
We’ve improved read availability in LogDevice, Meta’s scalable distributed log storage system, by removing a fundamental trade-off in Flexible Paxos, the algorithm used to gain consensus among our distributed systems. At Meta’s scale, systems need to be reliable, even in the face of organic failures like power loss events, or when systems are undergoing hardware maintenance. By optimizing LogDevice’s consensus algorithm, we’ve made it even more available for a wide variety of use cases across Meta’s data centers, particularly for write tasks, since the data generated from these tasks can’t be stored anywhere else.
Why we developed LogDevice
LogDevice provides durability, high availability, and a total order of records under failures such as power loss or natural disasters. It’s designed for a variety of workloads, including event streaming, replication pipelines, transaction logs, and deferred work journals. It’s based on a flexible Multi-Paxos, which allows it to gain consensus in a distributed system quickly and efficiently.
We designed LogDevice to serve as a transaction log and write-ahead log because low latency and high write availability are important for these types of logs. Over time, LogDevice ended up serving a wide variety of use cases, such as updates to secondary indices and training pipelines for machine learning use cases, including stats and logs collection for monitoring systems. Eventually, this resulted in a general pipeline for a variety of data analytics use cases.
Every use case LogDevice serves needs high write availability. In the case of a write-ahead log, for example, since the log guarantees the durability of an operation through the entire distributed system in the event of a machine failure, losing write availability would prevent data mutation and trigger system unavailability.
For use cases where LogDevice serves as a data sink, most of the incoming data is either inefficient to recompute or exists only in memory before being persisted in LogDevice. Given the amount of data being generated, there are limited buffering options in the event of an outage. This essentially means that in the case of write unavailability, data gets lost.
Read availability holds a bit less importance than write availability, as most of the use cases can tolerate a short delay in data delivery. One thing that’s important to note: LogDevice is a streaming system with the vast majority of data being consumed as it gets written, with less than one percent of reads interested in data older than three hours. Because of this, the read availability of older data is considered less important.
A brief overview of Paxos and its variants
Paxos in a nutshell
Paxos acts as a consensus algorithm. More precisely, it represents a family of consensus algorithms. It guarantees multiple participants will agree on the same value in an unreliable environment.
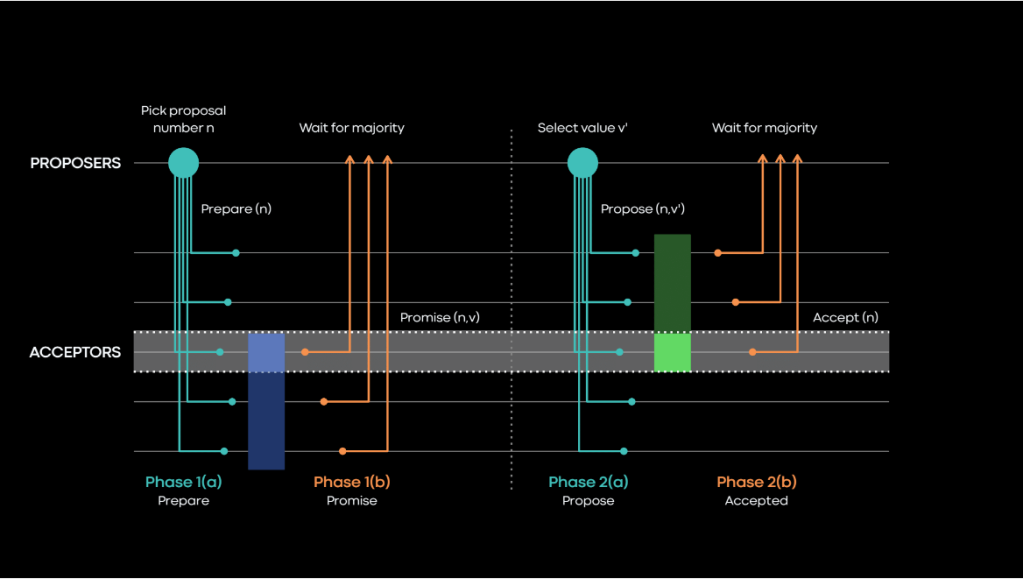
The basic variant, explained in the 2001 paper Paxos Made Simple by Leslie Lamport, recognizes three different roles: proposers, acceptors, and learners.
