
Managing app size at Facebook is a unique challenge: Every day, developers check in large volumes of code, and each line of code translates into additional bits in the apps that people ultimately download onto their phones. Left unchecked, this added code would make the app bigger and bigger until eventually the time it takes to download would become unacceptable. Compression is one of the methods we use to keep app size minimal. These compressed files take up less space, which means smaller apps that download faster and use less bandwidth for billions of users around the world. Such savings are especially important in regions where mobile bandwidth is limited, making it costly to download large apps. But compression alone isn’t enough to keep pace with all the updates we make and features we add to our apps. So we developed a technique called Superpack, which combines compiler analysis with data compression to uncover size optimizations beyond the capability of traditional compression tools. Superpack pushes the limits of compression to achieve significantly better compression ratios than existing compression tools.
Over the past two years, Superpack has been able to check developer-induced app size growth and keep our Android apps small. Superpack’s compression has helped reduce the size of our fleet of Android apps, which are substantially smaller in comparison to regular Android APK compression, with average savings of over 20 percent compared with Android’s default Zip compression. Some apps that use Superpack include Facebook, Instagram, WhatsApp, and Messenger. The reduction in the size of these apps thanks to Superpack is illustrated in the table below.
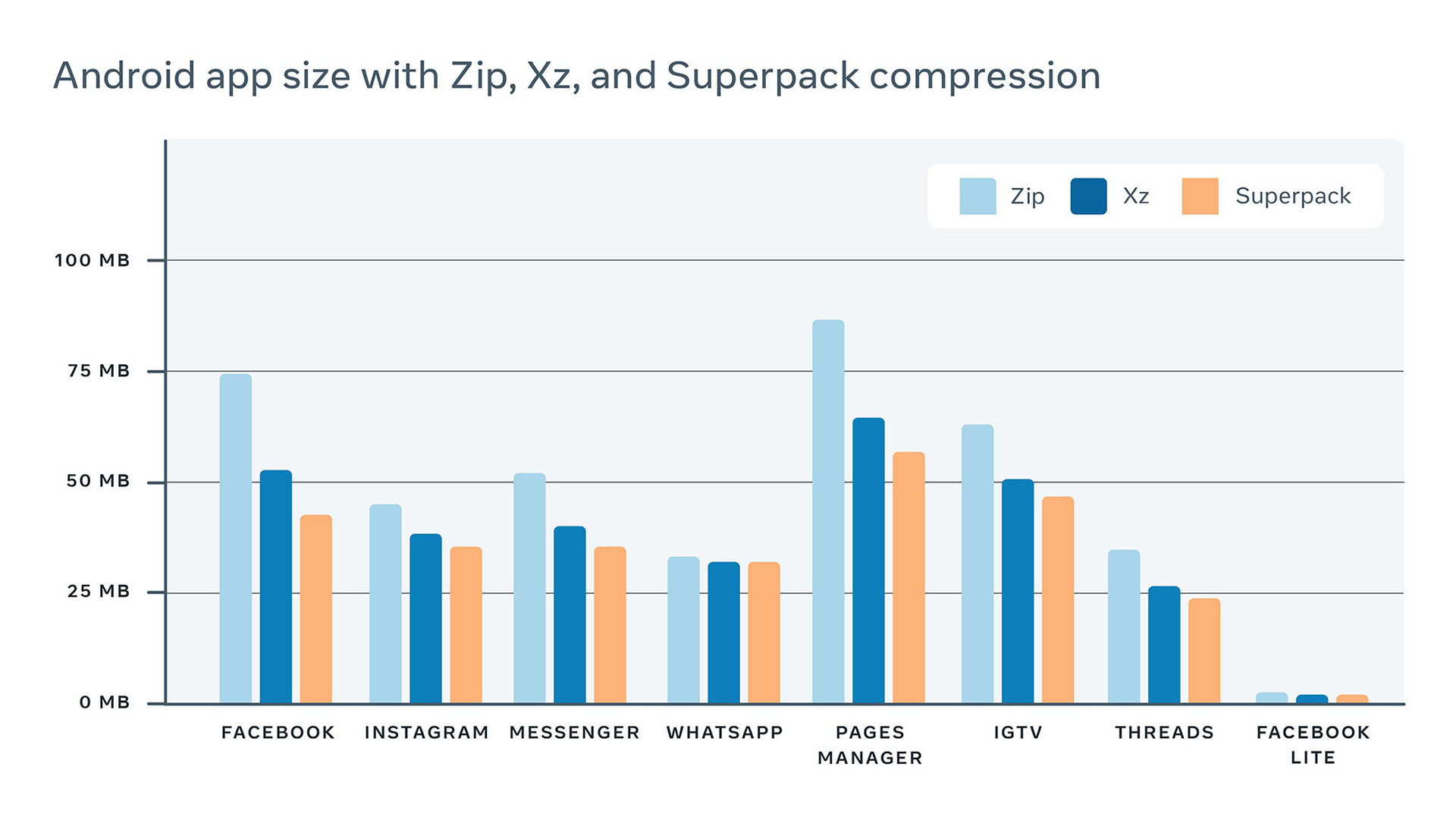
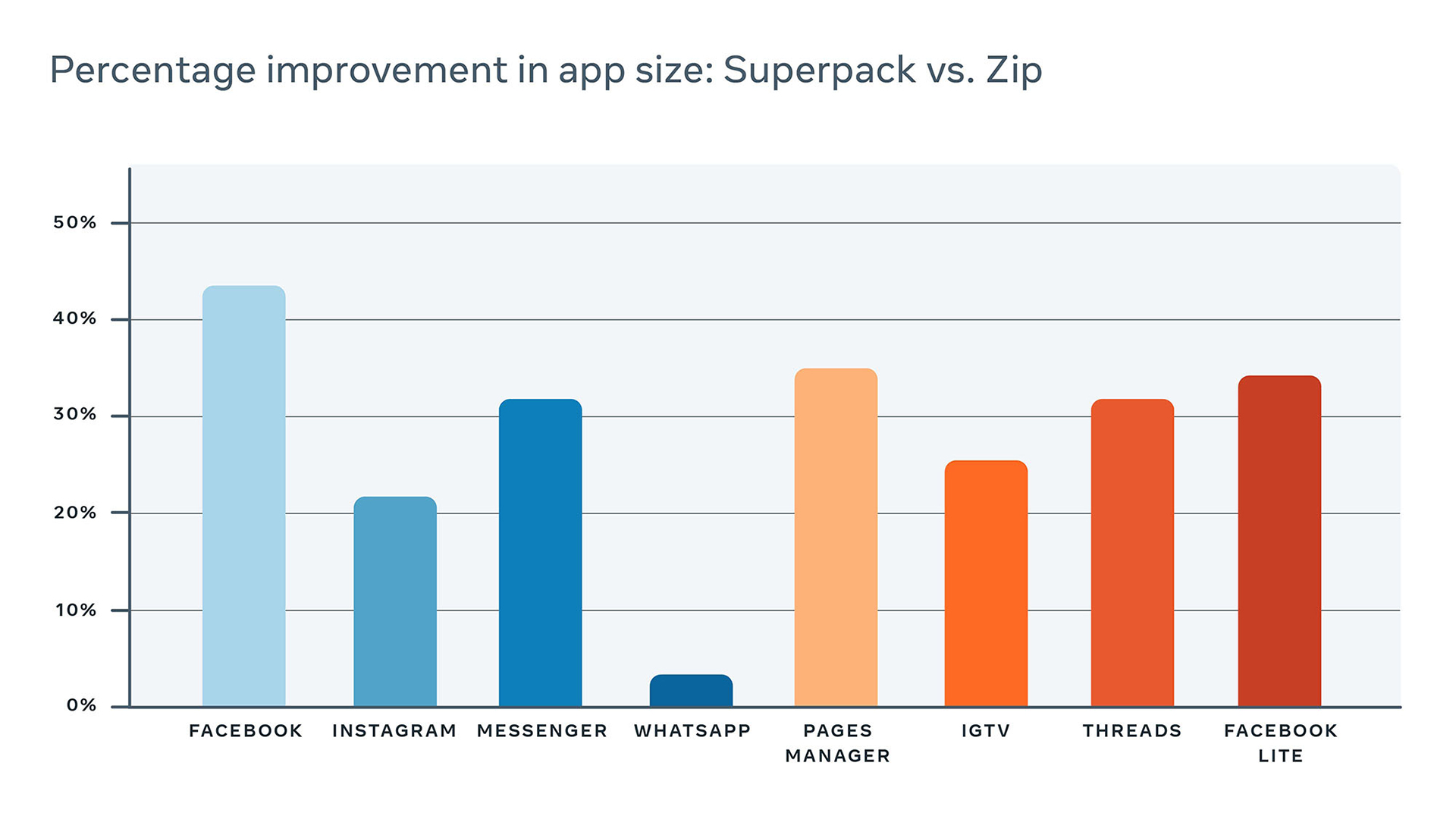
Superpack: Compilers meet data compression
