")
At Meta, our Bug Bounty program is an important element of our “defense-in-depth” approach to security. Our internal product security teams investigate every bug submission to assess its maximum potential impact so that we can always reward external researchers based on both the bug they found and our further internal research assessment of where else the bug could lead us.
We want to share more about how this process works. To do this, we’re sharing details of an investigation into a bug report we received in August 2020 concerning Hermes, an open source JavaScript (JS) engine developed by Meta. This initial report showed a peculiar bug in Hermes’s Quicksort implementation, resulting in blind out-of-bounds (OOB) memory reads.
Reports like this help us continue to improve our detection mechanisms in Hermes and across our platform. Similar findings are usually awarded between $500 and $3,000. However, further investigation demonstrated how this vulnerability could have been turned into arbitrary code execution. This resulted in a $12,000 total bounty payout.
To make things more fun, and to demonstrate the impact of what we found, we programmed our exploit to run the classic video game Doom (1993) directly from within Hermes.
Hermes, a lightweight JavaScript engine
Hermes is an open source JS engine optimized for React Native. It features ahead-of-time compilation to reduce startup time and memory usage, making it particularly suitable for mobile applications. At Meta, for example, Hermes is used to run the JS code for effects in Spark AR, our augmented reality development platform. In July 2020, we launched the Hermes/Spark AR track to further incentivize security research on Hermes.
The bug, sorting the unsortable
In August, 2020, we received a report showing a crash in Hermes caused by an OOB read. The report featured a tangled JS file of about 180 lines of code, most likely created by a fuzzing engine. After some cleanup, we pinpointed the root cause.
The crash occurred while executing the Array.prototype.sort method, in code related to some recent changes to make Hermes’s sort implementation stable. A sorting algorithm is said to be stable if the order of equal elements remains the same after sorting.
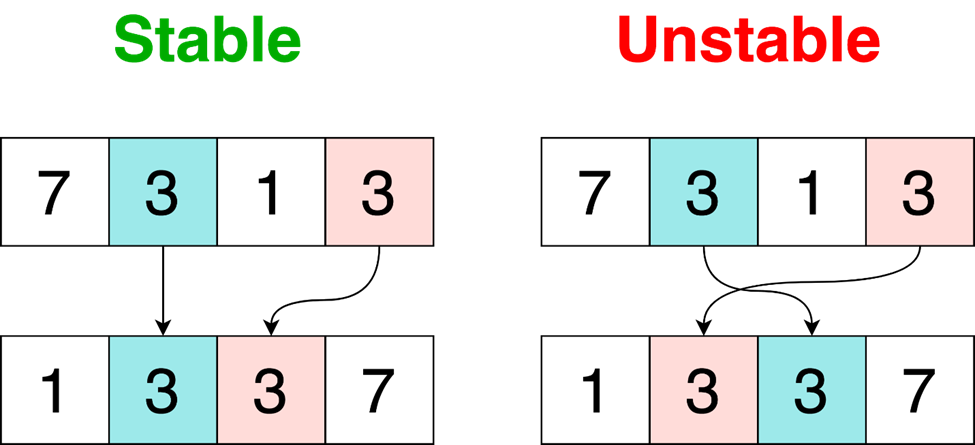
In Hermes, this was achieved by using a separate index vector prefilled with the element’s original indices [1] (see code comments). Whenever two elements in the array are swapped, their indices are swapped as well [2]. If two array elements are equal, their original indices’ values are compared instead [3]. This guarantees stability.
ExecutionStatus quickSort(SortModel *sm, uint32_t begin, uint32_t end) {
uint32_t len = end - begin;
// [1]
std::vector<uint32_t> index(len); // Array of original indices of items
for (uint32_t i = 0; i < len; ++i) {
index[i] = i;
}
...
return doQuickSort(sm, index, /* ... */ );
}
...
ExecutionStatus
_swap(SortModel *sm, std::vector<uint32_t> &index, uint32_t i, uint32_t j) {
if (sm->swap(i, j) == ExecutionStatus::EXCEPTION) {
return ExecutionStatus::EXCEPTION;
}
// [2]
std::swap(index[i], index[j]);
...
}
...