The algorithm consists of two phases: In the first phase, any proposer trying to reach an agreement on a value, V, attempts to get itself elected as a leader for the second phase. During the second phase, the proposer that became a leader (via a majority of votes from acceptors) proceeds with storing V on the acceptors. To reach an agreement on the value of V, the leader needs to again get a majority of votes from acceptors.
The learner role looks for the point in time at which an agreement has been reached. After learners have discovered that an agreement has been reached, the algorithm guarantees that a repeatable value will be returned if acceptors are asked what value has been agreed to.
In practice, the learner role most often unifies with the proposer. The proposer, only after learning that agreement has been reached, returns “success” to an actual client trying to store V in the system.
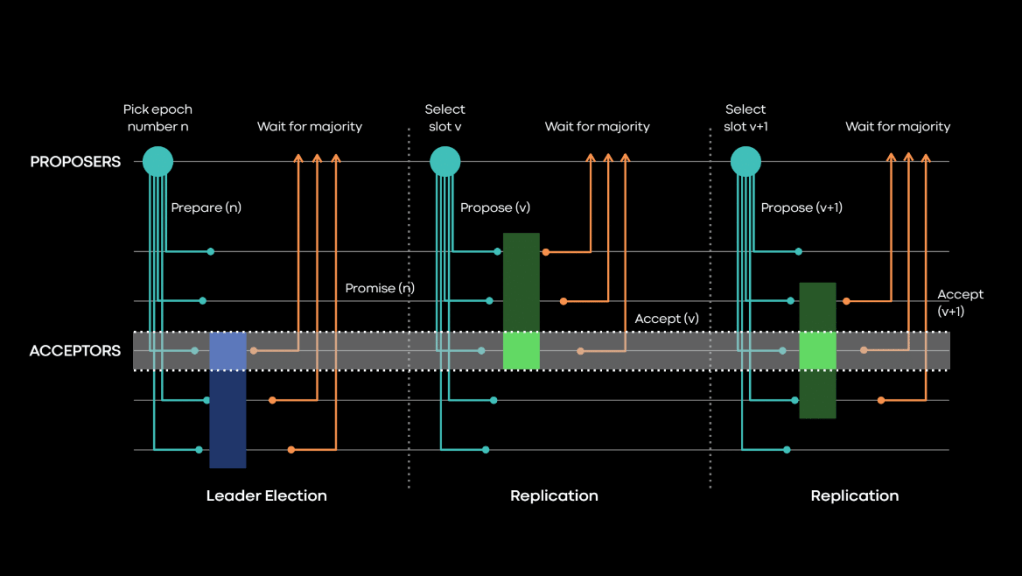
The Multi-Paxos optimization
The Multi-Paxos observes that if the same proposer is kept to reach an agreement for values on multiple slots, then there’s no need to repeat the leader election phase. The elected leader can continue repeating the second phase for multiple slots. It does so until a new proposer tries to get itself elected as the new leader in the process, preventing the previous leader from completing phase two.
Flexible Paxos
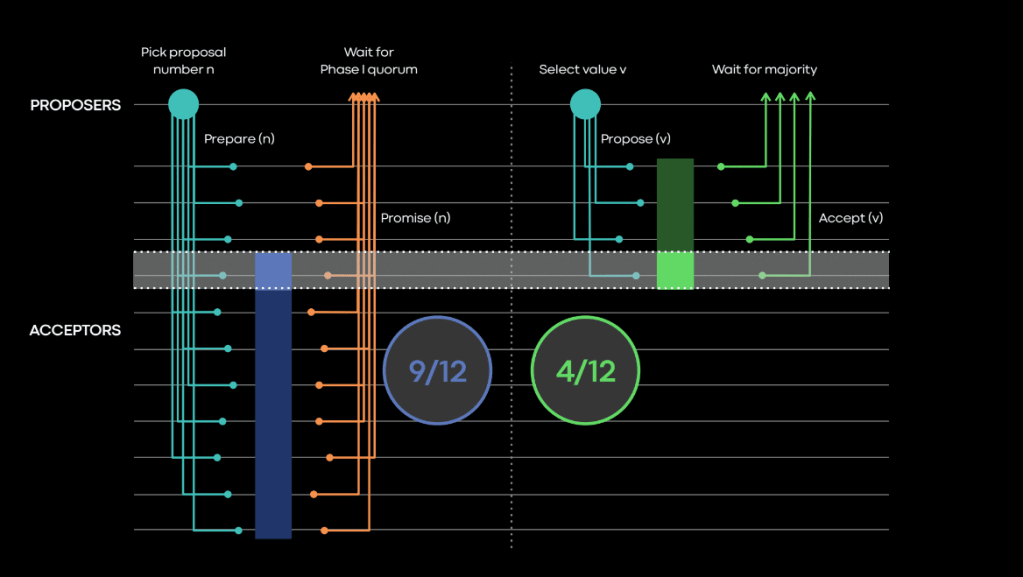
In vanilla Paxos, the requirement for completing both phases is the same. A majority of acceptors need to vote or accept the operation for a successful result. This guarantees that each set of votes used for successful leader election will intersect with not only each potential set needed for an agreement of value. This assures accuracy because we want to guarantee that after a leader has been elected, no previous leader can successfully complete an agreement on value.