While existing compression algorithms, such as Zip’s Deflate and Xz’s LZMA, work well with monolithic data, they weren’t enough to offset the pace of growth we were seeing in our apps, so we set out to develop our own solution. Compression is a mature field, and the techniques we’ve developed crosscut the entire compression spectrum, from data comprehension and Lempel-Ziv (LZ) parsing to statistical coding.
Superpack’s strength lies in compressing code, such as machine code and bytecode, as well as other types of structured data. The approach underlying Superpack is based on an insight in Kolmogorov’s algorithmic measure of complexity, which defines the information content of a piece of data as the length of the shortest program that can generate that data. In other words, data can be compressed by representing it as a program that generates the data. When that data is code to begin with, then it can be transformed into one with a smaller compressed representation. A program that generates Fibonacci numbers, coupled with a list of their indices, is a highly compressed representation of a file containing such numbers. The idea of reducing Kolmogorov complexity in itself is not new to the domain of compression. Superpack’s novel approach involves combining compiler methods with modern compression techniques to achieve this goal.
There is considerable benefit in formalizing compression as a generative process that produces small programs. It gives the data compression engineer access to a treasure trove of mature compiler tools and techniques that can be repurposed to the end of data compression. Superpack compression leverages common compiler techniques such as parsing and code generation, as well as more recent innovations such as Satisfiability modulo theories (SMT) solvers to find the smallest programs.
