
Within large-scale services, durable storage, distributed leases, and coordination primitives such as distributed locks, semaphores, and events should be strongly consistent. At Meta, we have historically used Apache ZooKeeper as a centralized service for these primitives.
However, as Meta’s workload has scaled, we’ve found ourselves pushing the limits of ZooKeeper’s capabilities. Modifying and tuning ZooKeeper for performance has become a significant pain point. ZooKeeper, a single, tightly integrated monolithic system, couples much of the application state with its consensus protocol, ZooKeeper atomic broadcast (ZAB). Consequently, extending ZooKeeper to work better at scale has proved extremely difficult despite several ambitious initiatives, including native transparent sharding support, weaker consistency models, persistent watch protocol, and server-side synchronization primitives. This inability to safely improve and scale compelled us to pose the question:
Can we construct a more modular, extensible, and performant variant of ZooKeeper?
This led us to construct ZooKeeper on Delos, aka Zelos, which will eventually replace all ZooKeeper clusters in our fleet.
Delos makes building strongly consistent distributed applications simple by abstracting away many of the challenges in distributed consensus and state management. It also provides a clean log and a database-based abstraction for application development. Furthermore, as Delos cleanly separates application logic from consensus, it naturally allows the system to grow and evolve.
However, ZooKeeper doesn’t naturally map itself to the Delos abstractions. For instance, ZooKeeper requires the notion of session management, a notion not present in Delos. Additionally, ZooKeeper provides stronger-than-linearizable semantics within a session (and weaker semantics outside of a session). Further complicating things, ZooKeeper has many uses at Meta, so we need a feature-compatible implementation that can support all legacy use cases and transparently migrate from legacy ZooKeeper to our new Delos-based implementation.
Building Zelos and migrating a complex legacy distributed system like ZooKeeper into our state-of-the-art Delos platform meant we had to solve these challenges.
The Delos distributed system platform
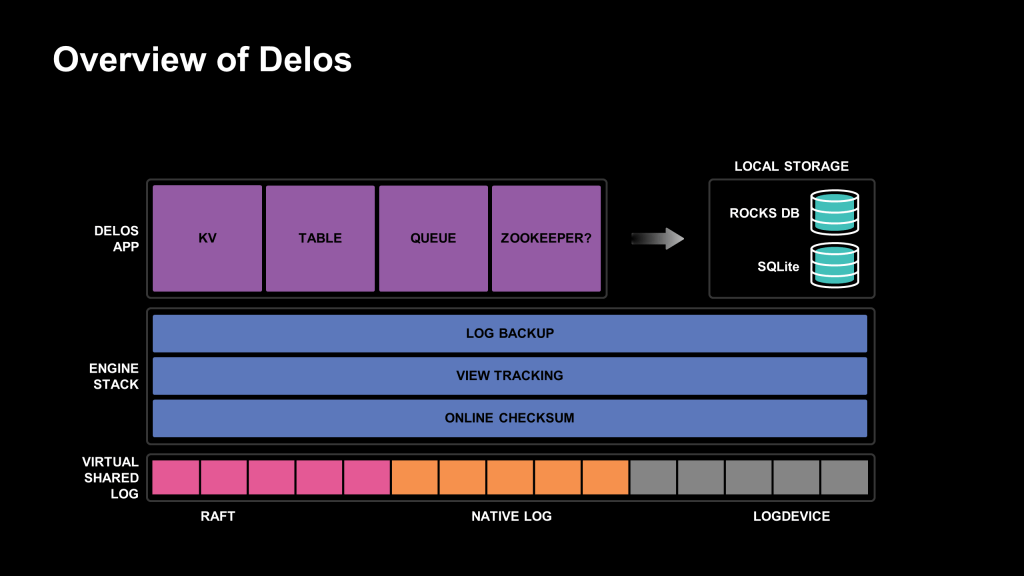
Delos’s goal is to abstract away all the common issues that arise with distributed consensus and provide a simple interface to build distributed applications. This requires Delos applications to worry only about their application logic, and to get Delos’s strong consistency (linearizability) and high availability “for free” when they’re written within the Delos framework. As such, the Delos platform manages numerous problems: state distribution and consensus, failure detection, leader election, distributed state management, ensemble membership management, and recovery from machine faults.
Delos achieves this by abstracting an application into a finite state machine (FSM) replicated across the nodes in the system, often called replicas. A linearizable distributed shared log maintained by the Delos system reflects the state transitions. The replicas of the ensemble then learn these state machine updates in order and apply the updates to their local storage.
