
Data minimization — collecting the minimum amount of data required to support our services — is one of our core principles at Meta as we continue developing new privacy-enhancing technologies (PETs). We are constantly seeking ways to improve privacy and protect user data on our family of products. Previously, we’ve approached data minimization by exploring methods of de-identifying or aggregating data by post-processing it. However, this is a reactive approach to data minimization that can become very resource-intensive at Meta’s scale.
As we searched for a more scalable solution, we discovered we can leverage de-identified authentication to act proactively rather than reactively. In doing so, we can de-identify information at its source.
In any client-server interaction, authentication helps protect against scraping, spamming, or DDOS attacks of our endpoints. For the authentication mechanism, utilizing user ID is a broadly adopted practice across the industry to authenticate clients before serving or receiving traffic.
But we want to raise the privacy bar higher by de-identifying users while still maintaining a form of authentication to protect users and our services. So, we leveraged the anonymous credential, collaboratively designed over the years between industry and academia, to create a core service called Anonymous Credential Service (ACS). ACS is a highly available, multitenant service that allows clients to authenticate in a de-identified manner. It enhances privacy and security while also being compute-conscious. ACS is one the newest additions to our PETs portfolio and is currently in use across several high-volume use cases at Meta.
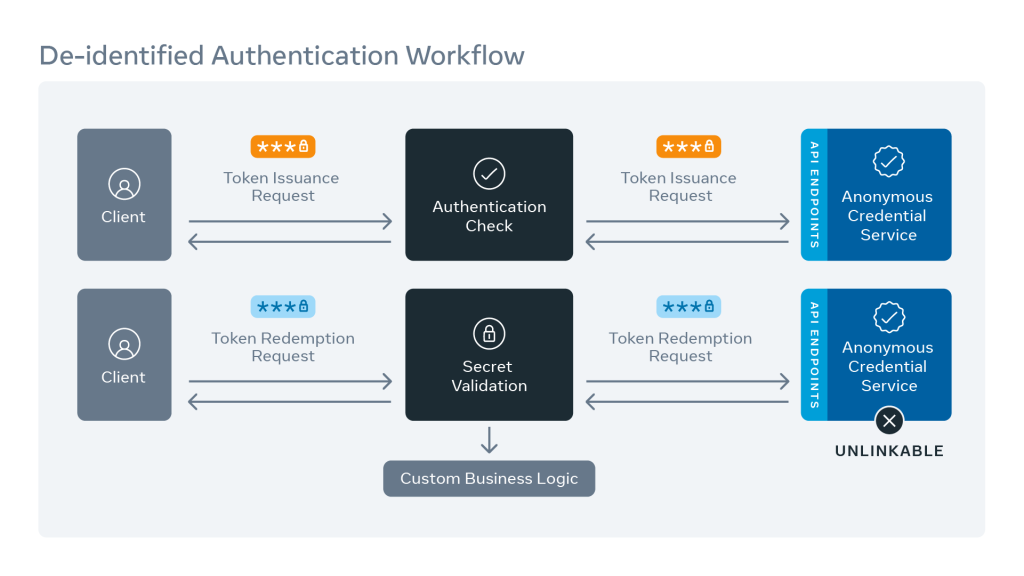
How anonymous credentials support de-identified authentication
At a high level, anonymous credentials support de-identified authentication by splitting authentication into two phases — token issuance and de-identified authentication. In the token issuance phase, clients contact the server through an authenticated channel to send a token. The server signs and sends it back. Then, in the de-identified authentication (or token redemption) phase, clients use an anonymous channel to submit data and authenticate it utilizing a mutated form of this token rather than a user ID.
We’ve greatly simplified the nuances in the protocol. The signed token (token issuance phase) and redeemed token (de-identified authentication phase) cannot be linked. This property enables the server to authenticate the client in the second phase without knowing which specific client the token belongs to, thus preserving user privacy.
How the anonymous credentials protocol works
Let’s take a deeper dive into the protocol. Anonymous credentials are built on top of VOPRFs (verifiable oblivious pseudorandom functions, which enable clients to learn verifiable pseudorandom function evaluations on custom inputs) and blind signatures (a type of digital signature that prevents the signer from knowing the sender’s message contents). For the full workflow, we have a setup phase in addition to the token issuance phase and de-identified authentication phase mentioned previously.
In the setup phase, the client obtains the server’s public key and other public parameters. Next comes the token issuance phase where the client creates a random token and picks a blinding factor. It then blinds the token and sends it to the server. The server, in turn, signs the token and sends it back. The client then performs an unblind operation on the signed blinded token response. It also computes a shared_secret, essentially a function of the original token and the server signature.
Note that at this point, the server has never seen the value of the original token. Later, in the de-identified authentication phase, the client forwards the original token, the relevant business data, and an HMAC of the business data with the shared_secret. The server can then essentially verify that the shared_secret sent by the client is the same as a locally computed shared_secret by checking this HMAC. If this check passes, the server accepts the request as legitimate and processes the business data. For further details on the protocol, please refer to the paper “De-identified authenticated telemetry at scale.”