One important ingredient of Superpack’s effectiveness is its ability to marry these compiler techniques with those used in mainstream data compression. Semantic knowledge from the compiler half of Superpack leads to enhanced LZ parsing (the step in compression that eliminates redundancy), as well as improved entropy coding (the step that produces short codes for frequent pieces of information).
Improved LZ parsing
Compressors typically identify repeating sequences of bytes using an algorithm selected from the LZ family. Broadly, each such algorithm tries to substitute recurring sequences of data with pointers to their previous occurrences. The pointer consists of the distance in number of bytes to the previous occurrence, along with the length of the sequence. If the pointer can be represented in fewer bits than the actual data, then the substitution is a compressed-size win. Superpack improves the process of LZ parsing by enabling the discovery of longer repeating sequences while also reducing the number of bits to represent pointers.
In the programs being compressed, Superpack enables these improvements by grouping data based on its AST. For example, in the following sequence of instructions, the length of the longest repeating sequence is 2. However, when sorted into groups based on AST types, namely, the opcode and registers (Group 1 in the table below) and immediates (Group 2 in the table), the length increases to 4. In the raw parse of the original data, the distance between the repeated sequences is 2 instructions. But in the grouped version, the distance is 0. Smaller distances typically use fewer bits, and longer sequence matches save space by capturing more input data in a given pointer. Accordingly, the pointer that Superpack generates is smaller than the one computed naively.
