
What the research is:
Federated learning with differential privacy (FL-DP) is one of the latest privacy-enhancing technologies being evaluated at Meta as we constantly work to enhance user privacy and further safeguard users’ data in the products we design, build, and maintain.
FL-DP enhances privacy in two important ways:
- It allows machine learning (ML) models to be trained in a distributed way so that users’ data remains on their mobile devices.
- It adds noise to reduce the risk of an ML model memorizing user data.
The benefits of FL-DP come with unique challenges that cannot be solved through conventional ML tools and practices. As such, we’ve developed a new system architecture and methodology capable of successfully addressing these challenges. Such an approach could enhance user privacy while still facilitating an intelligent, safe, and intuitive user experience across Meta’s family of technologies.
How it works:
With FL-DP, ML models are trained in a federated manner where mobile devices learn locally. A global ML model is only updated with these localized learnings only after noise is added, through a process called differential privacy. Differential privacy is an important step, as it is the best-known strategy for preventing ML models from memorizing training data, even in the most extreme scenarios (e.g., reconstruction attacks).
However, training ML models in this fashion does come with challenges that are both new and different from those of more conventional, centralized ML models, including:
- Label balancing, feature normalization, and metrics calculation due to lack of data visibility
- Slower mobile release cycles as compared with back-end release cycles
- Slower training due to the federation of training to mobile devices
- Anonymized system logging to keep data private
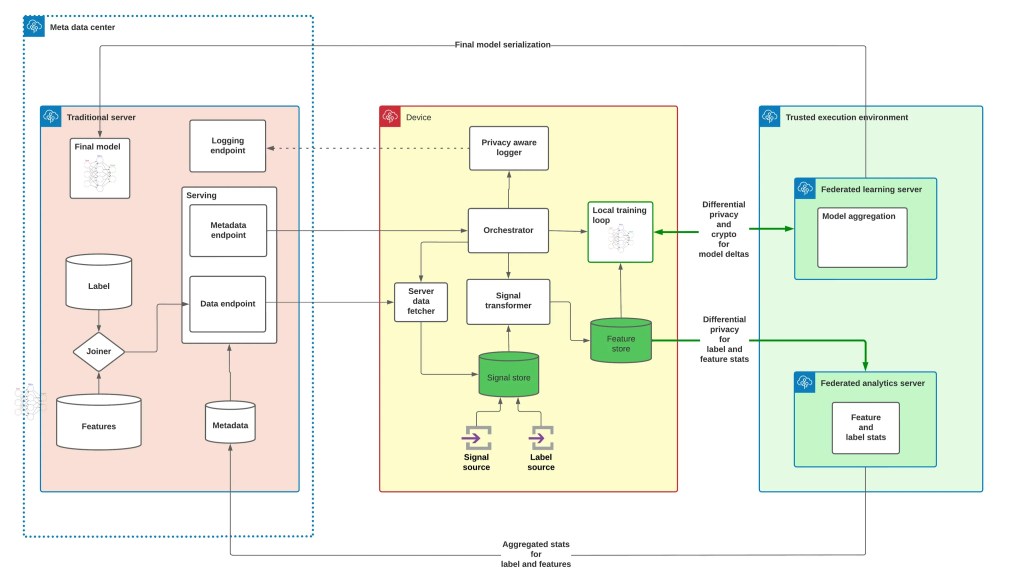
To address these challenges, we’ve designed an architecture and methodology that’s influenced by real-world applications of ML and allows model training to combine server-side user data with device-side-only user data to deliver inferences. Device-side-only user data remains on users’ devices. This architecture is a combination of infrastructure across mobile devices, trusted execution environments, and conventional back-end servers.
We validated this architecture using an in-house FL library that is compatible with Meta’s family of apps (such as Facebook and Instagram) and that has the potential to scale training to millions of devices and inferences to billions of devices. We compared this approach with conventional server-trained models and saw minimal degradation of model performance without transgressing constraints of limited on-device compute, storage, and power resources.
In designing our infrastructure architecture for FL with differential privacy, the idea was to improve developer efficiency. While there has been a good deal of research on enabling successful and efficient model training, there hasn’t been as much attention paid to the auxiliary core infrastructure components needed for speedy tuning and scalable deployment at inference time. This is why we chose to focus on the overall architectural design and integration.
Here’s a diagram of the major components of the system:
What’s next:
While this architecture is capable of successfully training and deploying production FL models, there are several challenges left for future work. Developer speed, in particular, remains one of the largest barriers to scaling production-grade federated ML. Current iterations of model development are several orders of magnitude slower compared with similar-sized undertakings within a centralized environment. We look forward to iterating on our architecture.