CallResult<bool>
_less(SortModel *sm, std::vector<uint32_t> &index, uint32_t i, uint32_t j) {
auto res = sm->compare(i, j);
if (res == ExecutionStatus::EXCEPTION) {
return ExecutionStatus::EXCEPTION;
}
// [3]
return (*res != 0) ? (*res < 0) : (index[i] < index[j]);
}
Array.prototype.sort can take, as an argument, a function defining a custom sort order:
const array = [3,1,4,2];
array.sort(function compareFn(first, second) { ... });
But what happens if we use this callback to modify the array while sorting? When sort is first called, it will use the initial version of the array, but after executing the comparison function, sort will see the modified version.
On the other hand, index , whose length reflects the initial array’s size, remains unchanged. As a result, the array and index length might differ. This might happen, for example, if new elements are added to the array from within the callback.
In this case, accessing elements beyond the original array’s size during sorting will result in OOB accesses in index.
Understanding the Quicksort algorithm
To understand how to control which elements get accessed, we need to understand the underlying Quicksort algorithm.
Quicksort starts by selecting a pivot element, picked to be the median of three elements. It then searches for an element larger than pivot (as reported by the callback function) from left to right (i). Once this larger element is found, the algorithm looks for an element smaller than pivot from right to left (j). Those elements are then swapped and the procedure is repeated until the two searches “cross each other,” at which point the pivot is swapped with the smaller element (j).
Causing an OOB read
Now, let’s put everything together and use the callback to trick the sorting algorithm implementation into sorting elements beyond the original array:
- We start by extending the array beyond its original size (so to be larger than index).
- We then wait to get past the median-of-three step (used to select a pivot), which requires three comparisons.
- At this point, we keep returning -1 to advance the left index i until we have reached the target cell past the original array’s size.
- Finally, we return 0, indicating that the two elements are equal. This will cause an OOB read to the index buffer.
var array = [1,2,3,4,5,6,7,8,9,10];
const initial_length = array.length
const extended_length = initial_length*2
var cnt = 0
array.sort(function compareFn(first, second) {
cnt++;
// [1] Extend the array
if (cnt == 1){
for (i=0; i<extended_length-initial_length; i++){
array.push('X')
}
}
// [2] Get past the median-of-three step
if (cnt > 3){
// i represents the left index moving to the right
const i = cnt - 1;
// target_cell can be anything between initial_length and extended_length
const target_cell = 15;
if (i != target_cell){
// [3] If we didn't yet reach the target cell, keep advancing
return -1;
} else {
// [4] If we did reach the target cell, trigger an OOB index lookup
print("Look for the crash...")
return 0;
}
}
});Executing the above code on an ASAN build of Hermes produced the following crash:
Look for the crash... ================================================================= ==1519183==ERROR: AddressSanitizer: heap-buffer-overflow ... READ of size 4 at 0x604000003fc8 thread T0 SCARINESS: 27 (4-byte-read-heap-buffer-overflow-far-from-bounds) #0 0xcd011a in hermes::vm::_less(...) hermes/lib/VM/JSLib/Sorting.cpp:35 #1 0xccf3de in hermes::vm::quickSortPartition(...) hermes/lib/VM/JSLib/Sorting.cpp:175 #2 0xccf3de in hermes::vm::doQuickSort(...) hermes/lib/VM/JSLib/Sorting.cpp:262 #3 0xccef6e in hermes::vm::quickSort(...) hermes/lib/VM/JSLib/Sorting.cpp:332 #4 0x953f41 in hermes::vm::arrayPrototypeSort(...) hermes/lib/VM/JSLib/Array.cpp:1248 #5 0x8b3ee9 in hermes::vm::NativeFunction::_nativeCall(...) hermes/include/hermes/VM/Callable.h:539 #6 0xa27a2f in hermes::vm::Interpreter::handleCallSlowPath(...) hermes/lib/VM/Interpreter.cpp:318 ...
Let the hacking begin
After understanding the root cause of a bug, we immediately work with the relevant product/feature development team to issue a fix. In the meantime, we always ask ourselves, “How serious is this?” and work to determine the bug’s maximum potential impact.
So, how serious was this Hermes bug? We have seen how it could be used to access elements beyond index, but could it have been used to obtain something more than a crash?
