
Training AI models at a large scale isn’t easy. Aside from the need for large amounts of computing power and resources, there is also considerable engineering complexity behind training very large models. At Facebook AI Research (FAIR) Engineering, we have been working on building tools and infrastructure to make training large AI models easier. Our recent work in areas such as intra-layer model parallelism, pipeline model parallelism, optimizer state+gradient sharding, and mixture of experts is just part of our work to make training advanced AI models for any number of tasks more efficient.
Fully Sharded Data Parallel (FSDP) is the newest tool we’re introducing. It shards an AI model’s parameters across data parallel workers and can optionally offload part of the training computation to the CPUs. As its name suggests, FSDP is a type of data-parallel training algorithm. Although the parameters are sharded to different GPUs, the computation for each microbatch of data is still local to each GPU worker. This conceptual simplicity makes FSDP easier to understand and more applicable to a wide range of usage scenarios (compared with intra-layer parallelism and pipeline parallelism). Compared with optimizer state+gradient sharding data parallel methods, FSDP shards parameters more uniformly and is capable of better performance via communication and computation overlapping during training.
With FSDP, it is now possible to more efficiently train models that are orders of magnitude larger using fewer GPUs. FSDP has been implemented in the FairScale library and allows engineers and developers to scale and optimize the training of their models with simple APIs. At Facebook, FSDP has already been integrated and tested for training some of our NLP and Vision models.
The high computational cost of large-scale training
NLP research is one particular area where we can see the importance of efficiently leveraging compute for training AI. Last year, OpenAI announced that they had trained GPT-3, the largest-ever neural language model, with 175 billion parameters. It is estimated to have taken roughly 355 GPU years to train GPT-3, or the equivalent of 1,000 GPUs working continuously for more than four months.
Besides requiring a lot of compute and engineering resources, most approaches to scaling like this introduce additional communication costs and require engineers to carefully evaluate trade-offs between memory use and computational efficiency. For example, typical data parallel training requires maintaining redundant copies of the model on each GPU, and model parallel training introduces additional communication costs to move activations between workers (GPUs).