The guarantees given by using majority vote in both phases also have a side effect that every two possible successful sets of votes for a value agreement will intersect.
The strengths and weaknesses of Flexible Paxos
Without Flexible Paxos, increasing the size of the acceptor set necessarily increases the number of votes needed to achieve a majority. In practice, this means that for every increase of the acceptor set, we also store more copies of each agreed-upon value. For every two acceptors added, we need to increase the number of copies by at least one. As a result, the useful capacity of the acceptor set is limited to be strictly less than double the capacity of the largest acceptor. Flexible Paxos allows us to increase the size of the acceptor set without changing the number of data copies needed. This makes it infinitely scalable for acceptor set capacity.
Separate scaling of the acceptor set opens up more possibilities for deciding where we can place the data. Because a large acceptor set does not create a need for additional storage, we can easily spread it across multiple geographically distributed locations. For a streamlike system like LogDevice, this opens up possibilities. It can detect, in real time, which geographical locations data is being consumed and then place the data closer to consumers. This does not come at the cost of write availability, as losing a region or multiple regions still leaves enough acceptors to accept new values.
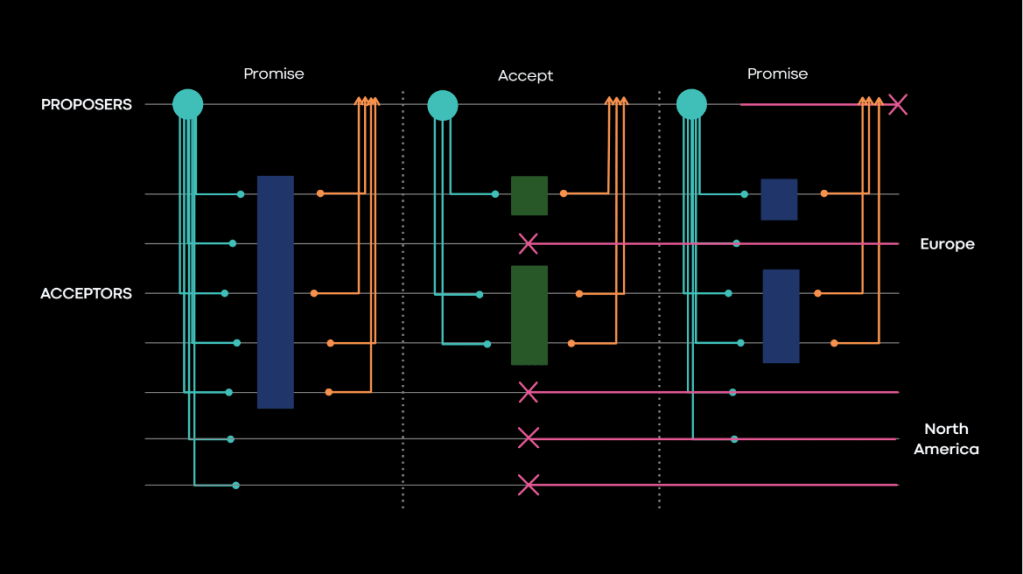
LogDevice consensus and trade-offs
LogDevice is based on a flexible Multi-Paxos but with some important deviations and additions that we must also consider.
Reading without a need for quorum
Paxos allows multiple proposers to consider themselves as leaders at the same time. It only guarantees that exactly one of the leaders will manage to successfully complete the second phase. The consequence of this is that there could be partially written values from the previous leader. In order to always return the agreed-upon value, the algorithm requires a majority of acceptors to participate. This guarantees that we will see at least one value with the latest version, and that one will be returned. This makes reading values a compute-intensive operation, especially in Flexible Paxos, where it is not a majority but possibly a much larger set of acceptors. From this point we will call it read quorum.