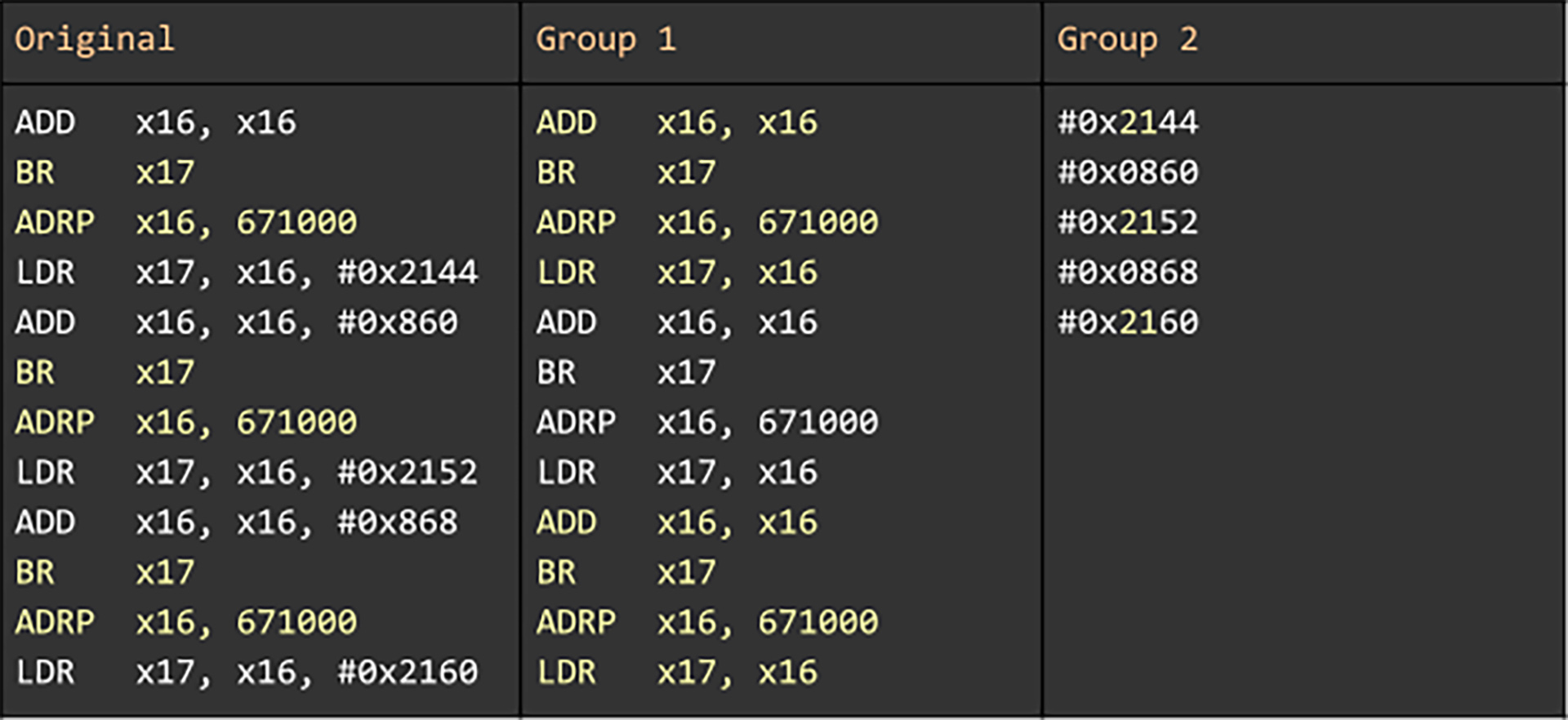
But how do we decide when to split the code stream and when to leave it intact? Recent work in Superpack introduces hierarchical compression, which incorporates this decision into the optimizing component of LZ parsing, called the optimal parse. In the edited code below, it is best to leave the last segment of the snippet in its original form, and generate a single match with a pointer to the first five instructions, while splitting the rest of the snippet. In the split-out remainder, the sparseness of register combinations is exploited to generate longer matches. Grouping the code in this manner also further reduces distances by counting the number of logical units between repeating occurrences, as measured along the AST, instead of measuring the number of bytes.