As these updates are applied deterministically on all replicas, they guarantee consistency across the replicated state machine. To provide linearizability for reads, a replica first syncs its local storage up to the tail of the shared log and then services the read from its local state. In this way, Delos promises linearizable reads and writes without knowledge of the application’s business logic.
Many applications written on Delos share similar functionality, such as write batching. Delos provides the abstraction of state machine replication engines, or SMREngines. An application selects a stack of these engines based on the features it requires. Each proposal is propagated down the engine stack before it reaches the shared log. The engines may modify the entry as needed for the engine’s logic. Conversely, when a replica learns an entry from the shared log, it gets applied up the stack (in the reverse order of append) so that the engines may transform the entry as needed.
It’s worth noting that the separation of consensus and business logic gives Delos great power in both expanding its capabilities to meet our scale needs and adapting to future changes in distributed consensus technologies. For instance, Delos can dynamically change its shared log implementation without downtime to the underlying application. So if a newer, faster shared log implementation becomes available, Delos can immediately provide that benefit to all applications with no application involvement.
The Delos and ZooKeeper impedance mismatch
At a high level, ZooKeeper maintains an application state that roughly parallels a filesystem. Its znodes act as both files and directories, in that they both store data and hold directory-like links to other znodes. They can also be accessed with a filesystem-like path. This portion of ZooKeeper’s logic can be easily transitioned to Delos since it can be directly represented with a distributed state machine. However, many of the behaviors inside of ZooKeeper that are tightly coupled with its consensus protocol fail to map well to Delos. Foremost among them are ZooKeeper’s session primitives.
In ZooKeeper, all clients initiate communication with the ZooKeeper ensemble through a (global) session. Sessions provide both failure detection and consistency guarantees within the ZooKeeper model. Throughout the lifetime of a session, a client must continuously heartbeat the server to keep its session alive. This allows the server to track live sessions and to keep the session-specific state alive.
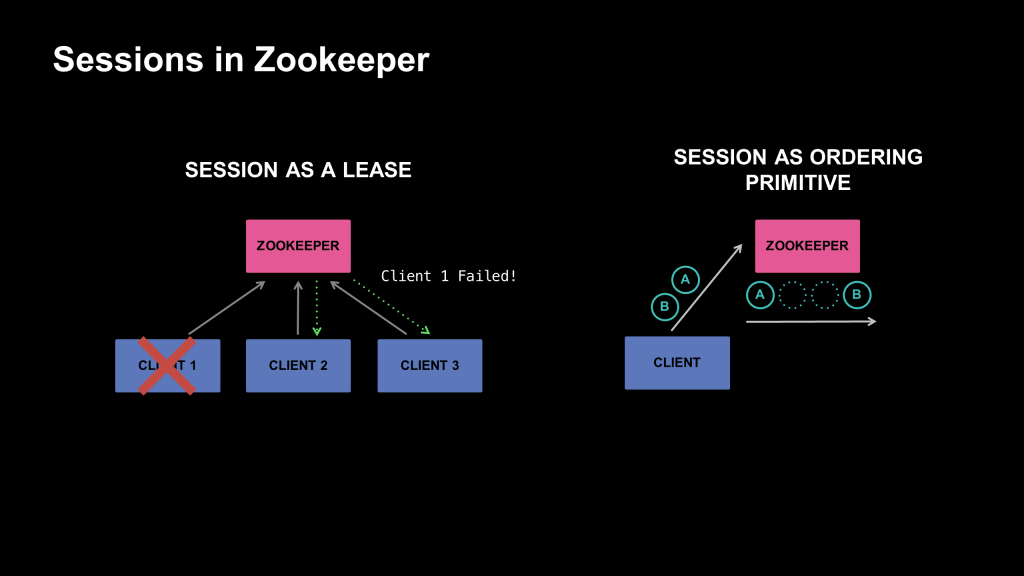
The basis of Delos’s consistency boils down to its linearizable shared log. This guarantees a single linearizable order of all operations, typically sufficient for distributed system needs. However, ZooKeeper provides very strong total ordering within a session and weaker semantics between sessions. As a result, Delos’s linearizable model lacks sufficiency for session operations, as Delos allows proposals to its shared log to be reordered before they reach the log.