Notably, for an append-only stream such as LogDevice, a single possible value will always exist for any given slot during normal leader operation. The only case in which we can have partial values written is when a leader fails. If we could guarantee that even in that case we’d always have a single value returned by any of the acceptors, we would be able to read even without the read quorum. As soon as any of the participants returns a value, a guarantee that this particular slot exclusively holds this value lets us safely complete the read operation.
We guarantee this through LogDevice’s recovery process. It runs each time a leader gets elected. This rather extensive process also blocks reads of any writes done on the new leader until it is complete.
Maintaining write availability during leader failover
As mentioned earlier, Flexible Paxos trades off lower read availability and leader failover for more flexibility in data placement and higher write availability.
Due to the read access pattern being highly skewed toward new data, the lower read availability does not affect LogDevice. Our replication factor is usually three. We were not hitting cases where we would lose three acceptors within hours of one another. We lost the read quorum, but given the optimization of not requiring quorum for reading data, reads were not affected.
The same could not be said for the inability to failover leaders. Every read quorum loss automatically results in an inability to elect the next leader due to the quorum requirements being the same as for reads.
Early in LogDevice’s development, we decided to introduce a separate membership mechanism. It allows us to fully reconfigure a set of acceptors regardless of the availability of the current set of acceptors. This mechanism is based on external consensus, more specifically ZooKeeper. The approach is not without trade-offs, however. Even with the ability to reconfigure the acceptor set and elect a new leader, without having a read quorum in the previous acceptor set we cannot guarantee that the previous leader stopped writing. Nor can we run our recovery process. In other words, we traded off linearizable writes for write availability. However, we could not allow reads to proceed even for newly written data. This resulted in read availability loss.
Challenges in practice
With our fleet size and a combination of maintenance and organic failures, we found ourselves dealing with a “stuck recovery” often. This made stuck recovery the biggest offender of our read service-level agreements (SLAs). Each of these instances required a manual intervention where a team member would look at machines that were causing a quorum loss. They would identify that the machines had been unavailable for a while and therefore don’t contain any data relevant to the recovery process, so it would allow recovery to proceed even without quorum.
This raised the question: Why can’t the system make this decision on its own? Especially if a human can identify that correctness will not be violated by disregarding the unavailable nodes.
Flexible leader election quorum
The leader failover process and leader election quorum are only interested in preventing any potential in-flight writes. Let’s say that a currently active leader exists and uses the whole acceptor set. At some point, a few of the acceptors become unavailable. The leader notices this and excludes them from the active set of acceptors. We can call this new set of acceptors that the leader currently uses a write set.
The leader constantly monitors the available set of acceptors and keeps this write set up to date. Since any in-flight operations only happen on the write set, we can safely say that a quorum on the write set is enough to elect a new leader. The only bit left in the puzzle involves how to propagate this information to all potential future leaders. As it turns out, we propagate information in such a way all the time. Any successful completion of phase two of Flexible Paxos is guaranteed to be visible by all future leaders. In other words, it is enough to do a special reconfiguration write informing that the write set has changed, and it will be picked up by the next potential leader during the election.
Adjusting the write set and persisting it occurs on the same leader. As a result, guaranteeing what happens beforehand gets easy. The leader guarantees that before persisting the reduced write set it stops using the acceptors being excluded. It also guarantees that the leader does not use new acceptors until a write set containing them is persisted.
During the leader election process, a proposer can start with the full acceptor set. While asking for votes from this set, it can get information about the change in the write set and adjust accordingly.
