
Facebook’s infrastructure now serves more than 2.7 billion people each month across our family of apps and services. Our engineers design and build advanced and efficient systems to scale our infrastructure, but as our workloads grow, the systems cannot be served by traditional general-purpose processors alone. Transistor scaling has slowed significantly, necessitating the development of specialized accelerators and holistic system-level solutions to improve performance, power, and efficiency.
Creating efficient solutions for our infrastructure will require workload-optimized hardware, created through co-design efforts. To that end, we have been working with partners to develop solutions targeted at AI inference, AI training, and video transcoding, some of our fastest-growing services. Today we are announcing our next-generation hardware platform for training, code-named “Zion,” and new custom chip designs (known as application-specific integrated circuits) that are optimized for AI inference, code-named “Kings Canyon,” and for video transcoding, code-named “Mount Shasta.”
AI hardware
AI workloads are used throughout Facebook’s infrastructure to make our services more relevant and improve the experience of people using our services. Via AI models deployed at scale, we make more than 200 trillion predictions and over 6 billion language translations every day. We use more than 3.5 billion public images to create, or train, our AI models, which allows them to better recognize and tag content. AI is used across a range of services to help people in their daily interactions and provide them with unique, personalized experiences.
Most AI pipelines at Facebook are managed using our AI platform, FBLearner, which consists of tools that focus on different parts of the problem, including feature store, training workflow management, and our inference engine. Paired with Facebook-designed hardware released to the Open Compute Project (OCP), this enables us to efficiently deploy models at scale. Starting from a stable base, we have focused on creating a consolidated hardware design that is vendor agnostic and continues our disaggregated design principle for maximum operating efficiency. The result is our next-generation hardware for training and inference workloads.