Additionally, in some circumstances, ZooKeeper will offer infallible operations (e.g., if A and B are issued to a session, B cannot logically progress unless A succeeds). Delos allows operations to abort for a wide range of reasons, such as network failures or system reconfigurations. Finally, Delos doesn’t provide any real-time primitives, which are required for session lifetime management and used in ZooKeeper’s leader election and failure detection primitives.
To achieve our goal of mapping ZooKeeper to Delos in Zelos, we had to overcome significant impedance mismatches in three primary areas:
- Sessions and strong ordering within a session
- Session-based leases and real-time contracts
- Transparent migration of ZooKeeper-based applications to our Zelos architecture
Mapping ZooKeeper sessions to Delos
Session as ordering primitive
The shared log provided by Delos maintains a linearizable order of log entries once an entry is appended to the log. However, append operations can fail or be reordered while being sent to the log (e.g., from a network issue or a dynamic change of Delos’s configuration). This reordering may break a ZooKeeper session’s total ordering or infallibility properties.
Naively, we could force a session to issue only one command at a time to provide a totally ordered session, but this would be prohibitively slow. Instead, we see that Delos will only rarely reorder appends. So, for most operations issued by a Zelos node, Delos provides total ordering within a session, and only rarely will it break this guarantee.
Using this observation, we propose speculative execution. We speculatively send commands ahead to Delos’s shared log, assuming they will not get reordered. In the rare event that a command is reordered, Zelos will detect the reordering when reading from the log and abort the reordered events. It will then reissue the commands pessimistically. This will guarantee session ordering while preserving parallel append dispatch in the common case.
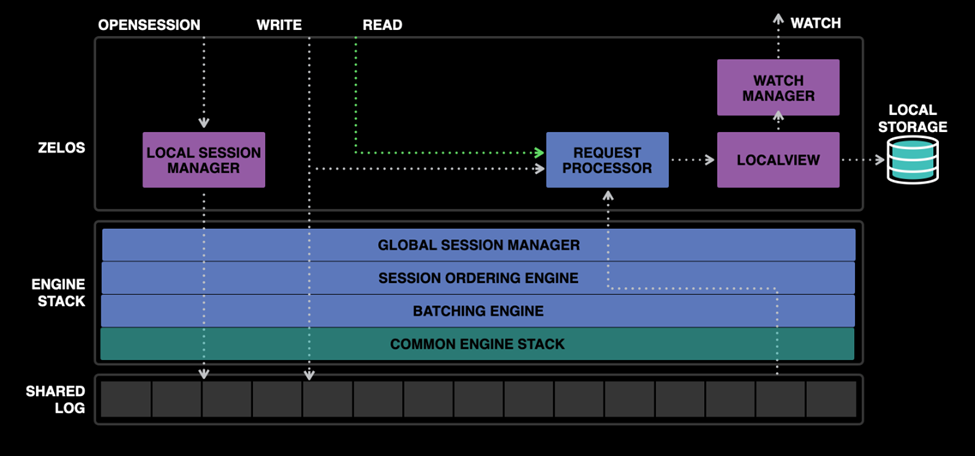
The SessionOrderingEngine within Delos encapsulates this behavior. It provides an infallible stream over the shared log. It does this by tagging each proposal with its node ID and monotonically increasing proposal ID before sending it to the shared log. Once the shared log replicates the proposal, the replicas will apply it and reject any proposal found out of order. The replica that sent the proposal will also learn about this and mark the session as broken.
When the session is broken, the SessionOrderingEngine stops issuing new proposals and waits for any previously appended proposals to apply. Once all the in-flight proposals are applied, it resends any it had to abort due to speculative execution.