Swapping the unswappable
Quicksort works by swapping elements and, when two elements are swapped, their respective indices are also swapped. Therefore, at least in theory, this bug might be used to swap indices with neighboring elements outside the index vector.
If so, we could obtain the ability to do some loosely controlled writes out of the index.
There are two types of swaps in Quicksort:
- Between i and j
- Between j and the pivot
We decided to look at the first option since the sorting algorithm lets us control both i and j:
while (true) {
// [1]
while (true) {
++i;
res = _less(sm, index, i, pivot);
if (res == ExecutionStatus::EXCEPTION) {
return ExecutionStatus::EXCEPTION;
}
if (!*res) {
break;
}
}
// [2]
while (true) {
--j;
res = _less(sm, index, pivot, j);
if (res == ExecutionStatus::EXCEPTION) {
return ExecutionStatus::EXCEPTION;
}
if (!*res) {
break;
}
}
// [3]
if (i >= j) {
break;
}
// [4]
if (_swap(sm, index, i, j) == ExecutionStatus::EXCEPTION) {
return ExecutionStatus::EXCEPTION;
}
}The swap [4] happens once i is pointing to an element smaller than pivot [1] and j is pointing to an element larger than pivot [2].
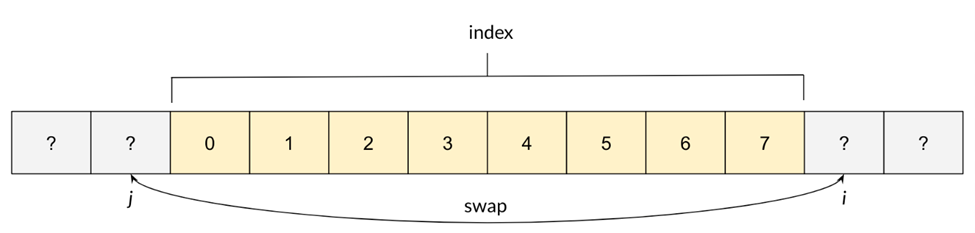
An intermediate check [3] ensures that i and j are swapped only if they haven’t crossed each other (i.e., i < j ), but in order to swap elements out of the index, i and j must cross.
To solve that, we decided to underflow j (a 32-bit unsigned integer) so that j = 0xffffffff.
In a 32-bit system, index[0xffffffff] is equivalent to index[-1], which corresponds to the element immediately before the index.
Unfortunately, reading j = 0xffffffff will cause the application to hang in the loop at [2]. This is because array[0xffffffff] is “empty,” which, according to the specs, is considered to be greater than everything. As a result, the loop searching for an element smaller than the pivot will keep looping until the whole 32-bit address space has been explored.
To solve for this we defined a custom getter so that array[0xffffffff]will not return an empty element.
Array.prototype.__defineGetter__(0xffffffff, ...);
At this point, we were able to swap index[j] and index[i], where j = 0xffffffff. Notice that we can also arbitrarily decrement j and/or increment i, as long as i < j.
Control what you read, control what you write
We have limited control over the content of the index, so we decided to focus on swapping content in nearby memory.
The index is an instance of std::vector, and its underlying memory is allocated via malloc. If we could somehow create a memory layout where we control the content before or after the index, then we would be able to control what we write during a swap.
An easy way to control the memory layout of malloc allocations is to use mmap’d allocations. For large enough allocations, malloc will use mmap to require more memory from the system. When mapping new memory via mmap, the Linux kernel will try to expand known mapped memory and return adjacent regions. We can exploit this logic to place individual allocations alongside.
Most data structures in Hermes don’t use malloc directly but instead rely on the Hermes Garbage Collector (GC) to allocate memory. However, Hermes’s implementation of ArrayBuffer uses malloc to allocate their underlying data buffer.