FSDP is relatively free of trade-offs in comparison. It improves memory efficiency by sharding model parameters, gradients, and optimizer states across GPUs, and improves computational efficiency by decomposing the communication and overlapping it with both the forward and backward passes. FSDP produces identical results as standard distributed data parallel (DDP) training and is available in an easy-to-use interface that’s a drop-in replacement for PyTorch’s DistributedDataParallel module. Our early testing has shown that FSDP can enable scaling to trillions of parameters.
How FSDP works
In standard DDP training, every worker processes a separate batch and the gradients are summed across workers using an all-reduce operation. While DDP has become very popular, it takes more GPU memory than it needs because the model weights and optimizer states are replicated across all DDP workers.
One method to reduce replications is to apply a process called full parameter sharding, where only a subset of the model parameters, gradients, and optimizers needed for a local computation is made available. An implementation of this method, ZeRO-3, has already been popularized by Microsoft.
The key insight to unlock full parameter sharding is that we can decompose the all-reduce operations in DDP into separate reduce-scatter and all-gather operations:
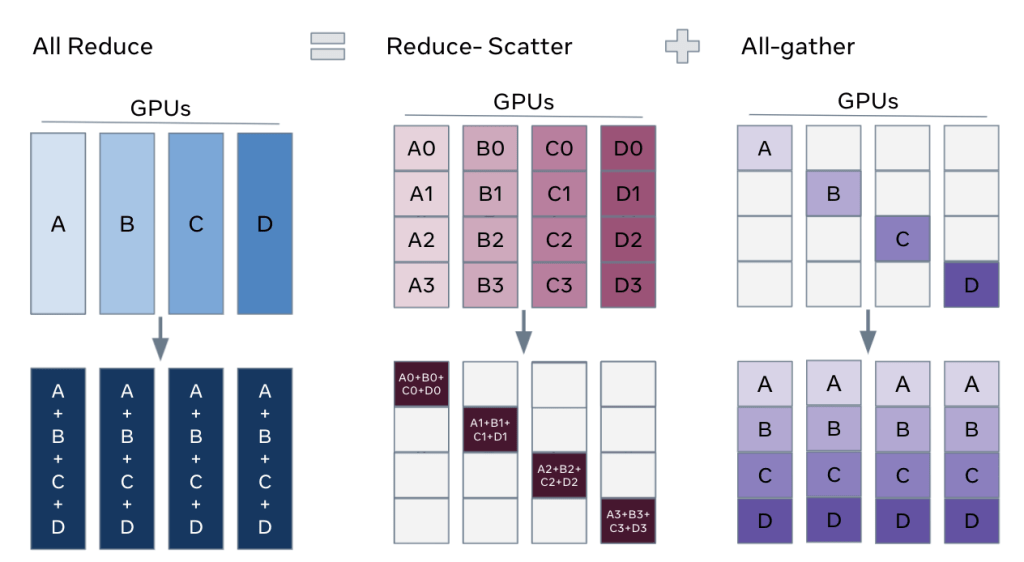
We can then rearrange the reduce-scatter and all-gather so that each DDP worker needs to store only a single shard of parameters and optimizer states. The figure below illustrates standard DDP training (top) and FSDP training (bottom):
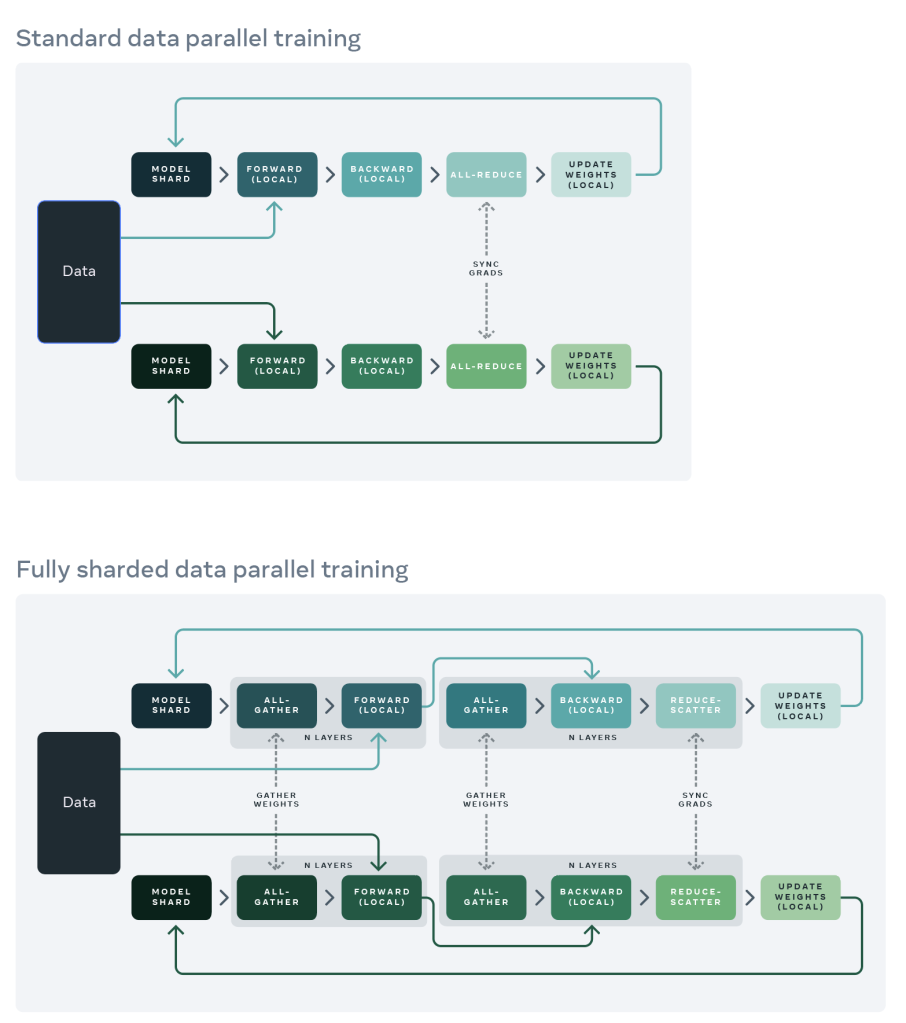
To maximize memory efficiency, we can discard the full weights after each layer’s forward pass, saving memory for subsequent layers. This can be implemented by applying the FSDP wrapper to every layer in the network (with reshard_after_forward=True).
In pseudo-code:
FSDP forward pass: for layer_i in layers: all-gather full weights for layer_i forward pass for layer_i discard full weights for layer_i FSDP backward pass: for layer_i in layers: all-gather full weights for layer_i backward pass for layer_i discard full weights for layer_i reduce-scatter gradients for layer_i
How to use FSDP
There are several ways to use FSDP in large-scale AI research. At this time, we offer four solutions to adapt to different needs.