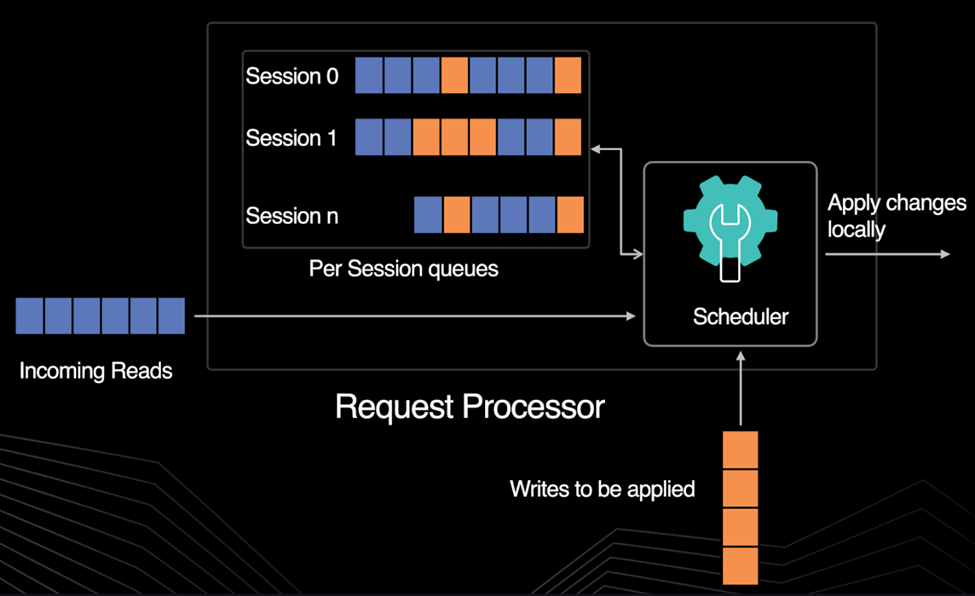
Up to now, we’ve described how the SessionOrderingEngine orders writes. However, ZooKeeper semantics require both reads and writes to be totally ordered within the session. To order reads within Zelos, we block a session’s read until any preceding write is locally applied. Once the write has completed, any reads immediately following that write may proceed. In ZooKeeper and Zelos, reads are only ordered with respect to their session. Consequently, they don’t require a full sync with the shared log but only knowledge of the last write to that session.
We encapsulate this logic within a Zelos layer known as the RequestProcessor, which intercepts all read and write requests and orders them properly with respect to a session. Using lightweight logical snapshots available in Delos, Zelos can dramatically improve read performance by doing only minimal work in the critical path. The RequestProcessor captures a logical snapshot before executing the write. This allows it to perform all dependent reads out of order.
Session as a lease
When a client connects to ZooKeeper for the first time, it establishes a season that it keeps alive by sending periodic heartbeats. Each server is responsible for tracking the last heartbeat it received from every client. ZooKeeper’s leader aggregates this information across the ensemble by periodically contacting all servers. This allows the leader to detect any client that has stopped heartbeating and expire the corresponding session. ZooKeeper also allows for the creation of one or more “ephemeral” nodes, which are automatically deleted when the session that created them is closed. Other clients can “watch” for deletion of the ephemeral nodes created by a particular client to learn about its failure. This mechanism underpins various distributed coordination primitives that ZooKeeper offers.
This protocol allows ZooKeeper to detect client failure as long as the leader itself doesn’t fail. To handle this instance, the set of sessions in the system is replicated using the underlying consensus protocol. Upon leader failure, the system will elect a new leader, which will seamlessly take over session management for the ensemble.
Zelos is unable to directly adopt ZooKeeper’s session management mechanism because it relies on the concept of an ensemble leader, which is a notion that isn’t present in Delos. In Zelos, clients connect directly to replicas, and replicas send messages directly to the shared log. This led us to develop a two-level session management solution, where a client establishes a session with any replica within the ensemble. Once that session is established, the client will continue to communicate with that replica, and it will track the client’s session locally. We call this functionality the Local Session Manager (LSM). Within the LSM, the replica can track client health through client heartbeating and expire sessions just as the ZooKeeper’s leader implementation would.
However, this adds a new failure state. If the replica fails, then its LSM also fails, leaving live clients without a session manager. To handle this, we require an additional replicated Global Session Manager (GSM) layer, a distributed state machine present on each replica. We make session creation and expiration replicated via this state machine as they are in ZooKeeper. In addition, GSM tracks the health of our LSMs and their connected replicas. Just as clients heartbeat replicas, LSMs heartbeat through the shared log, and the GSM monitors these heartbeats. In this way, Zelos’s session management is more efficient than ZooKeeper’s — a single distributed LSM heartbeat represents all sessions serviced by the LSM, while a ZooKeeper leader needs to track heartbeat per session. If an LSM fails, the clients will detect this via heartbeats between the client and LSM. A client may then choose a new replica’s LSM, which will take over the ownership of that session. To manage this transfer, we also ensure that any changes to LSM session ownership are replicated via GSM.
There is one final edge case worth noting: If a client and an LSM fail simultaneously, then the GSM will detect both that the LSM has failed and that the session hasn’t transferred to a new LSM within the session’s preconfigured session timeout. Once these conditions are detected, the GSM will expire the session. In this way, Zelos replicates ZooKeeper’s leader-based session management without relying on consensus-based leader election mechanisms.