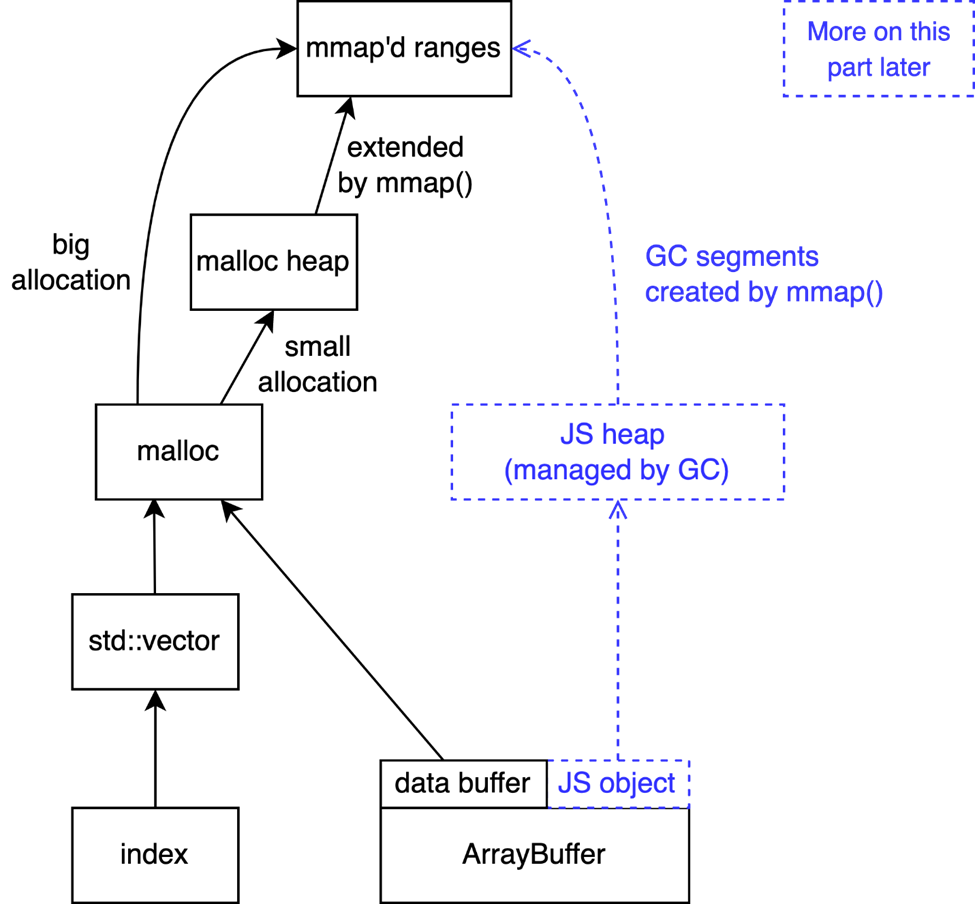
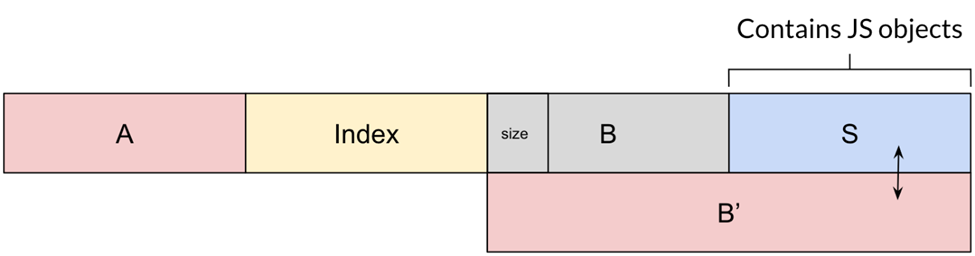
For our exploit, we crafted this strategic memory layout:
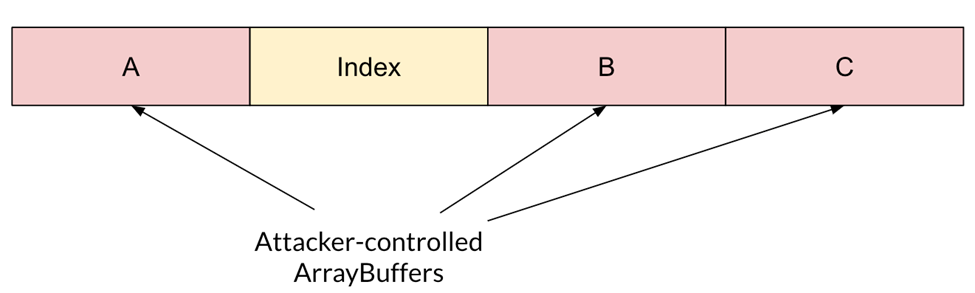
To obtain it, we first created two ArrayBuffers (C and B), started sorting (thus creating the index), and finally created a third ArrayBuffer (A) from within the callback. Here, A, B, and C are the data buffers of ArrayBuffers that we control.