AI training with Zion
Zion is our next-generation large-memory unified training platform. Zion is designed to efficiently handle a spectrum of neural networks including CNN, LSTM, and SparseNN. The Zion platform delivers high memory capacity and bandwidth, flexible high-speed interconnect, and powerful compute capabilities for our critical workloads.
Zion adopts our new vendor-agnostic OCP accelerator module (OAM). The OAM form factor allows our partners, including AMD, Habana, Graphcore, Intel, and NVIDIA, to innovate faster by developing their solutions on top of the OCP common specification. Zion architecture allows us to scale out beyond each individual platform to multiple servers within a single rack using the top-of-rack (TOR) network switch. As our AI training workloads continue to grow in size and complexity, the Zion platform can scale with it.
The Zion system is split into three distinct parts:
- 8-socket server
- 8-accelerator platform
- OCP accelerator module
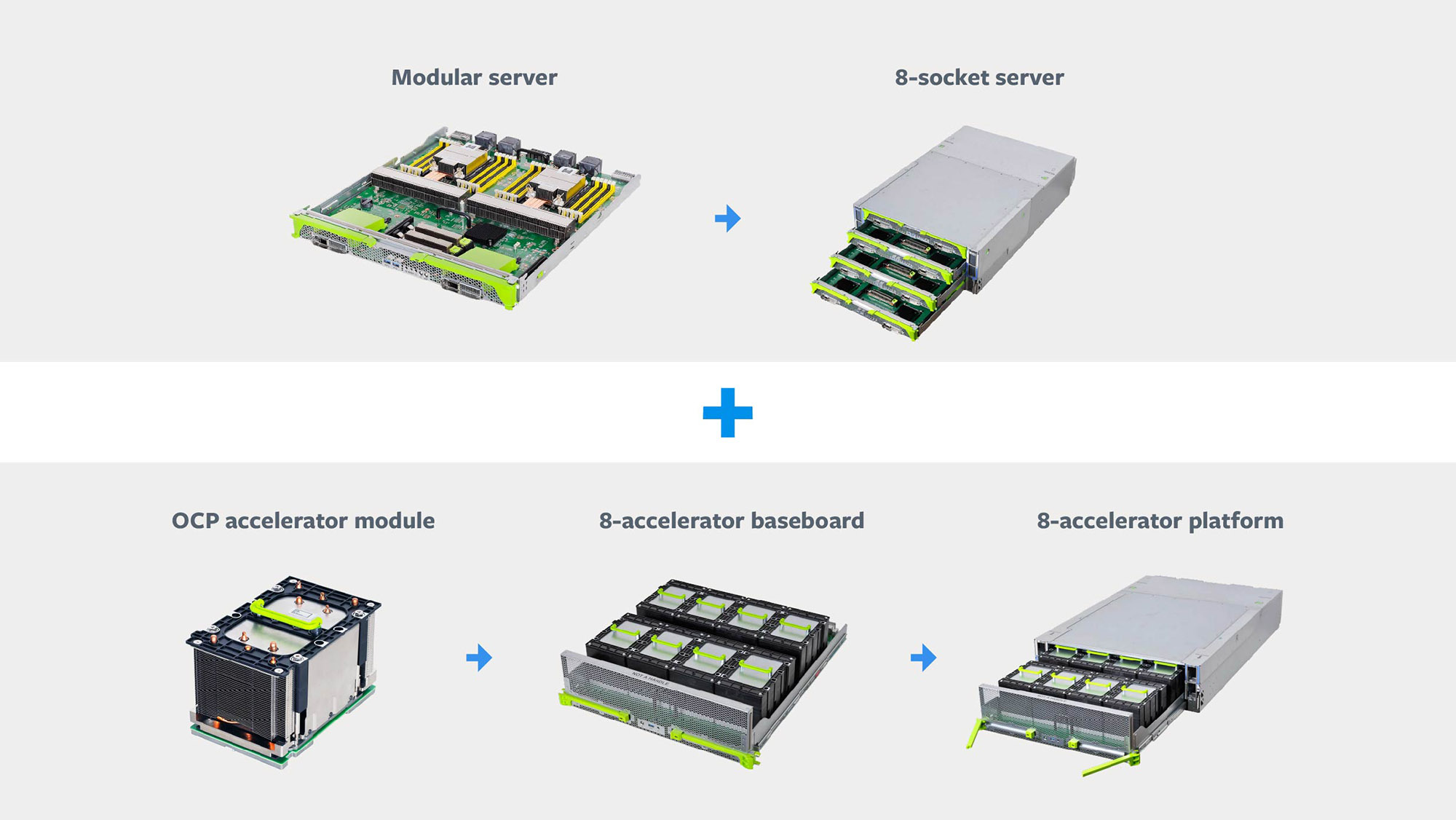
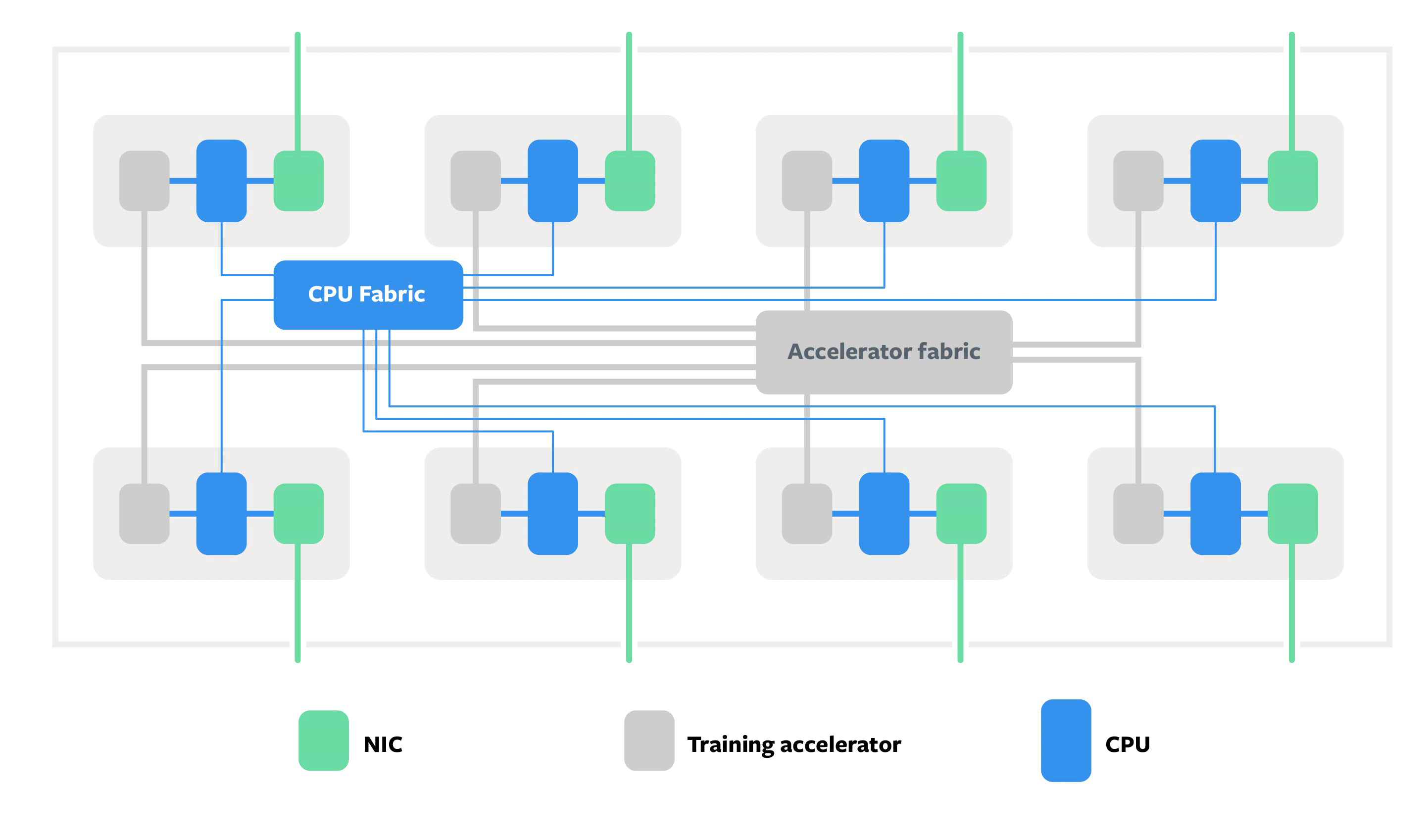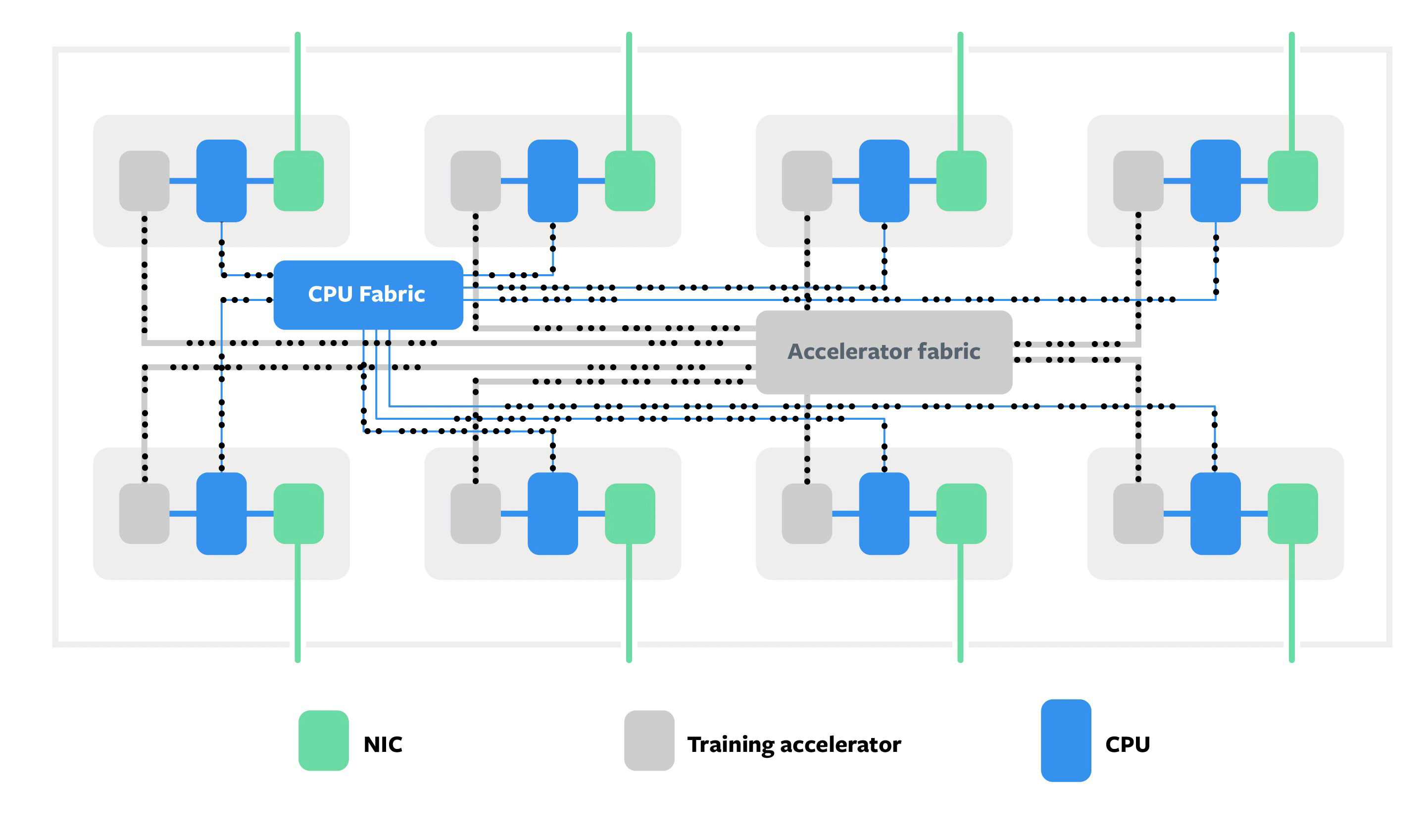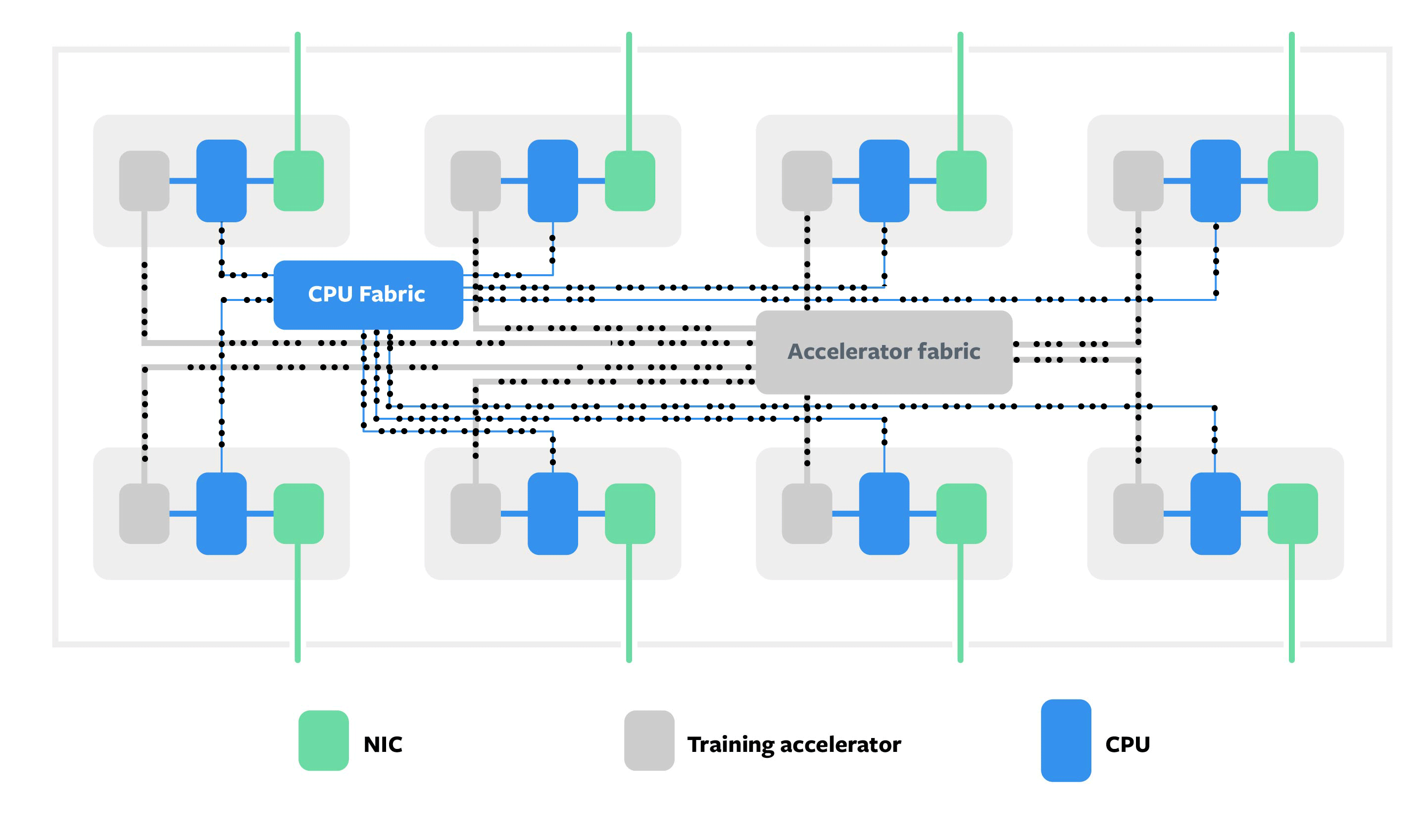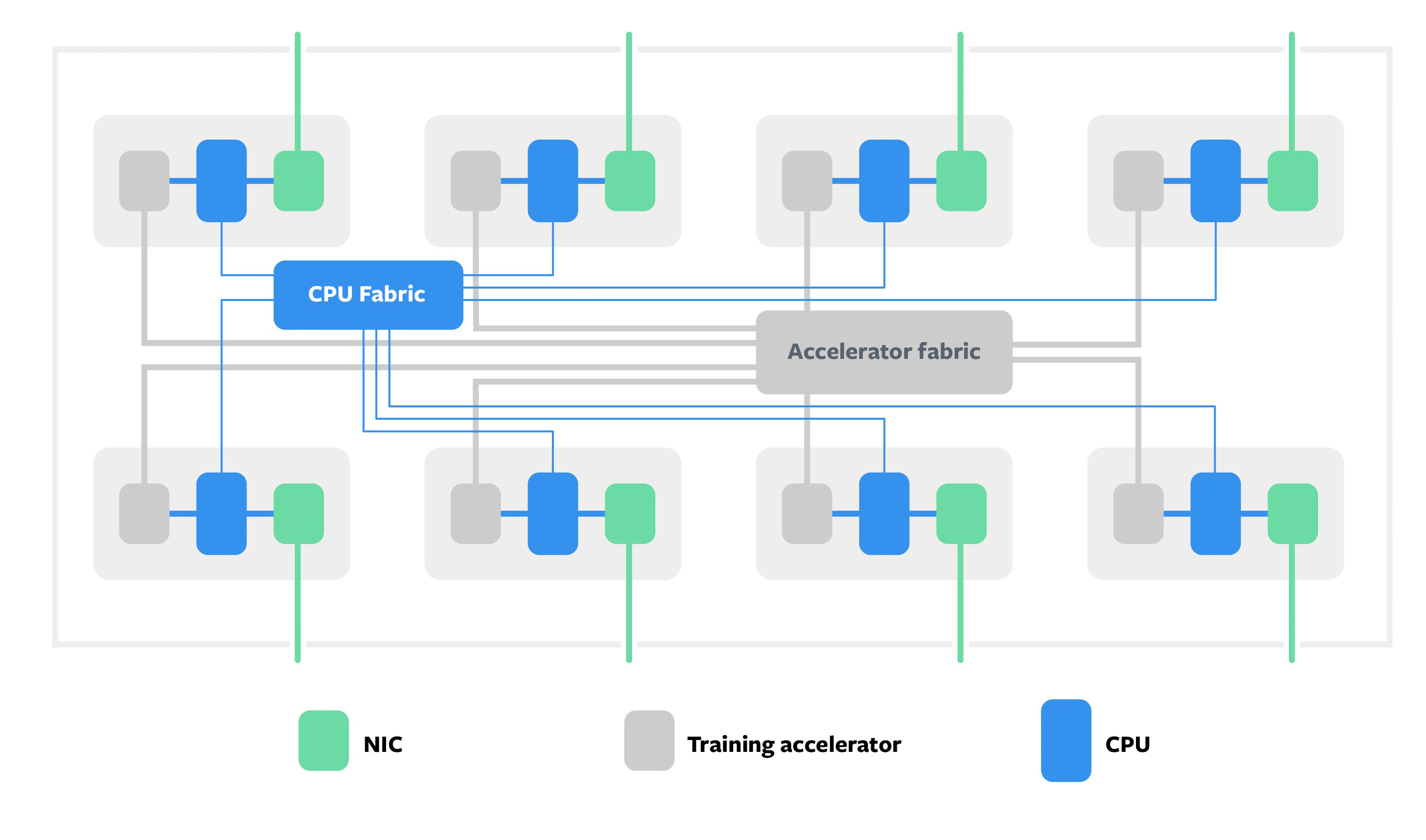
Zion decouples memory, compute, and network intensive components of the system, allowing each to scale independently. The system provides 8x NUMA CPU sockets with a large pool of DDR memory for memory-capacity-intensive components of the workloads, such as embedding tables of SparseNN. For memory-bandwidth-intensive and compute-intensive workloads such as CNNs or dense portions of SparseNN, there are OCP accelerator modules attached to each CPU socket.
The system has two high-speed fabrics: a coherent fabric that connects all CPUs, and a fabric that connects all accelerators. Since accelerators have high memory bandwidth, but low memory capacity, we want to effectively use the available aggregate memory capacity by partitioning the model in such a way that the data that is accessed more frequently resides on the accelerators, while data accessed less frequently resides on DDR memory with the CPUs. The computation and communication across all CPUs and accelerators are balanced and occurs efficiently though both high and low speed interconnects.