The heartbeat protocol used by the GSM is useful for failure detection, however it depends on the notion of time, a well-known challenge in a distributed state machine. While applying a heartbeat log entry, if a replica were to read the system clock, it would highly likely read a different real-time clock value than other replicas in the system. This could result in a divergence of state, where one replica believes another has failed but the other replicas in the system do not, and could result in undesired behavior.
To resolve this, GSM uses a distributed time protocol that approximates real time. We call this protocol TimeKeeper. In building TimeKeeper, we didn’t want to manage the task of having to closely synchronize system clocks (e.g., with a TrueTime-like protocol). Instead, we developed a simpler protocol that allows arbitrary clock skew (deviation from real time) but assumes clock drift to be small over the time interval comparable to maximum session timeout.
The goal of TimeKeeper is to track LSM failures, which in Zelos is too large of a time duration without an LSM heartbeat. To facilitate this, TimeKeeper leverages Delos’s shared log. Each LSM heartbeat is part of a log message and therefore associated with a log position. TimeKeeper protocol measures elapsed time since the last LSM heartbeat by associating a “tick” count between each heartbeating LSM and each TimeKeeper. If this tick count ever surpasses the LSM timeout time, it is declared dead. To associate this tick count, each TimeKeeper replica sends a tick message with its last learned log position at some defined interval. The TimeKeeper protocol tracks both the latest received heartbeat, and the number of tick counts from each TimeKeeper since that heartbeat. If any of the TimeKeeper nodes has ever sent more than the allowed number of ticks (based on the tick interval and timeout duration), then the LSM is considered as failed.
Since building a GSM encapsulates generally useful but nontrivial logic, we have built it as an SMREngine within Delos that can be used by any other Delos application that needs a highly scalable distributed leasing system.
Despite the complexity of distributed session management, by leveraging Delos’s consensus and the engine stack framework, our actual production-proven implementation is only a few hundred lines of code.
Transparent migration of workloads to Zelos
There are infrastructure systems at Meta that use ZooKeeper that would cause outages if they were to suffer any significant downtime. This means that in order to use Zelos in production, we needed a migration plan with no client-observable downtime.
To facilitate this, we leveraged the semantics of ZooKeeper, which allows a session to disconnect for a variety of reasons, such as leader election. By spoofing a ZooKeeper leader election to the client, we could disconnect from a ZooKeeper ensemble and reconnect to a Zelos replica without violating any client-visible ZooKeeper semantics.