Improved entropy coding
Repeating sequences of bytes are substituted efficiently with a pointer to the previous occurrence. But what does the compressor do for a nonrepeating sequence, or for short sequences that are cheaper to represent than a pointer? In such cases, compressors represent the data literally by coding the values in it. The number of bits used to represent a literal exploits the distribution of values that the literal can assume. Entropy coding is the process of representing a value using roughly as many bits as the entropy of the value in the data. Some well-known techniques that compressors use to this end include Huffman coding, arithmetic coding, range coding, and asymmetrical numeral systems (ANS).
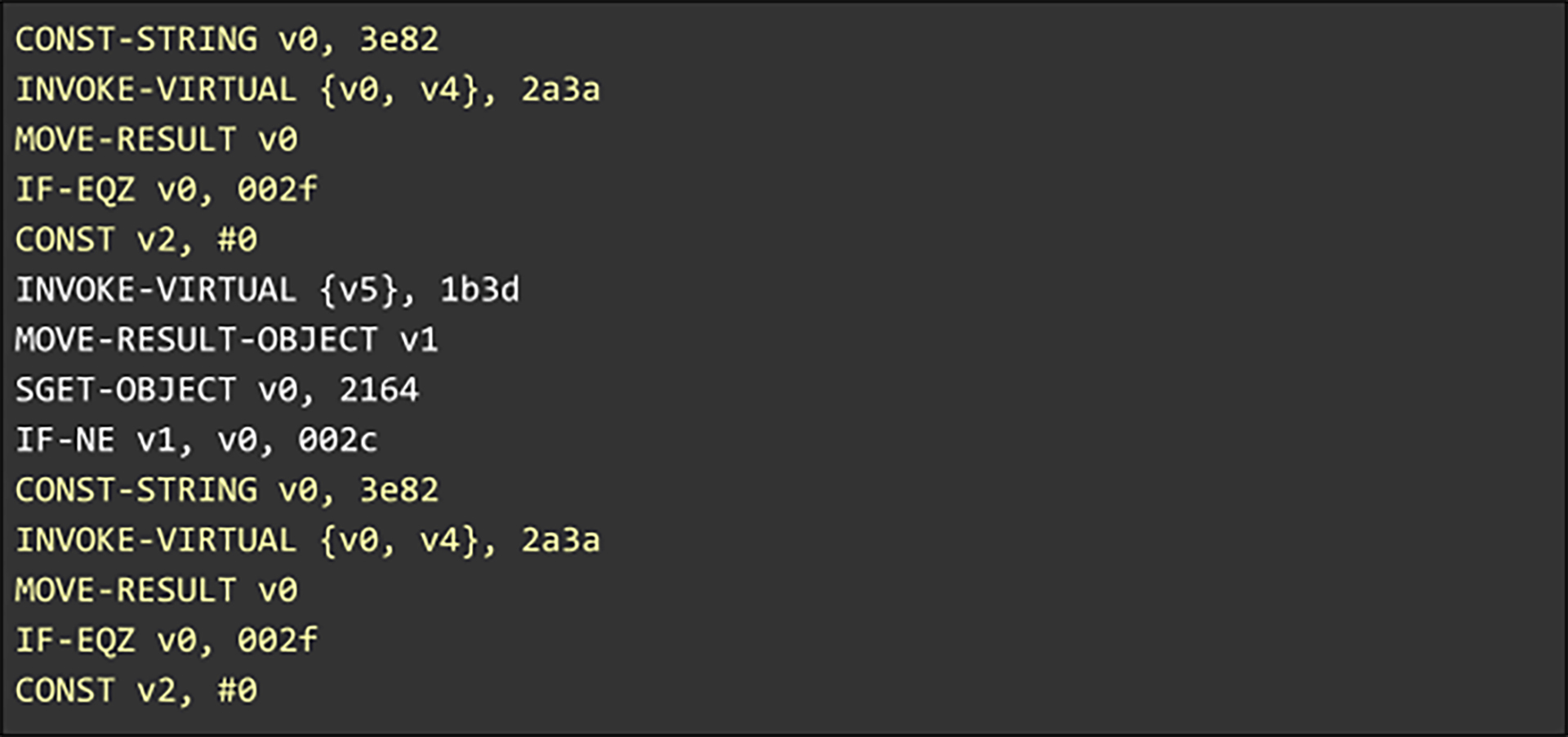
Superpack has a built-in ANS coder, but also features a pluggable architecture that supports multiple such coding back ends. Superpack improves entropy coding by identifying contexts in which the literals to be represented have lower entropy. Like in the case of LZ parsing, the contexts are derived from Superpack’s knowledge of the structure of the data extracted via compiler analysis. In the reduced sequence of instructions below, there are seven different addresses, each with the prefix 0x. In a large volume of different arrangements of this code, the number of bits used by a regular coder to represent the address field would approach 3.