AI inference with Kings Canyon
Once a model has been trained, it is deployed to production to run against data flowing through our AI pipeline and respond to user requests. This is known as inference. Inference workloads are increasing dramatically, mirroring the increase in our training workloads, and the standard CPU servers we use today can not scale to keep up. We are collaborating with multiple partners, including Esperanto, Habana, Intel, Marvell, and Qualcomm, to develop ASICs for inference that are deployable and scalable in our infrastructure. These chips offer INT8 for workloads that need performance, as well as support for FP16, which enables higher precision.
The overall inference server solution is split into four distinct parts, which leverage existing building blocks that have already been released to OCP. Leveraging existing components allows us to accelerate the development time and reduces risk through commonality. The four main components of the design are:
- Kings Canyon inference M.2 modules
- Twin Lakes single-socket server
- Glacier Point v2 carrier card
- Yosemite v2 chassis
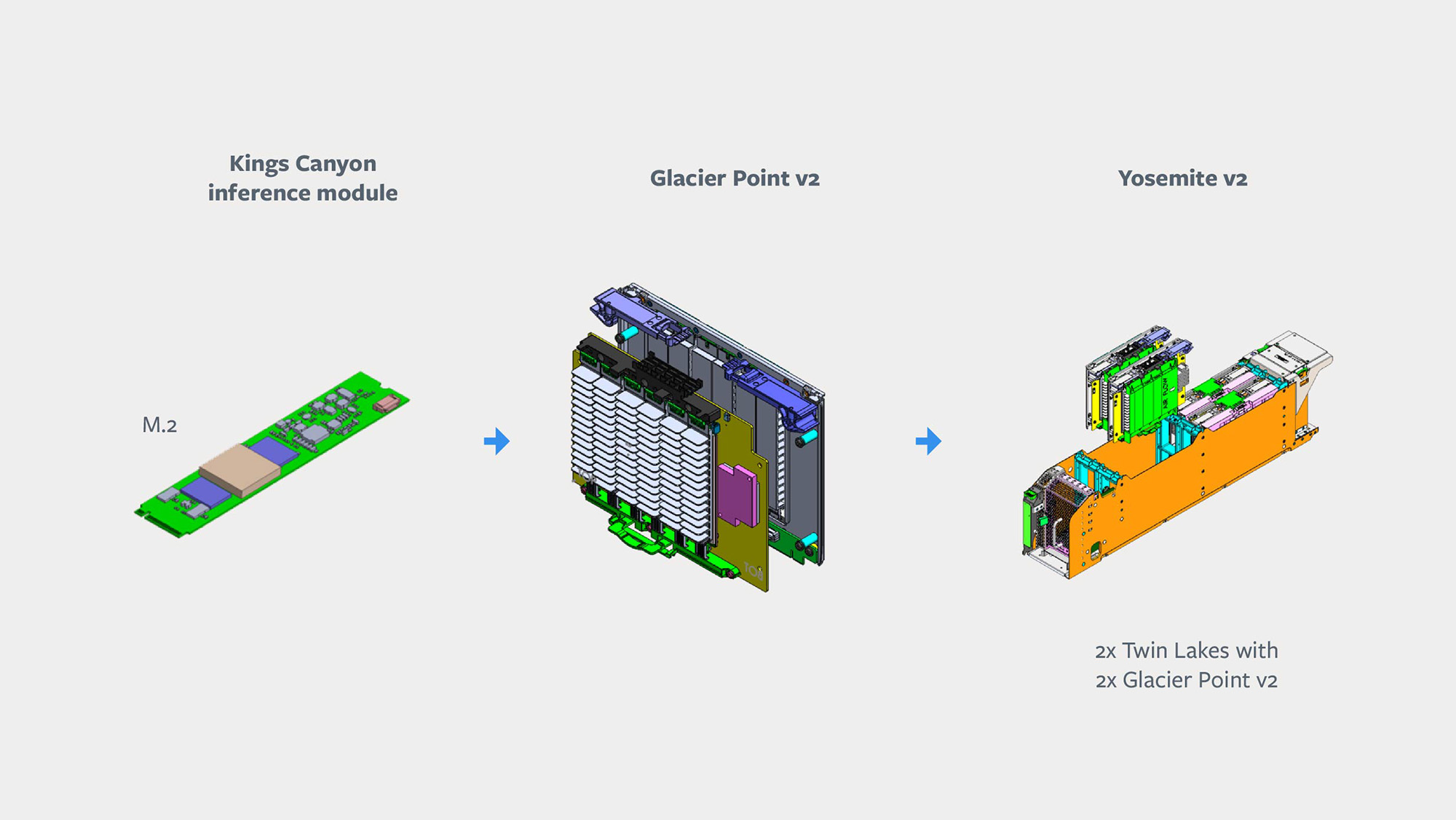
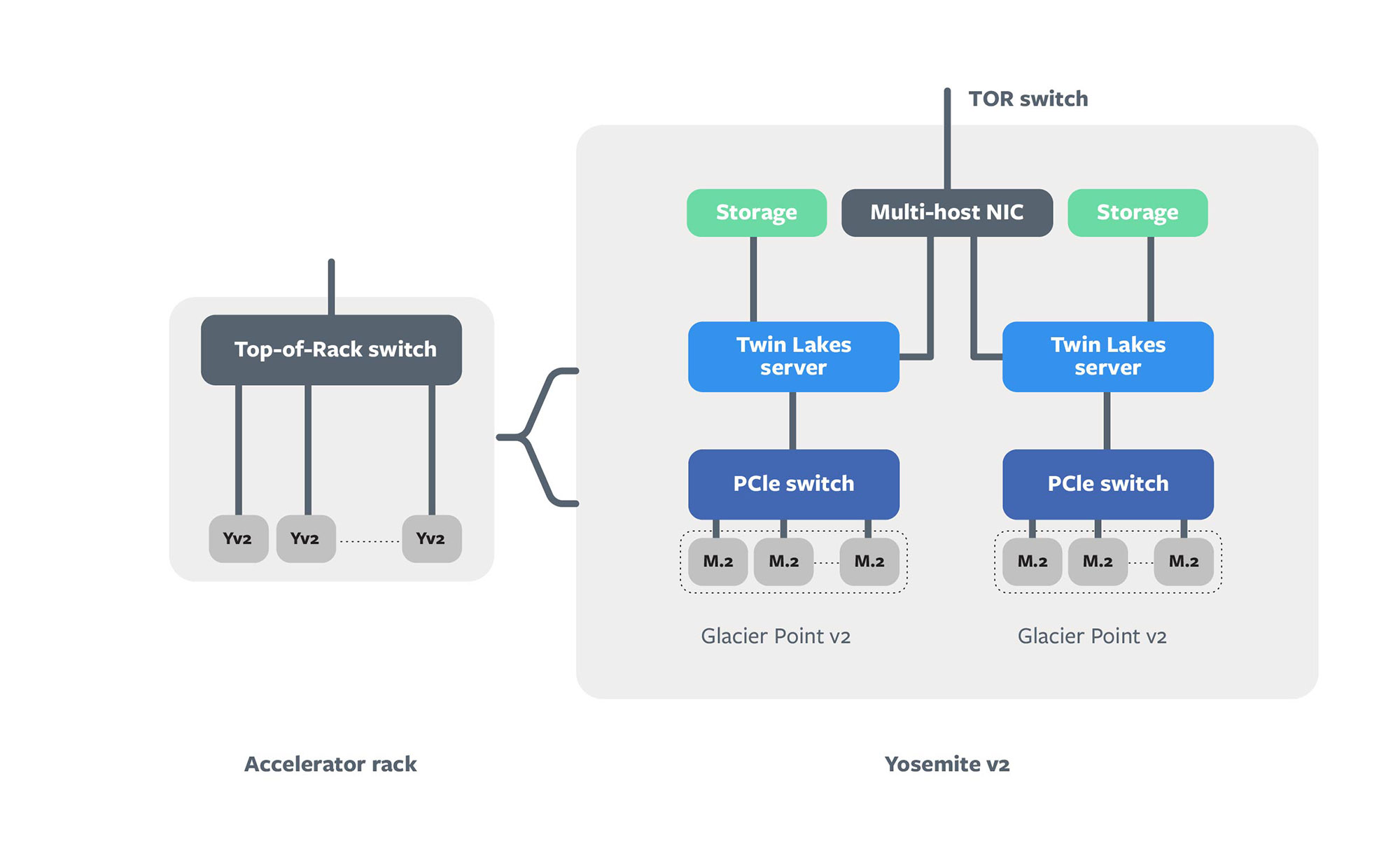
At the system level, each server is a combination of M.2 Kings Canyon accelerators and a Glacier Point v2 carrier card, which connect to a Twin Lakes server. Two sets of these components are installed into an updated Yosemite v2 sled and are then connected to the TOR switch via a multi-host NIC. The updated Yosemite sled is an iteration of our existing Yosemite v2 sled, which connects additional PCIe lanes from the Twin Lakes hosts to the NIC for higher network bandwidth. Each Kings Canyon module includes an ASIC, associated memory, and supporting components, and the CPU host communicates to the accelerator modules via PCIe lanes. The Glacier Point v2 includes an integrated PCIe switch to allow the server to access to all the modules at once.
Deep learning models have significant storage requirements. For example, SparseNN models have very large embedding tables, which consume many gigabytes of storage and will likely continue growing in size. Such large models may not fit into the memory of an individual device, whether CPU or accelerator, and will require model partitioning among multiple device memories. Partitioning will result in communication overhead when data is located in another device’s memory. A good graph-partitioning algorithm will try to capture the notion of locality to reduce this communication overhead.
With the proper model partitioning, we can run very large deep learning models. With SparseNN models, for example, if the memory capacity of a single node is not enough for a given model, we can further shard the model among two nodes, boosting the amount of memory available to the model. Those two nodes are connected via multi-host NICs, allowing for high-speed transactions. This will increase communication overhead, but we can leverage the fact that there is access variance across the many embedding tables and sort the tables accordingly.