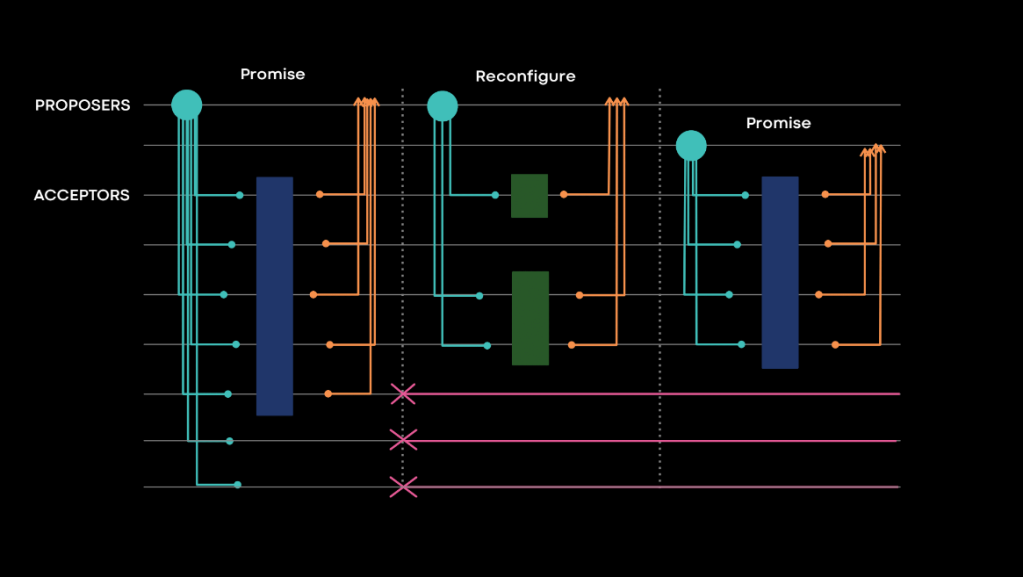
In practice, a leader will observe losses and adjust the necessary quorum for leader election quickly. As such, the only risk left for not being able to elect leaders is if both a quorum gets lost and the leader becomes unavailable at almost the same time. This research paper details the observations this improvement is based upon.
While it’s observed that only acceptors participating in in-flight operations matter, the approach to using this information has been different. In DPaxos, an active leader constantly announces the acceptor set that it will use for the next operations. This introduces some problems that the paper explores in further detail, along with the solutions.
Results in LogDevice
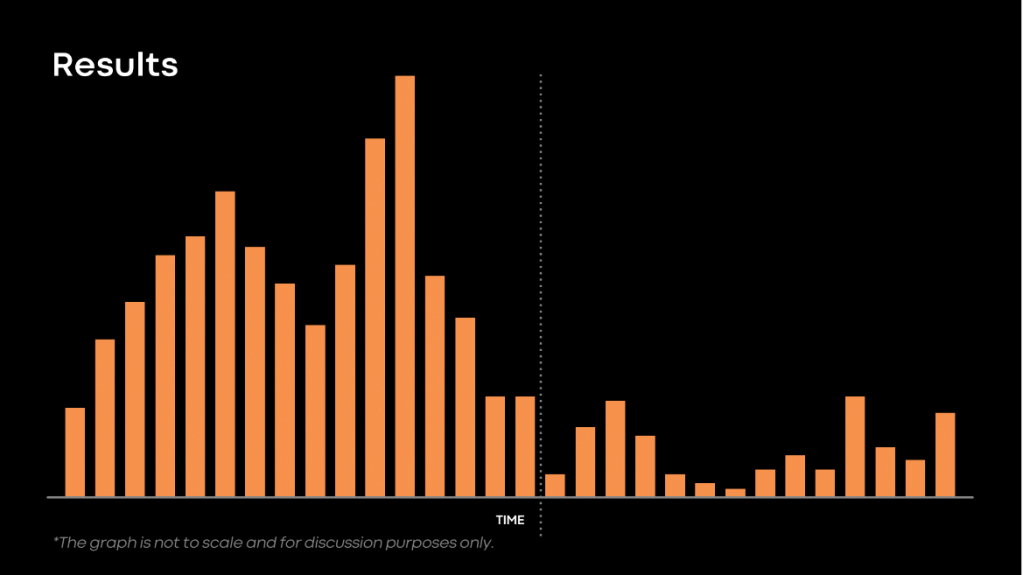
As mentioned earlier, before implementing this improvement, we experienced issues with stuck recovery. After the feature rollout, we didn’t suffer a single instance. This reflected nicely in our read availability SLA. The image below shows the percentage of time we were not meeting our aspirational availability SLA before the feature rollout (left of the dotted line) and after it (right of the dotted line).
Apart from the immediate benefits regarding our SLA, we also no longer need to fall back to our membership change for leader election. We have since implemented support for linearizable writes and are working on an “exactly once” mode of delivery.








