
As we’ve previously discussed, we use Chef to manage the configuration of our server fleet. Within Chef, a logical grouping of configuration is referred to as a cookbook. Today, I’m happy to announce that we are releasing 14 of our internal cookbooks. Together this suite of cookbooks — along with a sample “init” cookbook — will allow anyone who wants to use our model of Chef in their own environment to get started easily and quickly.
History
But let’s back up for a moment — how did we get here? In early 2013, we started speaking publicly about how we’d changed our approach to system configuration management at Facebook. We were using Chef, a standard tool, but in a very different way from most shops. At the same time, we released some of the tools we’d written during the process. Over the years, we’ve released several more tools, and I’ve spoken at many conferences around the world, where I enjoyed meeting hundreds of brilliant people and engaging in countless interesting discussions.
That initial talk included a lot of sample code in the slides on how we built our cookbooks, but one question I got repeatedly was how to get access to the actual cookbooks themselves. We didn’t have the resources to make many of our cookbooks generic, but we heard you: In May 2014, we released two small but representative cookbooks, along with a document that tried to encompass all the data in those slides into a living markdown format. Unfortunately, we were on Chef 10 at the time, and much of the world was on Chef 11, and so those cookbooks were essentially forked in order to give actual code examples to the community.
Today
Now, however, we’ve completely refactored 14 of our core cookbooks (i.e., cookbooks that our other cookbooks utilize) to be generic. These are cookbooks we use internally in our production environment. We hope this is just the beginning, and we will continue to release more as time allows. This is the open source model we use with all the other Chef tools we’ve released, and we’re happy to finally be able to do this with our cookbooks.
Quick start
We’ve tried to document everything in the README.md, but let’s take a quick tour of what this gives you. We’ve talked about our model at the above blog post and many other places, so we’ll make this brief. To get started, you would clone our repo and rename the fb_init_sample to fb_init. Set up a runlist like:
recipe[fb_init], recipe[your_service]
Take a gander through fb_init::default — it may make sense to comment out some of the cookbooks until you’re ready to use them. Here we’ll assume you’re on a disposable VM for test purposes and anything overwritten is fine.
Because the fb_init cookbook (which includes the rest) is first in your runlist, you now have a slew of simple attribute-driven APIs available to you.
Now create the your_service cookbook and let’s see some of those APIs in action:
# let's set some sysctls
node.default['fb_sysctl']['net.ipv6.conf.eth0.accept_ra'] = 1
node.default['fb_sysctl']['net.ipv6.conf.eth0.accept_ra_defrtr'] = 1
# and maybe some limits
node.default['fb_limits']['*']['nofile'] = {
'hard' => '65535',
'soft' => '65535',
}
# Also, those logs are unwieldy
node.default['fb_logrotate']['configs']['your_service'] = {
'files' => [
'/var/log/your_service.log',
],
}
# we don't need no stinkin' swap
node.default['fb_swap']['enabled'] = false
# let's prevent nf_conntrack from accidentally getting loaded, it has
# a terrible performance penalty
node.default['fb_modprobe']['extra_entries'] += [
'block list nf_conntrack',
'install nf_conntrack /bin/true',
'block list nf_nat',
'install nf_nat /bin/true',
]
# let's tell people what we're running when they log in
node.default['fb_motd']['extra_entries'] << 'This runs your_service.'
# we need to mount an extra tmpfs
node.default['fb_fstab']['mounts']['your_service_data'] = {
'device' => 'your_service_tmpfs',
'type' => 'tmpfs',
'opts' => 'size=5G',
'mount_point' => '/mnt/your_service-tmpfs',
}
And that’s it! Those sysctls will be set, limits set, logrotation setup, swap disabled, extra modprobe configurations added, extra /etc/motd lines added, and finally an extra tmpfs mounted!
But it gets better. If you delete the fb_modprobe lines in that recipe, on the next Chef run, those lines disappear from /etc/modprobe.d/fb_modprobe. If you remove the fb_swap lines, swap will be reenabled (the default in the cookbook).
Hierarchical configs and runlists
From here it’s easy to build hierarchical configs. Let’s say you work for SampleCorp and have a runlist like so:
recipe[fb_init], recipe[sc_internalwebserver]
fb_init has a recipe for for adding site defaults, so let’s say you modify fb_init::site-settings and do:
node.default['fb_resolv']['search'] = ['samplecorp.com'] # very strong reverse path filter node.default['fb_sysctl']['net.ipv4.conf.all.rp_filter'] = 1
Then in sc_webserver::default (not in the above runlist) — which is a generic webserver setup that is a good base for any webserver at SampleCorp — you do:
# We have DSR interfaces and need loose rp_filter node.default['fb_sysctl']['net.ipv4.conf.all.rp_filter'] = 2
And finally in sc_internalwebserver::default
include_recipe 'sc_webserver' node.default['fb_resolv']['search'] = <<' corp.samplecorp.com' # we do some craziness and need no rp_filtering, delete this line # after it's fixed! node.default['fb_sysctl']['net.ipv4.conf.all.rp_filter'] = 0
sc_webserver only has to concern itself with how it’s different from the rest of SC; meanwhile, sc_internalwebserver only has to handle further changes. If sc_internalwebserver stops setting something (sysctl, cronjob, logrotation setting…), it is removed from systems or reverts to the next most specific setting as appropriate. Of course, this is an oversimplified example. For instance, ostensibly sc_webserver would provide some APIs, such as maybe node['sc_webserver']['config']['ServerName'] and node['sc_webserver']['config']['DocRoot'].