Compiler for neural network hardware accelerators
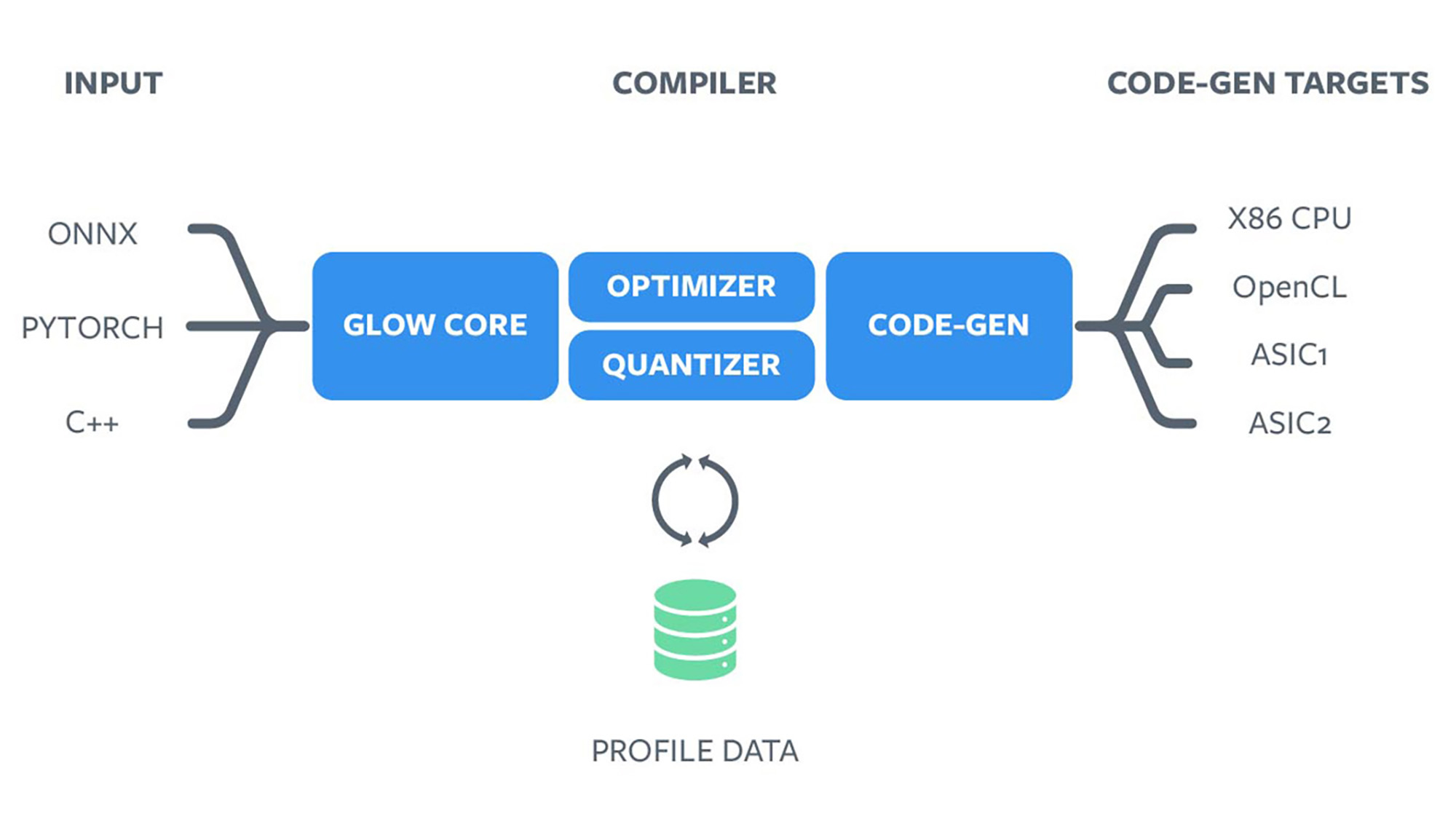
ASICs do not run general-purpose code. Hence they require a specialized compiler to translate the graph to instructions that execute on these accelerators. The objective of the Glow compiler is to abstract the vendor-specific hardware from the higher-level software stack to allow our infrastructure to be vendor agnostic. It accepts a computation graph from frameworks such as PyTorch 1.0 and generates highly optimized code for these ML accelerators.
Video transcoding with Mount Shasta
The average number of Facebook Live broadcasts has doubled each year since 2016. Since rolling out globally in August 2018, Facebook Watch has grown to more than 400 million monthly viewers — and 75 million use it every day. To optimize all of those videos for the viewer’s available internet connection, we generate multiple output qualities and resolutions (or bit rates), a process known as transcoding. The calculations required to complete this transcoding process are heavily compute-intensive, and general-purpose CPUs are not as efficient as we’ll need to scale our infrastructure for the growing number of videos. To stay ahead of that demand, we have partnered with silicon vendors Broadcom, and Verisilicon to design custom ASICs that are optimized for the transcoding workload.
The transcoding flow is broken into a number of distinct steps, outlined below in more detail. These are all run in software today, so to increase efficiency we have partnered with vendors to create custom ASICs that contain dedicated silicon for each stage of the transcoding workflow. Using special purpose hardware to complete these workloads makes the process more power-efficient and enables new functionality such as real-time 4K 60fps streaming. Individual video codecs are standardized and infrequently modified, so the lack of flexibility that is inherent with silicon chips isn’t a significant downside in this case.
The first stage of transcoding a video is called decoding, in which an uploaded file is decompressed to get raw video data, represented by a series of images. These uncompressed images can then be manipulated to change their resolution, known as scaling, and then encoded again using optimized settings to recompress them into a video stream. The output video is also compared with the original to calculate quality metrics, which are representative of the change in quality relative to the originally uploaded video. This is done on all videos to ensure that the encoding settings used produced a good-quality output. Videos are encoded and decoded using standards known as video codecs; H.264, VP9, and AV1 are popular examples in use today.
On an ASIC, the same sequence of steps is followed, except each of the software algorithms is replaced with dedicated silicon within the chip. On average, we expect our video accelerators to be many times more efficient than our current servers. We would like the industry to target encoding at least 2x 4K at 60fps input streams in parallel within a 10W power envelope. The ASICs also need to support multiple resolutions, from 480p to 4K at 60fps, and multiple encoding formats, from H.264 to AV1.