Real-world use cases of de-identified authentication
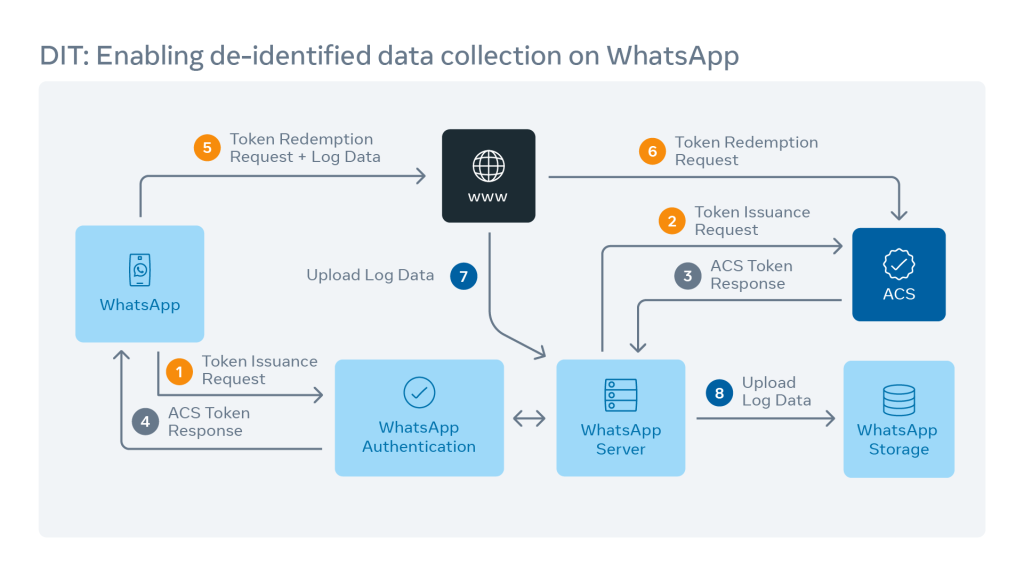
De-identified Telemetry on WhatsApp
ACS enables clients to authenticate in a de-identified manner. By eliminating user ID in authentication through ACS, we can preserve user privacy while meeting our data collection minimization goals. In order to service production use cases, we had to create a robust architecture and bake in resilience to a wide variety of real-world problems.
De-identified Telemetry (DIT) on WhatsApp is one use case that currently leverages ACS. In the past, we utilized secure storage along with data deletion policies to ensure that log data could never be associated with users. But we wanted to go further with our privacy protection measures and integrated ACS with WhatsApp’s systems to enable de-identified authentication for certain WhatsApp client-side logs. Deployed at scale, DIT enables WhatsApp to report performance metrics (important for helping ensure a snappy, crash-free app for everyone) without needing to collect identity when authenticating log requests. Since it gets used across our entire WhatsApp family, this massive use case requires ACS to serve hundreds of thousands of requests per second.
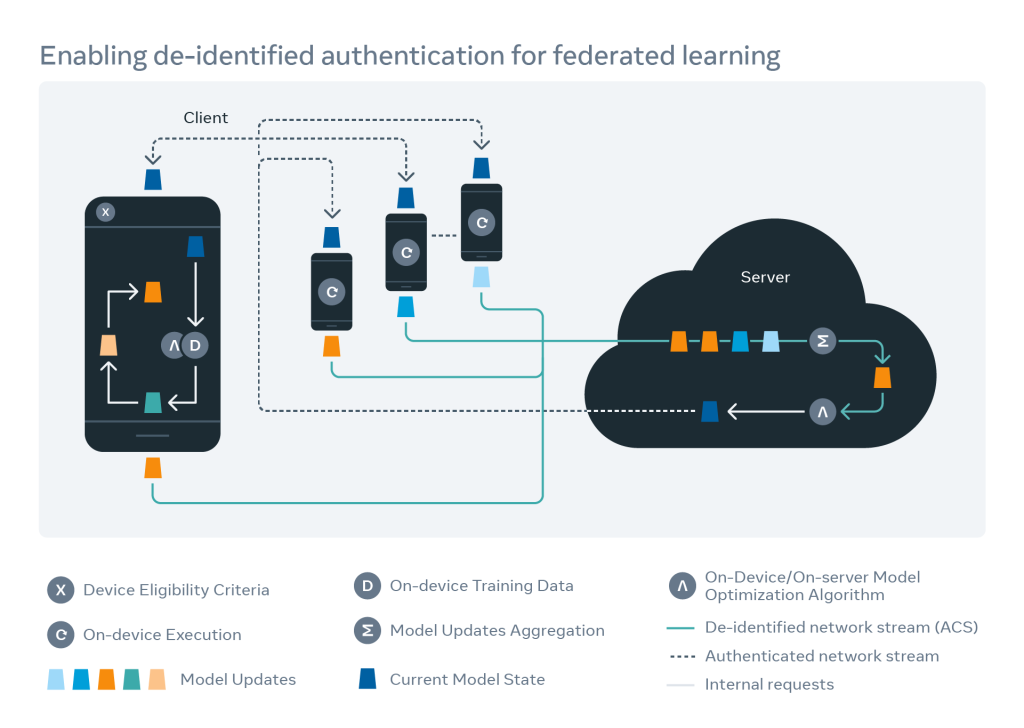
Federated learning
Another use case we’d like to highlight is federated learning, a technique in which we are able to train a global machine learning model while keeping private, sensitive data locally on client devices. In this paradigm, devices share model updates with the server instead of raw sensitive data, and the servers compute aggregated model updates and optimize the global model.
