
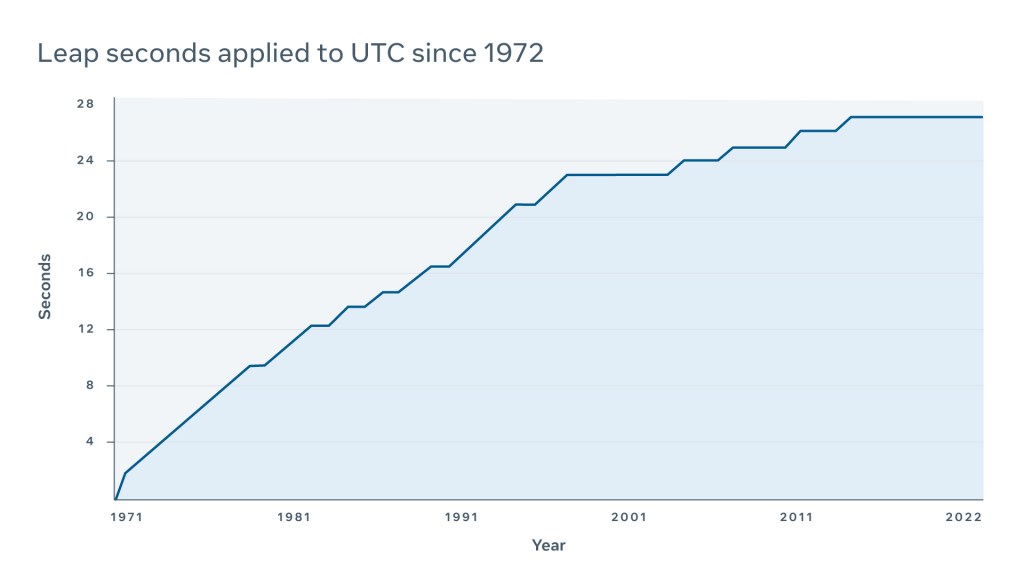
The leap second concept was first introduced in 1972 by the International Earth Rotation and Reference Systems Service (IERS) in an attempt to periodically update Coordinated Universal Time (UTC) due to imprecise observed solar time (UT1) and the long-term slowdown in the Earth’s rotation. This periodic adjustment mainly benefits scientists and astronomers as it allows them to observe celestial bodies using UTC for most purposes. If there were no UTC correction, then adjustments would have to be made to the legacy equipment and software that synchronize to UTC for astronomical observations.
As of today, since the introduction of the leap second, UTC has been updated 27 times.
While the leap second might have been an acceptable solution in 1972, when it made both the scientific community and the telecom industry happy, these days UTC is equally bad for both digital applications and scientists, who often choose TAI or UT1 instead.
At Meta, we’re supporting an industry effort to stop future introductions of leap seconds and stay at a current level of 27. Introducing new leap seconds is a risky practice that does more harm than good, and we believe it is time to introduce new technologies to replace it.
Leap of faith
One of many contributing factors to irregularities in the Earth’s rotation is the constant melting and refreezing of ice caps on the world’s tallest mountains. This phenomenon can be simply visualized by thinking about a spinning figure skater, who manages angular velocity by controlling their arms and hands. As they spread their arms the angular velocity decreases, preserving the skater’s momentum. As soon as the skater tucks their arms back in the angular velocity increases.

So far, only positive leap seconds have been added. In the early days, this was done by simply adding an extra second, resulting in an unusual timestamp:
23:59:59 -> 23:59:60 -> 00:00:00
At best, such a time jump crashed programs or even corrupted data, due to weird timestamps in the data storage.
With the Earth’s rotation pattern changing, it’s very likely that we will get a negative leap second at some point in the future. The timestamp will then look like this:
23:59:58 -> 00:00:00
The impact of a negative leap second has never been tested on a large scale; it could have a devastating effect on the software relying on timers or schedulers.
In any case, every leap second is a major source of pain for people who manage hardware infrastructures.