However, for this to work, we must guarantee that at the time of transition, we atomically transition all clients and that the Zelos ensemble the client will connect to has the exact same client-visible state as the ZooKeeper ensemble that it’s replacing.
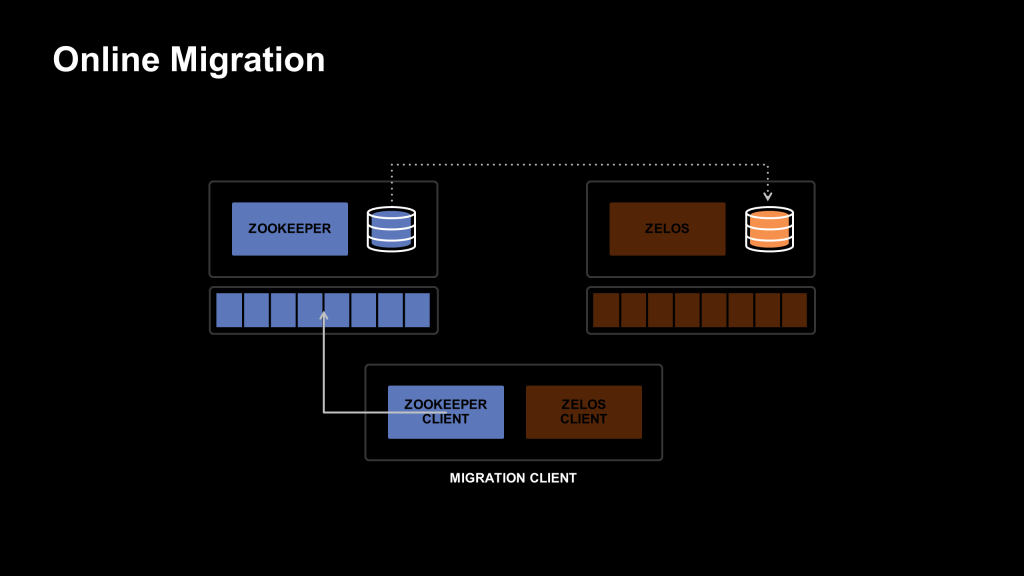
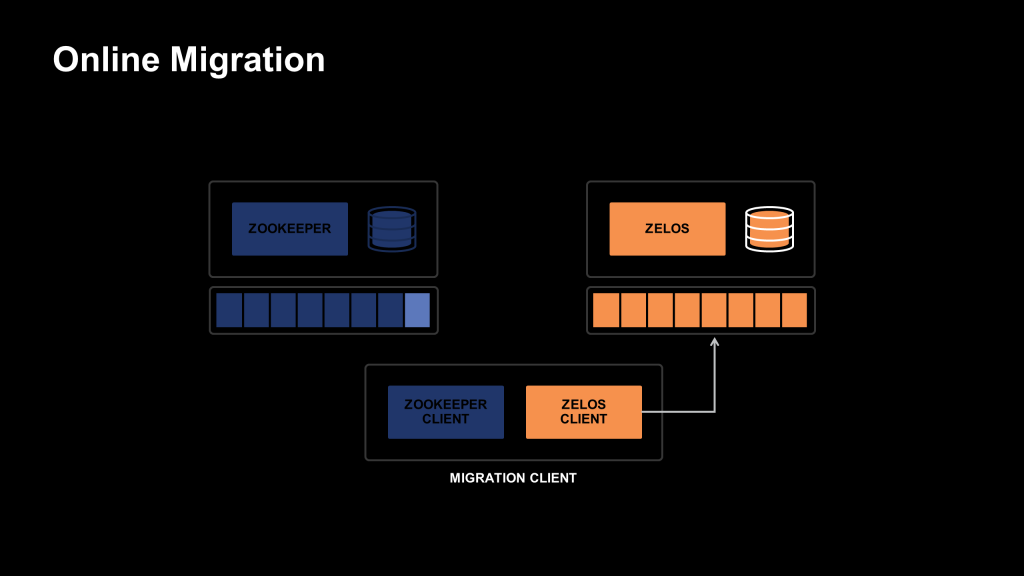
To atomically manage this transition of state, we set up the new Zelos ensemble as a follower of the ZooKeeper ensemble. While in follower mode, the Zelos ensemble does not service a Delos workload but instead observes ZooKeeper’s ZAB-replicated consensus protocol and applies all the ZooKeeper state updates directly to the Zelos on-disk state.
We then define a new, special node in the ZooKeeper tree that we call the barrier node. We based the atomic switch and the illusion we create for the client on this barrier node. The barrier node serves two purposes. First, it notifies the Zelos ensemble that it’s time to transition and converts the ensemble from a follower of ZooKeeper to the leader of its own consensus protocol.
Second, the creation of the barrier node is a trigger to transfer our client. We created a new client that wrapped the ZooKeeper client and the Zelos client and knew what the barrier node meant. On startup, it connects to ZooKeeper and creates a watch on the existence of this barrier node. Once the barrier node is observed by the client, it disconnects from the ZooKeeper ensemble, pretending a “leader election” is occurring. It then connects to the Zelos ensemble and confirms that the ensemble has observed the creation of the barrier node. If the Zelos ensemble has observed the barrier node, its state is at least as up to date as the ZooKeeper ensemble at the time of migration, and can serve the same traffic the ZooKeeper ensemble would.
We have used this process to successfully migrate 50 percent of our ZooKeeper workloads to Zelos with zero downtime across various use cases.
Next steps for Zelos
Building a ZooKeeper API using Delos gives us the flexibility to change the semantics of ZooKeeper without doing a major redesign. For example, while migrating use cases, we realized that most of them really do not care about the ordering semantics provided by the session. For such use cases, we could significantly improve the throughput of the ensemble. We did so by removing the session-ordered engine from the stack and highly simplifying the request processor.
Many of our internal teams that use ZooKeeper have grown out of a single ensemble and have had to split their use case into multiple ensembles and maintain their own mapping of ensembles. We plan to extend the Delos platform to provide building blocks for sharding, allowing a single, logical Zelos namespace to map to many physical ensembles. This mechanism will be common across all Delos-powered apps, so Zelos can take advantage of it out of the box. While this work will be challenging, we are most excited about the potential here.