However, one can see here how this allows for composing a runlist that is very hierarchical and enables each team to have to understand only whatever it is they need to modify. As an example, we can imagine a runlist that looks like:
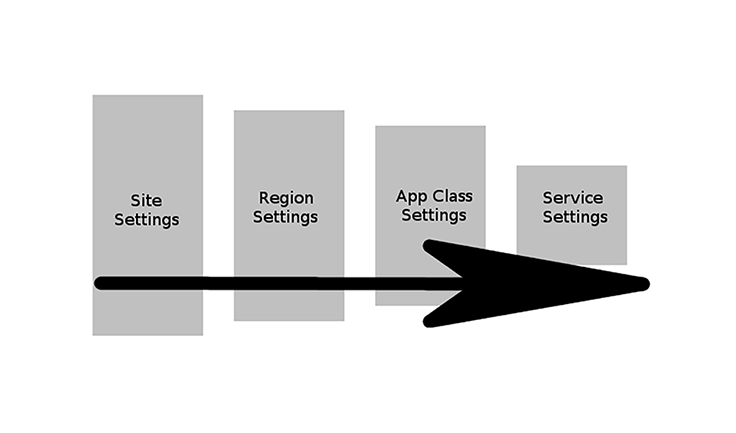
At each stage we override only the settings applicable — and just as important, any stage can override anything from the previous stage. This allows teams owning, say, site settings to not have to know every possible combination of sysctls every application could need, and allows the team owning service settings to not have to know about every sysctl in the world. Each team does what it does best and scales better.
This is how our runlists are set up at Facebook: Every runlist has fb_init first and then the “owner’s” cookbook. This can include whatever additional cookbooks they want that aren’t in fb_init, set any attributes they want, and of course do any other setup (such as service or package rules) they need.
fb_fstab
Many of our cookbooks turn out to be quite simple under the hood: a small template with a loop over a hash. However, not every service is so simple, and it was important that we release a more complicated cookbook that still followed our model. Enter fb_fstab. If you’ve ever dealt with the mount resource in Chef you’re probably aware of how painful it can be to have idempotency try to happen at a “line” level. When you change a mount, it has to try to guess what line was the resource it was managing, and that gets hard because the data it would use to figure out what it’s managing is different — because you’re changing the mount!
fb_fstab manages the entire of /etc/fstab and the set of mounted filesystems as a single unit to be managed. Changes are updated in fstab and adjusted accordingly on live mounts. If you remove something from fb_fstab‘s attributes, it is unmounted and removed from fstab properly as expected. If you change something, the change happens intelligently. It’s extraordinarily powerful — but because it needs to own the entire mounted subsystem, it also requires some work to roll out safely.
For the moment, let’s ignore the problem of the base OS mounts (/, /boot, swap, for example) that came with your OS, and concentrate on the rest. Let’s take an example where you have an extra five disks you need to mount:
%w{sdb sdc sdd sde sdf sdg}.each do |disk|
node.default['fb_fstab']['mounts'][“data_#{disk}”] = {
'device' => "/dev/#{disk}",
'mount_point' => "/mnt/#{disk}",
'type' => 'xfs',
'opts' => 'rw',
}
end
Voilà, those will be kept mounted in an /etc/fstab. Drop sdf from that list and it will be be removed from /etc/fstab and (optionally) unmounted. A few things to note about fb_fstab:
- By default, unmounting and remounting are disabled, and anything that needs those will emit a warning.
- Anything mounted that
/etc/fstabdoesn’t know about and isn’t in its ignore list will be either unmounted or warned about, depending on whether the aforementioned unmount option is enabled.
Several advanced options are available. For example, any entry in the mounts hash can have a only_if key with a code block value. That only_if works like normal only_ifs on standard Chef resources: It is late-evaluated, and actions will not be taken if it fails. Unlike Chef’s only_if, it accepts only a code block. See the fb_fstab README.md for more.
Back to the problem of base OS filesystems: The preferred way to handle this is to create a special file during your installation (during Kickstart, for example) that lists these filesystems. In the docs we recommend something like this:
grep -v '^#' /etc/fstab > /etc/.fstab.chef chmod 400 /etc/.fstab.chef
fb_fstab will then use this list as if these configurations had been passed in through attributes. The reason is to enable using UUIDs or whatever other things may be system-specific. However, anything in the actual attributes that overrides base mounts will win. If the special file does not exist the first time fb_fstab runs, it’ll attempt to create one using its best guess on what is “base” on the existing system. That code is only there to ease transition; we highly recommend you set that file up during transition instead.
Contributing
Like with any open source project, we welcome contributions! You can find some guidance on contributing in the CONTRIBUTING.md in the repo. In particular, these cookbooks primarily assume CentOS since that’s what we have in production, but we will gladly accept diffs that add support for other distributions or UNIX-like operating systems.
Conclusion
We’re very excited to be continuing to contribute to the Chef community; this repository will be kept in sync with our production code, and we hope to add new cookbooks in the future. We hope this code is useful, and we can’t wait to hear what you think. We’ll see you at ChefConf!
In an effort to be more inclusive in our language, we have edited this post to replace black list with block list.