1. Using FSDP in language models
For language models, FSDP is supported in the fairseq framework via the following new arguments:
- –ddp-backend=fully_sharded: enables full sharding via FSDP
- –cpu-offload: offloads the optimizer state and FP32 model copy to CPU (combine with–optimizer=cpu_adam)
- –no-reshard-after-forward: increases training speed for large models (1B+ params) and is similar to ZeRO stage 2
- Other popular options (–fp16, –update-freq, –checkpoint-activations, –offload-activations, etc.) continue to work as normal
See the fairseq tutorial for instructions on using FSDP to train a 13B-parameter model on eight GPUs or on a single GPU with FSDP + CPU offloading.
2. Using FSDP in computer vision models
For computer vision models, FSDP is supported in VISSL and tested on RegNets architectures. Layers like BatchNorm and ReLU are seamlessly handled and tested for convergence.
Use the following options to enable FSDP:
- config.MODEL.FSDP_CONFIG.AUTO_SETUP_FSDP=True
- config.MODEL.SYNC_BN_CONFIG.SYNC_BN_TYPE=pytorch
- config.MODEL.AMP_PARAMS.AMP_TYPE=pytorch
See this section of the yaml config for additional options to config FSDP within VISSL.
3. Using FSDP from PyTorch Lightning
For easier integration with more general use cases, FSDP is supported as a beta feature by PyTorch Lightning. This tutorial contains a detailed example on how to use the FSDP plugin with PyTorch Lightning. At a high level, adding plugins=’fsdp’ below can activate it.
model = MyModel() trainer = Trainer(gpus=4, plugins='fsdp', precision=16) trainer.fit(model) trainer.test() trainer.predict()
4. Using the FSDP library directly from FairScale
The main library where FSDP has been developed, and where you can find the latest updates, is FairScale. You can directly use FSDP from FairScale with the below example by simply replacing the DDP(my_module):
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP ... sharded_module =DDP(my_module)FSDP(my_module) optim = torch.optim.Adam(sharded_module.parameters(), lr=0.0001) for sample, label in dataload.next_batch: out = sharded_module(x=sample, y=3, z=torch.Tensor([1])) loss = criterion(out, label) loss.backward() optim.step()
The FSDP library in FairScale exposes the low-level options for many important aspects of large-scale training. Here are some few important areas to consider when you apply FSDP with its full power.
- Model wrapping: In order to minimize the transient GPU memory needs, users need to wrap a model in a nested fashion. This introduces additional complexity. The auto_wrap utility is useful in annotating existing PyTorch model code for nested wrapping purposes.
- Model initialization: Unlike DDP, FSDP does not automatically synchronize model weights between GPU workers. This means model initialization must be done carefully so that all GPU workers have the identical initial weights.
- Optimizer settings: Due to sharding and wrapping, only certain types of optimizer and optimizer settings are supported by FSDP. In particular, if a module is wrapped by FSDP and its parameters are flattened into a single tensor, users cannot use different hyperparameters for different parameter groups in such a module.
- Mixed precision: FSDP supports advanced mixed precision training with FP16 master weights, as well as FP16 reduce and scatter on the gradients. Certain parts of a model may converge only if full precision is used. In those cases, additional wrapping is needed to selectively run parts of a model in full precision.
- State checkpointing and inference: When the model scale is large, saving and loading the model state can become challenging. FSDP supports several ways to make that task possible, but it is by no means trivial.
- Finally, FSDP is often used together with activation checkpointing functions like checkpoint_wrapper from FairScale. Users may need to carefully tune the activation checkpointing strategy to fit a large model within limited GPU memory space.
Next steps
FSDP is open source, and early users have tried it and contributed to it. We think it can benefit the entire research community, and we look forward to working with everyone in making it better. In particular, these are some of the important areas.
- Making FSDP more general. So far, FSDP has been used on both NLP and vision models with SGD and Adam optimizers. As newer models and optimizers emerge, FSDP needs to continue supporting them. Being a purely data-parallel training scheme, FSDP has the greatest potential to be general in supporting a wide range of AI algorithms.
- Making FSDP auto-tune. There are many knobs that users can tune today with FSDP for both scaling and performance. We look forward to developing algorithms for auto-tuning both GPU memory usage and training performance.
- In addition to training, more scalable inference and model serving is an important use case that FSDP might need to support.
- Last but not least, refactoring and continuing to modularize FSDP and its core components is equally important to newer and better features.
Try it out and contribute!
FSDP is currently available directly from the FairScale library.
Thanks for sticking with us thus far. Please try FSDP in your research or production work. We would love to hear your feedback, and, as always, pull requests are welcome!