This is a potential avenue where ACS could be used to further preserve user privacy. We don’t want malicious actors to send fraudulent model updates, but we want to ensure that legitimate users can help improve the global model. By leveraging ACS, we can ensure that legitimate clients send the client model updates in a de-identified manner.
The ACS architecture
Now let’s dive into architecture. ACS is a C++ service developed on top of Twine, Meta’s container orchestration framework. Traffic gets load balanced across our global regions, while each region dynamically scales up and down based on demand. ACS provides Thrift APIs for token issuance and token redemption.
Providing ACS token scope isolation between different use cases becomes an important requirement. Why? We are multitenant and serve a variety of use cases. And different use cases may have different authentication mechanisms (e.g., Facebook users vs. Instagram users). An ACS token issued for a specific use case should not be allowed to be redeemed for a different use case.
To solve this problem, we require each API request to specify a use case name and provide separation by utilizing use case–specific key materials. We routinely rotate our security keys by leveraging Meta’s asynchronous job infrastructure and storing key materials in Meta’s keychain service. Additionally, we have another job that publishes updated ACS public keys after key rotations so clients can fetch updated keys.
Lessons learned while scaling ACS
While scaling up ACS, we learned three key lessons for maintaining the reliability and efficiency of our service: Prevent the cost of running ACS from growing linearly with the amount of traffic, avoid artificial traffic spikes, and facilitate adoption without requiring dedicated expert knowledge.
As we onboarded more and more use cases, we noticed that we had to acquire new hosts and more server capacity on a 1:1 ratio with newly onboarded traffic. Given the recent supply chain crunch affecting servers worldwide, we explored how we could streamline ACS and make it more practical while still maintaining our high privacy bar.
We decided to allow use cases to specify a credential reuse limit within a reasonable threshold. On the ACS server, we added a credential reuse counter (backed by ZippyDB, Meta’s distributed key-value store) that would count how many times a specific ACS token has been redeemed and fail the request if a token has been over-redeemed. More sensitive use cases have a redeem limit of one (i.e., no token reuse). By allowing for credential reuse, we can issue fewer tokens to service a particular use case and save on server capacity as a result.
Another key scaling lesson we learned involved traffic spikes. After observing our service dashboards, we noticed short periods when the ACS server received a large spike of requests. This would cause our servers to be momentarily overwhelmed and fail a certain portion of requests. We noticed these spiky requests were originating from one of our large use cases. After talking with the relevant client teams, we learned that their implementation cached data on the mobile client and sent batched requests at the same time every night.
Although this was a great idea in theory, we learned that this model was effectively DDOSing our server since many requests were being sent suddenly at the same time. To address this problem for this particular use case, we added dithering to spread out the requests so they weren’t all sent at the exact same time. To solve this problem more generally, and to protect our server health, we worked with Meta traffic teams to add a global rate limiter that would selectively drop ACS traffic if it exceeded a certain rate threshold.
A final challenge we encountered while scaling up ACS was on the engineering side. Initially, we had a small team working on ACS and found it difficult to onboard new use cases. At the time, onboarding new use cases usually entailed one of us working very closely with the partner team to explain key ACS concepts and manually provisioning a new ACS use case on our server.
We decided to ease this overhead by creating a low-friction onboarding experience for new ACS use cases. We built a self-service onboarding portal in React, and now engineers from across Meta can use the portal as a one-stop shop for everything ACS. Additionally, we created ACS client SDKs in Android and iOS to provide quality crypto primitives and protocol implementation. Clients can call high-level methods such as “fetch-acs-token.” These take care of the entire token exchange protocol by contacting ACS service APIs, unblinding tokens, and performing any other involved operations. We also revamped our onboarding wiki and invested in codegen tools. This further made it easier for clients to integrate with us while writing minimal code. It also let them use our protocol without needing expert-level cryptography knowledge.
Better privacy protections for everyone
De-identification is an important tool for safeguarding data and preserving privacy. Sharing and safeguarding data demands trust and responsibility. Moving forward, we hope to integrate ACS even further into Meta’s data infrastructure and to further preserve data privacy by implementing it into our products beyond authentication use cases.
We hope our work can inspire more privacy-enhancing technologies across the industry.