Smearing
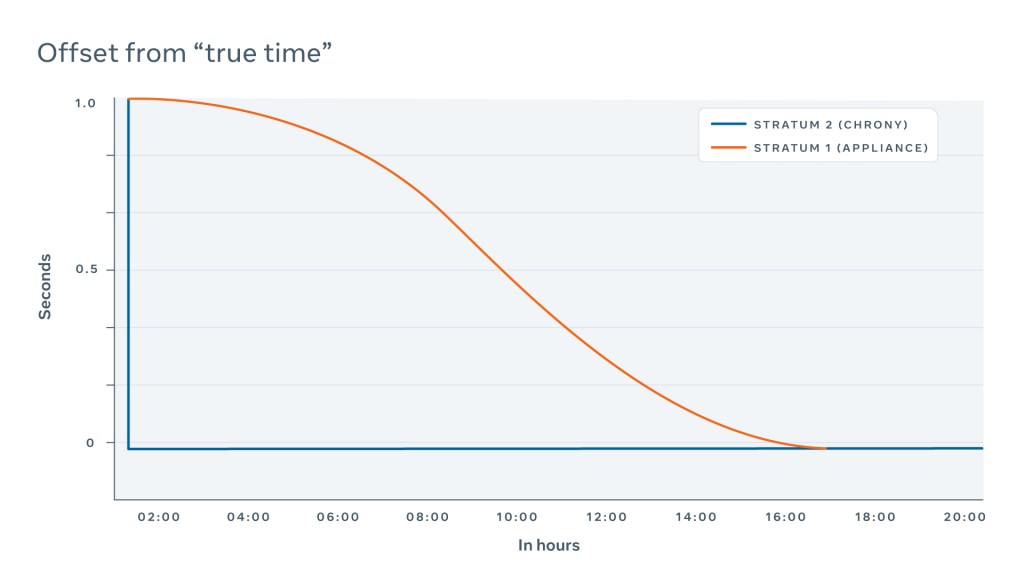
More recently, it has become a common practice to “smear” a leap second by simply slowing down or speeding up the clock. There is no universal way to do this, but at Meta we smear the leap second throughout 17 hours, starting at 00:00:00 UTC based on the time zone data (tzdata) package content.
Let’s break this down a bit.
We chose a 17-hour duration primarily because smearing is happening on Stratum 2, where hundreds of NTP servers perform smearing at the same time. To ensure that the difference between them is tolerable, the steps must be minimal. If the smearing steps are too big, NTP clients may consider some devices faulty and exclude them from quorum, which may lead to an outage.
The starting point at 00:00:00 UTC is also not standardized, and there are many possible options. For example, some companies begin smearing at 12:00:00 UTC the day before and throughout 24 hours; some do so two hours before the event, and others right at the edge.
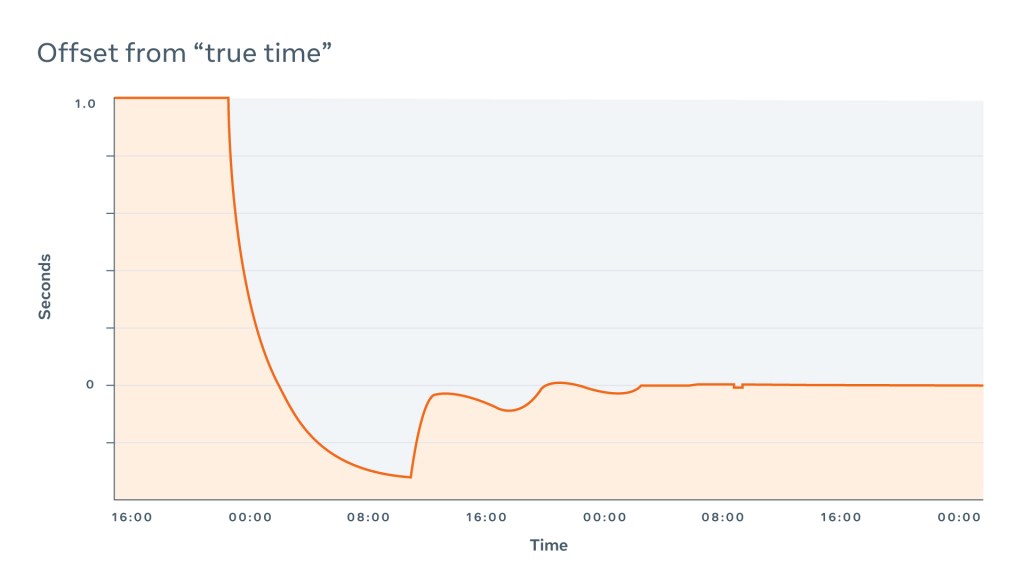
There are also different algorithms on the smearing itself. There is a kernel leap second correction, linear smearing (when equal steps are applied), cosine, and quadratic (which Meta uses). The algorithms are based on different mathematical models and produce different offset graphs:
The source of the leap indicator differs between GNSS constellations (e.g., GPS, GLONASS, Galileo, and BeiDou). In some cases, it is broadcast by satellites several hours in advance. In other cases, time is propagated in UTC with the leap already applied. In different constellations, the leap second value differs depending on when it was launched.