However, we notice that three out of the seven addresses are paired with the BL opcode, while another three are associated with B. Only one is coupled with both. If this pattern were to hold true in the entire body of code, then the opcode can be used as a coding context. With this context, the number of bits to represent these seven addresses approaches 2 instead of 3. The table below shows the coding with and without the context. In the Superpack-compressed case in the third column, the opcode can be seen as predicting the missing bit. This simple example was contrived to illustrate how compiler contexts can be used to improve coding. In real data, the number of bits gained is usually fractional, and the mappings between contexts and data are seldom as direct as in this example.

Programs as compressed representations
We explained how Superpack improves LZ parsing and entropy coding when the data being compressed consists of code. But what happens when the data contains a stream of unstructured values? In such cases, Superpack tries to lend the values structure by transforming them into programs at compression time. Then, at decompression time, the programs are interpreted to recover the original data. An example of this technique is the compression of Dex references, which are labels for well-known values in Dex code. Dex references have a high degree of locality. To exploit this locality, we transform references into a language that stores recent values in a logical register, and issues forthcoming values as deltas from the values that were pinned down.

Writing an efficient compressor for this representation reduces to the familiar register allocation problem in compilers, which decides when to evict values from registers to load new values. While this reduction is specific to reference bytecode, a general idea applies to any bytecode representation, namely, that the resulting code is amenable to the optimizations outlined in the previous two sections. In this example, LZ parsing is improved by cohorting the opcodes, MOV and PIN, in one group, collecting the deltas in a second group, and recent references in a third group.
Superpack on real data
There are three main payloads targeted by Superpack. The first is Dex bytecode, the format into which Java gets compiled in Android apps. The second is ARM machine code, which is code compiled for ARM processors. The third is Hermes bytecode, which is a specialized high performance bytecode representation of Javascript created at Facebook. All three representations use the full breadth of Superpack techniques, powered by compiler analysis based on a knowledge of the syntax and grammar of the code. In all three cases, there is one set of compression transforms that is applied to the stream of instructions and a different set that is applied to metadata.
The transforms applied to code are all alike. Metadata transforms have two parts. The first part leverages the structure of the data, by grouping items by type. The second part leverages organizing rules in the specification of the metadata, such as those that cause the data to be sorted or expose correlations between items that can be used to contextualize distances and literals.
The compression ratios yielded by Zip, Xz, and Superpack for these three formats are shown in the table below.