Video transcoding ASICs typically have the following main logic blocks:
- Decoder – Accepts uploaded video; outputs uncompressed RAW video stream
- Scaler – Block to resize (shrink) the uncompressed video
- Encoders – Outputs compressed (encoded) video
- Quality measurement – Logic to measure the degradation in video quality after the encoding step
- PHYs – Interface between the chip and outside world; connects to PCIe for the server and DDR for the memory
- Controller — General-purpose block that runs the firmware and coordinates the transcoding flow
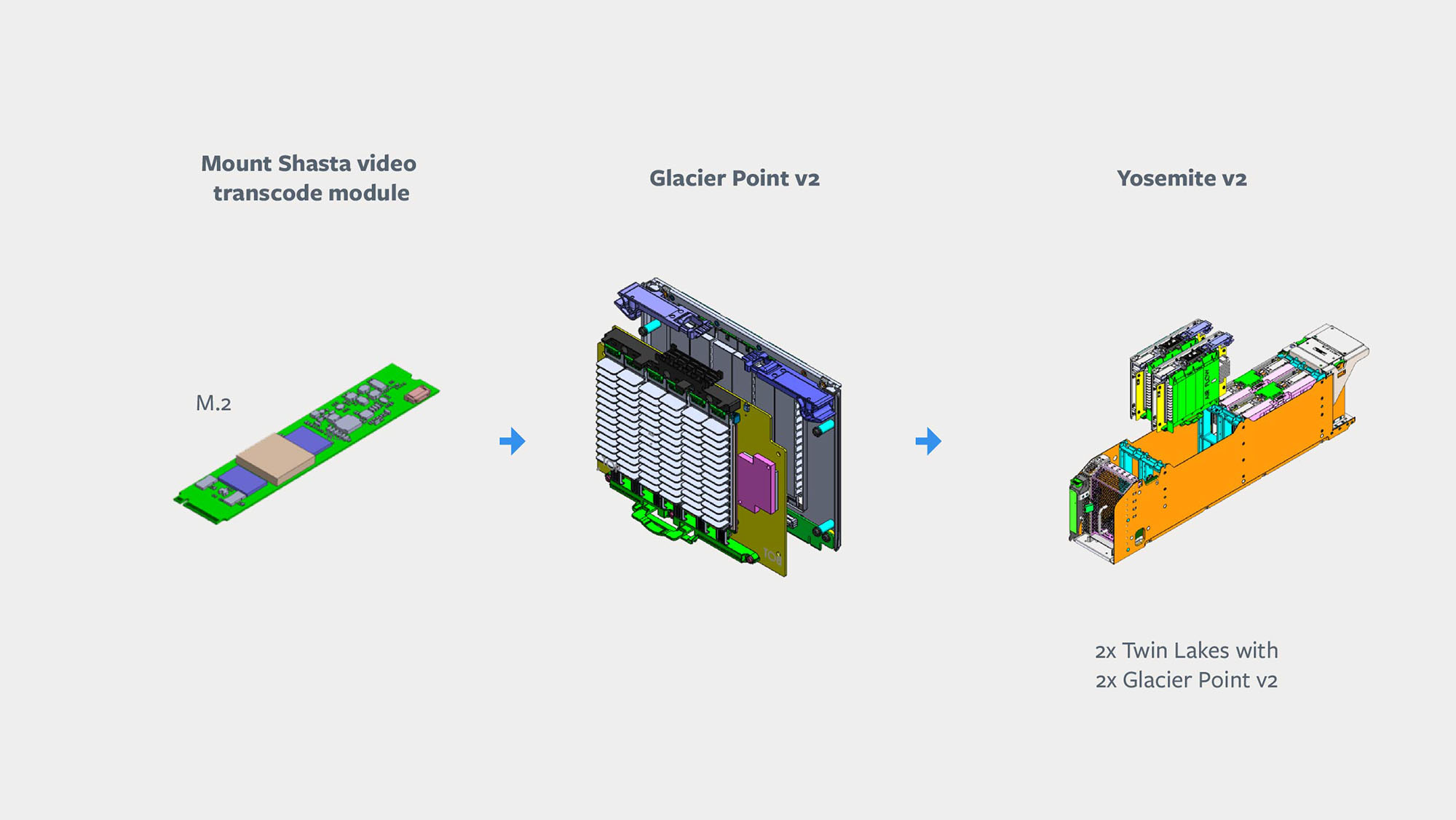
As with inference, we are leveraging existing OCP building blocks to deploy these transcoding ASICs within our data centers. The ASICs will be installed on M.2 modules with integrated heat sinks, as this common electrical form factor allows potential reuse across different hardware platforms. They are installed in a Glacier Point v2 (GPv2) carrier card that can house multiple M.2 modules. This GPv2 carrier card has the same physical form factor as a Twin Lakes server, meaning that it can fit into the Yosemite v2 chassis, where it will pair up with a Twin Lakes server.
Since the transcoding ASICs have low power requirements and are physically small, we want to optimize cost savings by connecting as many chips to a single server as possible. The high density of GPv2 enables this while also providing sufficient cooling to withstand data center operating temperatures.
Once we have completed our software integration work, we will be able to support balancing our video transcoding workloads across a heterogeneous hardware fleet distributed across our diverse data center locations. To help us scale as we work with a range of vendors across the ML and video spaces, we are also working to ensure that software is developed in an open fashion, and to promote and adopt common interfaces and frameworks.
Next steps
Exciting times are ahead for us. We expect that our Zion, Kings Canyon, and Mount Shasta designs will address our growing workloads in AI training, AI inference, and video transcoding respectively. We will continue to improve on our designs through hardware and software co-design efforts, but we cannot do this alone. We welcome others to join us in in the process of accelerating this kind of infrastructure. All designs and specifications will be publicly available through the OCP.








