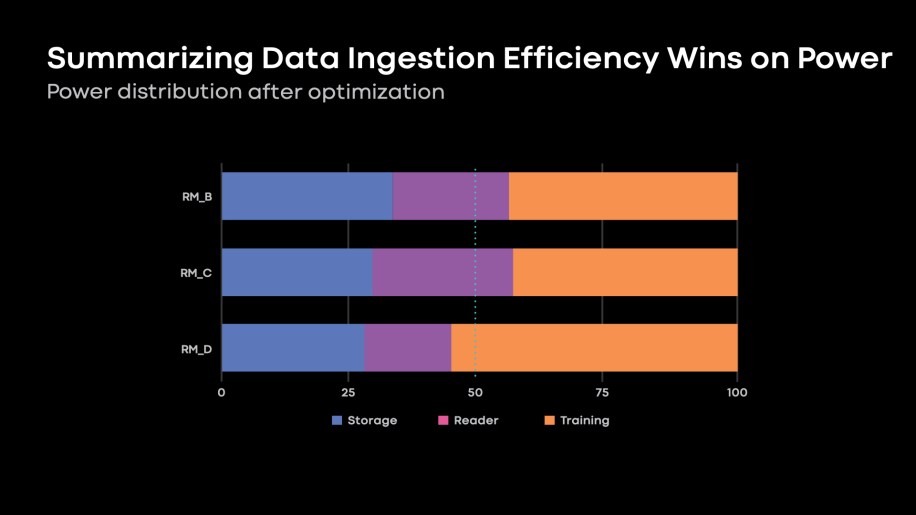
Fig. 13: 35-45 % improvements in data ingestion power budget as compared to Fig. 4.
Areas of future exploration
We’re continually working to optimize the pipelines responsible for last- mile data ingestion and computation to meet the demands of AI-driven products at Meta. We are committed to delivering an efficient and scalable infrastructure to support our product teams in achieving this mission.
Here are a few areas of exploration we’re examining going forward:
Tiered storage: Many of our datasets are large enough that our models only need to do a single pass. Hence, we are unable to exploit any data reuse within a job. However, we can exploit reuse patterns across concurrent jobs using the same data. We are working toward building a tiered storage solution, HDD + SSD, with SSD serving as the caching tier for high-reuse features.
Preprocessing transformations on GPUs: There have been industry-wide efforts to execute preprocessing transformation operations on accelerators. We contiue our efforts to invest in shifting the computation cycles of preprocessing from our hardware-constrained CPU to the beefier training accelerators. Outlining some challenges in our workloads in this space is that many of our preprocessing operators truncate or clip the volume of data being sent to training. With the possibility of preprocessing moving to training accelerators, we see the risk of increased data transfer to push data to the training accelerators. Another risk is that our models train on a large number of features and often go through several transformations before the final feature is derived. This results in non negligible CUDA kernel launch overheads, limiting the gains we can derive in this direction. That said, shifting preprocessing transformation to beefier training hardware is a very compelling direction, and our teams are actively working to de-risk this space.
Storing derived features: Since our recommendation models often train with only a single pass over the data, this limits our ability to reuse data within a job. However, we still find potential of expensive last-mile feature transformations being reused across multiple independent jobs. Our teams are working on identifying common and expensive transformations across independent jobs. In doing so, we aim to promote the transformations to full-fledged precomputed features in our storage tier instead of evaluating them in the last mile of data ingestion.