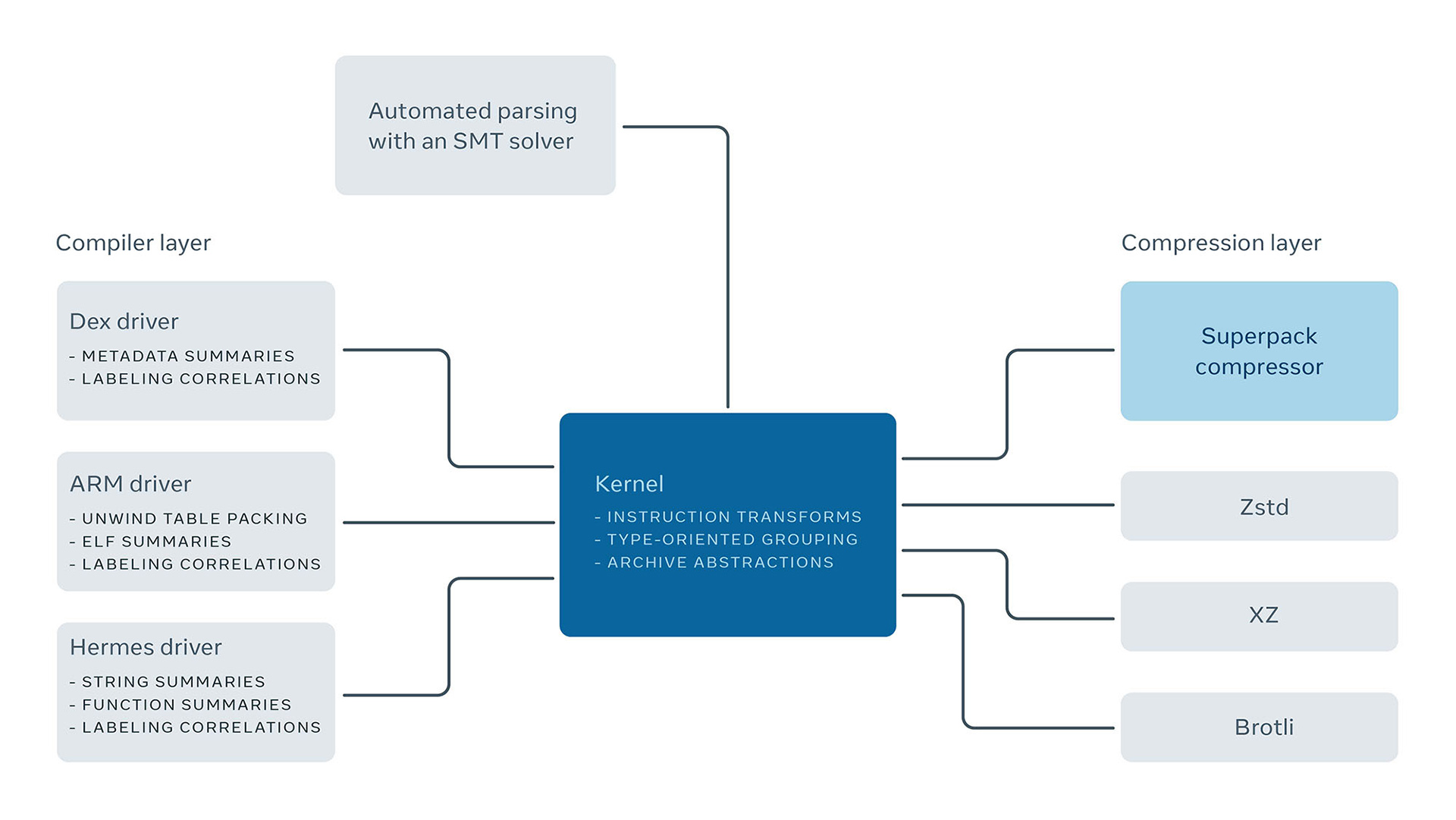
Superpack architecture and implementation
Superpack is a unique player in the compression space in that baked into it is knowledge of the types of data that it compresses. In order to scale the development and use of Superpack at Facebook, we developed a modular design with abstractions that could be reused across the different formats that we compress. Superpack is architected like an operating system, with a kernel that implements paged memory allocation, file and archive abstractions, abstractions for transforming and manipulating instructions, as well as interfaces to pluggable modules.
Compiler-oriented mechanisms fall into a dedicated compiler layer. Each format is implemented as a pluggable driver. Drivers exploit properties of the data being compressed, and label correlations in the code, to eventually be leveraged by the compression layer. The machinery that parses the input code uses automated inference based on an SMT solver. How we use SMT solvers to aid compression is beyond the scope of this post but will make a fascinating topic for a future blog post.