Using our swapping capabilities, we can now swap elements of A with elements of B or C.
Obtaining arbitrary reads and writes
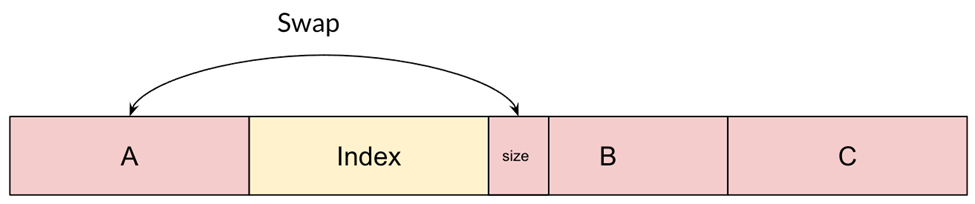
Memory chunks allocated via malloc embed extra metadata, which, for instance, contains the size of the allocated region.
All our memory regions (A, Index, B, and C) are contained in separate malloc chunks, each having its own header and metadata.
What would happen if we swapped the size of a malloc chunk with another value?
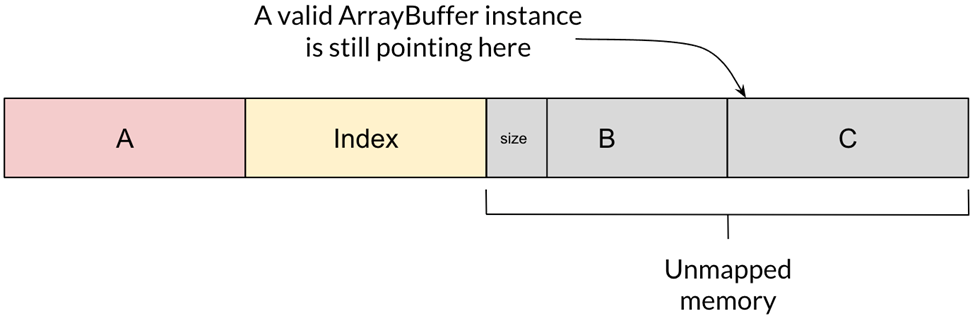
Swapping the size of a chunk with another value leads to some interesting results. For example, if we write a size large enough to contain both B and C and delete B’s ArrayBuffer instance (thus causing its memory to be freed), then the memory of both B and C will be unmapped. However, since we never deleted C’s ArrayBuffer instance, it would still be pointing to the memory (which is now invalid).
But look what happens if we allocate a new ArrayBuffer, B’, with a size matching the newly unmapped region:
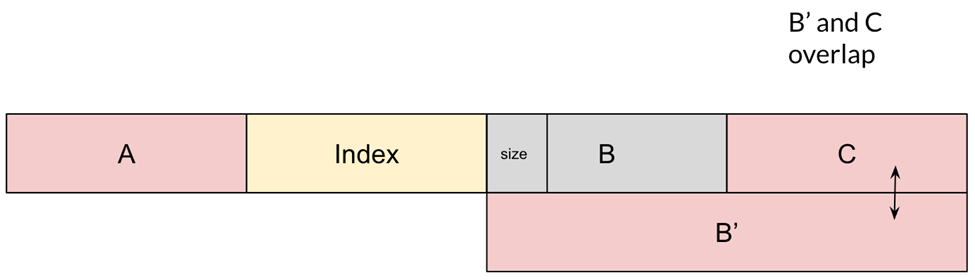
The system will reallocate the unmapped region for B’, and, as a result, B’ and C will overlap. Obtaining overlapping chunks is a well-known heap exploitation technique and can be often used to obtain more powerful capabilities, such as arbitrary reads or writes.
In this setting, we can control the content of C from B’. To obtain read/write capabilities, we can repurpose region C to host “something” containing memory addresses, so that from B’ we could change these to any arbitrary address.