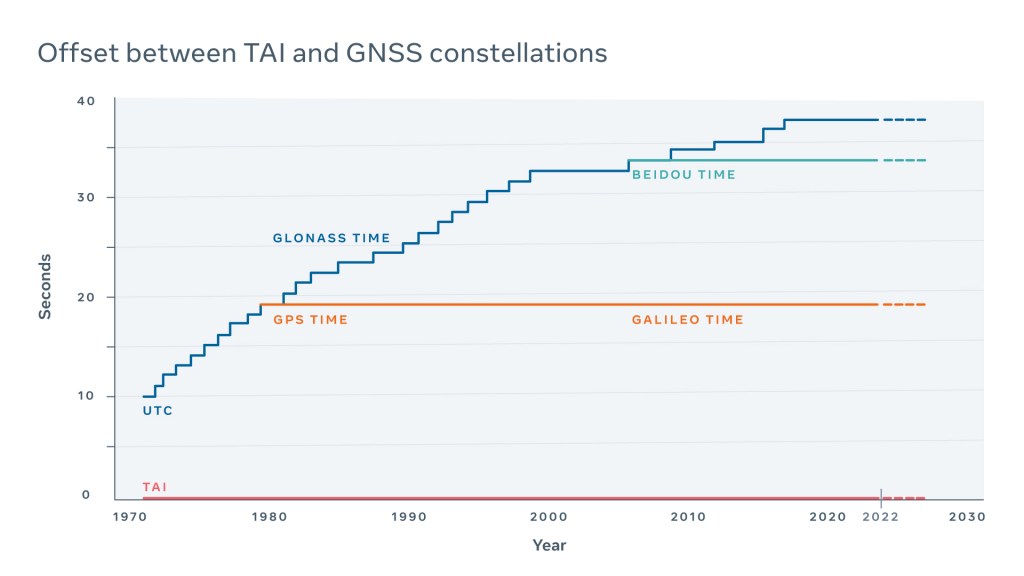
All of this requires the nontrivial conversion logic inside of the time sources, including our very own Time Appliance. Loss of a GNSS signal during such a sensitive time may lead to a loss of a leap indicator and a split-brain situation, which could lead to an outage.
The leap event is also propagated via tzdata package months in advance, and for ntpd fans, via a leap second file distributed through the Internet Engineering Taskforce (IETF) website. Not having a fresh copy of the file may lead to forgetting about a leap second and causing an outage.
As already mentioned, the smearing is a very sensitive moment. If the NTP server is restarted during this period, we will likely end up with either “old” or “new” time, which may propagate to the clients and lead to an outage.
Because of such ambiguities, public NTP pools don’t do smearing, sometimes passing a leap indicator to the clients to figure this out. SNTP clients usually end up stepping the clock and dealing with the consequences described earlier. Smarter clients may choose a default strategy to smear the leap locally. All in all, this means big players like Meta, who perform smearing on public services, can’t join the public pools.
And even after the leap event, things are still at risk. NTP software needs to constantly apply offset compared to the source of time it’s using (GNSS, TAI, or Atomic Clock), and PTP software needs to propagate a so-called UTC offset flag in the announce messages.
The negative impact of leap seconds
The leap second and the offset it creates cause issues all over the industry. One of the simplest ways to cause an outage is to bake in an assumption of time always going forward. Say we have a code like this:
start := time.Now()
// do something
spent := time.Now().Sub(start)
Depending on how spent is used, we may end up in a situation relying on a negative value during a leap second event. Such assumptions have caused numerous outages, and there are plenty of articles that describe these cases.
Back in 2012, Reddit experienced a massive outage because of a leap second; the site was inaccessible for 30 to 40 minutes. This happened when the time change confused the high-resolution timer (hrtimer), sparking hyperactivity on the servers, which locked up the machines’ CPUs.
In 2017, Cloudflare posted a very detailed article about the impact of a leap second on the company’s public DNS. The root cause of the bug that affected their DNS service was the belief that time cannot go backward. The code took the upstream time values and fed them to Go’s rand.Int63n() function. The rand.Int63n() function promptly panicked because the argument was negative, which caused the DNS server to fail.
It’s worth mentioning that Go, in particular, relies on a monotonic clock, and in most cases, is less susceptible to such issues.
Moving beyond the leap second
Leap second events have caused issues across the industry and continue to present many risks. As an industry, we bump into problems whenever a leap second is introduced. And because it’s such a rare event, it devastates the community every time it happens. With a growing demand for clock precision across all industries, the leap second is now causing more damage than good, resulting in disturbances and outages.
As engineers at Meta, we are supporting a larger community push to stop the future introduction of leap seconds and remain at the current level of 27, which we believe will be enough for the next millennium.