The compression layer also consists of pluggable modules. One of these modules is Superpack’s own compressor, which includes a custom LZ engine and an entropy coding back end. While we were in the process of building this compressor, we plugged in modules that leveraged existing compression tools to do the compression work. In that setting, Superpack’s role is reduced to reorganizing the data into uncorrelated streams. A best effort compression by an existing tool follows, which is effective but limited in the granularity at which it can identify and use compiler information. Superpack’s custom compression back end solves this problem through a fine-grained view of the internal representation of the data, which enables it to exploit logical correlations at the fine granularity of a single bit. Abstracting out the mechanism used to do the compression work as a module gives us a selection of a number of trade-offs between compression ratio and decompression speed.
Superpack’s implementation contains a mix of code written in the OCaml programming language and C code. OCaml is used on the compression side to manipulate complex compiler-oriented data structures and to interface with an SMT solver. C is a natural choice for decompression logic because it tends to be simple and at the same time is highly sensitive to the parameters of the processor on which the decompression code runs, such as the size of the L1 cache.
Limitations and related work
Superpack is an asymmetric compressor, which means that decompression is fast but compression is allowed to be slow. Streaming compression, in which data is compressed at the rate at which it is transmitted, has been a nongoal of Superpack. Superpack is unable to fit the constraints for this use case, as its present compression speed is not able to keep up with modern data transfer rates. Superpack has been applied to structured data, code, integer, and string data. It does not currently target image, video, or sound files.
On the Android platform, there is a trade-off between using compression to reduce download time and a possible increase in disk footprint and update size. This trade-off is not a limitation of Superpack, rather that interoperability has not yet been established between the packaging tools used by Facebook and the distribution tools used on Android. For example, on Android, app updates are distributed as deltas between the contents of consecutive versions of an app. But such deltas can only be generated by tools that are able to decompress and recompress the app’s contents. Since the diffing process implemented in the current tooling is not able to interpret Superpack archives, the deltas come out to be larger for apps containing such archives. We believe that issues of this type could be addressed through finer-grained interfaces between Superpack and Android tools, increased customizability in Android’s distribution mechanisms, and a public documentation of Superpack’s file format and compression methods. Facebook’s apps are dominated by code of the type that Superpack excels at compressing, in a way that goes far beyond existing compression implemented as part of Google Play on Android. So, for the time being, our compression is beneficial to our users despite the trade-off.
Superpack leverages Jarek Duda’s work on asymmetrical numeral systems as its entropy coding back end. Superpack draws on ideas in superoptimization, along with past work on code compression. It leverages the Xz, Zstd, and Brotli compressors as optional back ends to do its compression work. Finally, Superpack uses Microsoft’s Z3 SMT solver to automatically parse and restructure a wide range of code formats.
What’s next
Superpack combines compiler and data compression techniques to increase the density of packed data in a way that is especially applicable to code such as Dex bytecode and ARM machine code. Superpack has substantially cut the size of our Android apps, and consequently saved billions of users around the world download time. We have described some of the core ideas underlying Superpack but have only scratched the surface of our work in asymmetric compression.
Our journey has only just begun. Superpack continues to improve through enhancements to both its compiler and compression components. Superpack started out as a tool to cut mobile app size, but our success in improving the compression ratio of a variety of data types has led us to target other use cases of asymmetric compression. We are working on a new on-demand executable file format that saves disk space by keeping shared libraries compressed and decompressing them at load time. We are evaluating using Superpack for delta compression of code to reduce the size of software updates. We are also investigating using Superpack as a cold-storage compressor, to compress log data and files that are rarely used.
Until now, our mobile deployment has been limited to our Android apps. However, our work is equally applicable to other platforms, such as iOS, and we are looking into porting our implementation to those platforms. Presently, Superpack is available only to our engineers, but we aspire to bring the benefits of Superpack to everyone. To this end, we are exploring ways to improve the compatibility of our compression work with the Android ecosystem. This blog post is a step in this direction. We may someday consider open sourcing Superpack.
We’d like to especially thank Alfredo Altaminaro, Nikhil Prakash, Mauricio Nunes, and everyone else who has contributed to the Superpack effort.