There is a way we can get internal data structures for JS objects allocated inside C. More specifically, we can do this by using the Hermes GC. The GC is responsible for releasing or allocating memory for Hermes objects. At the time of the report, the default GC was GenGC, and, as outlined in the GenGC documentation, the space allocated by this GC:
“… is made out of many fixed-size regions of memory known as segments. Currently these segments are 4 MiB … Memory is acquired and released on a per-segment basis. Segments are allocated using mmap …”
If we free C and create enough JS objects, the GC will need to allocate an extra segment (to host the new objects). The new segment will be placed in C’s place (assuming C is at least 4 MiB in size).
In essence, we are taking the memory previously used to hold the content of ArrayBuffer C and get Hermes to reuse it for a JS heap segment (remember the dotted section of our earlier diagram?). While doing so, we are maintaining read/write (RW) access to the segment via B’.
Now we can overwrite the content of the segment S from B’.
GC segments contain plenty of JS object instances, including ArrayBuffer objects. If we spray enough ArrayBuffers, some of them will be placed in the new segment:
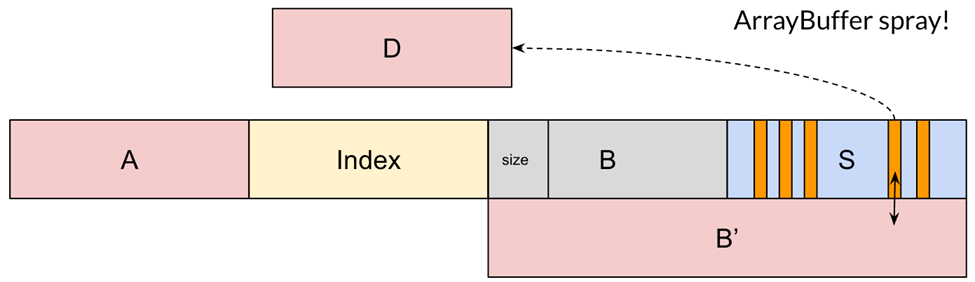
To summarize, we got Hermes to reuse C’s memory to host the “metadata” of several other ArrayBuffers. This was possible because ArrayBuffers’ contents and JS object metadata are both ultimately backed by mmap (see our earlier diagram).
Each ArrayBuffer object contains a pointer to the underlying data buffer (i.e., its content).
Using B’, we can change the address in a chosen instance and make it point anywhere in memory instead of to their original buffer (D in the image). Then, by reading or writing to that ArrayBuffer instance, we can read or write at any arbitrary address!
Putting it all together
We came a long way from a mysterious crash in Array.prototype.sort to obtaining unlimited R/W capabilities.
To summarize:
- We created a strategic memory layout of four adjacent mmap’d buffers.
- We used the sorting bug to swap the size of a malloc chunk and obtain two overlapping ArrayBuffers.
- Finally, we replaced one of the overlapping buffers with a GC segment so that we could overwrite pointers and obtain arbitrary R/W access.
A typical exploit flow would continue as follows:
- Write an ROP-chain and shellcode somewhere in memory.
- Leak some addresses to defeat ASLR.
- Overwrite function pointer with a stack pivoting gadget.
- Execute ROP-chain and make shellcode executable.
- Jump to shellcode.
- Profit.
We will not cover the details of the remaining steps, as they refer to well-known exploitation techniques. The final result lets us execute arbitrary code directly from Hermes and escape the JS sandbox.
To make things more fun, we used our exploit to run Doom:
Conclusion
Thanks to our bug bounty researcher’s quick find and report (within six days of the bug being introduced!) and the team’s work on it, this bug wasn’t included in any Hermes public releases.
Based on our internal investigation, we awarded the researcher with a $12,000 bounty. While we always perform an in-depth investigation of each bug submission, we strongly encourage researchers to dive deeper in our native products. On that note, we award bonuses to reports that feature a full proof of concept.
This and other reports were submitted within the context of our Hermes and SparkAR bug bounty track, which incentivizes security research on these products.

Since this bug was reported, we have improved our internal fuzzing effort to help find bugs earlier on, and we are currently working on hardening measures that would drastically diminish the impact of similar bugs.
We encourage researchers to share their findings and work with our internal research team to test our mitigations so we can keep improving our defenses. We’ll continue to share notable bugs and bug bounty reports to celebrate the work of our community. Happy hunting!








