
Our infrastructure supports thousands of services that handle billions of requests per second. We’ve previously discussed how we built our service encryption infrastructure to keep these globally distributed services operating securely and performantly. This post discusses the system we designed to enforce encryption policies within our network and shares some of the lessons we learned in the process. The goal of this enforcement is to catch any regression quickly and shut it off, keeping our internal traffic secure at the application level via TLS.
Organizational challenges
Implementing a transit encryption enforcement policy at Facebook scale requires careful planning and communication, in addition to the technical challenges we’ll discuss in a bit. We want the site to stay up and remain reliable so the people using our services will be unaffected by and unaware of any changes to the infrastructure.
Communicating the intent, specific timelines, and rollout strategy went a long way toward minimizing any potential disruptions for the thousands of teams that run services at Facebook. We use Workplace within Facebook, which enables us to easily distribute that information across a variety of groups with a single share button and consolidate feedback and concerns in a single place for all employees to see. We made sure to include the following:
- A description of the impact of our enforcement mechanism and how it might appear at the application layer
- A dashboard for engineers to see whether their traffic would be affected
- The rollout and monitoring plan
- Dedicated points of contact and a Workplace group where users could ask questions about impact and troubleshoot any issues
The post required multiple discussions within the team to come up with a rollout plan, dashboard requirements, and realistic timelines to meet the goals of the project. This level of communication proved to be useful as the team gathered important feedback early in the process.
Building our SSLWall
Hardware choke points are a natural approach to providing transparent enforcement. There are options, such as layer 7 firewalls, that let us do deep packet inspection, but executing fine-grained rollouts and the complexities of Facebook’s network would make implementing such a solution a nightmare. Additionally, working at a network firewall level would introduce a much larger blast radius of impacted traffic, and a single configuration issue could end up killing off traffic that we weren’t meant to touch.
Our team decided to develop and deploy what is internally known as SSLWall, a system that cuts off non-SSL connections across various boundaries. Let’s dive a bit into the design decisions behind this solution.
Requirements
We needed to be thorough when considering the requirements of a system that would potentially block traffic at such a large scale. The team came up with the following requirements for SSLWall, all of which had an impact on our design decisions:
- Visibility into what traffic is being blocked. Service owners needed a way to assess impacts, and our team needed to be proactive and reach out whenever we felt there was a problem brewing.
- A passive monitoring mode in which we could turn a knob to flip to active enforcement. This helps us determine impacts early on and prepare teams.
- A mechanism to allow certain use cases to bypass enforcement, such as BGP, SSH, and approved network diagnostic tools.
- Support for cases like HTTP CONNECT and STARTTLS. These are instances that do a little bit of work over plaintext before doing a TLS handshake. We have many use cases for these in our infrastructure, such as HTTP tunneling, MySQL security, and SMTP, so these must not break, especially since they eventually encrypt the data with TLS.
- Extensible configurability. We might have different requirements depending on the environment in which SSLWall operates. Additionally, having important knobs that can be tuned with little disruption means we can roll features forward or back at our own pace.
- Transparent to the application. Applications should not need to rebuild their code or incur any additional library dependencies for SSLWall to operate. The team needed the ability to iterate quickly and change configuration options independently. In addition, being transparent to the application means SSLWall needs to be performant and use minimal resources without having an impact on latencies.
These requirements all led us down the path of managing a host-level daemon that had a user space and kernel-level component. We needed a low-compute way to inspect all connections transparently and act on them.
eBPF
Since we wanted to inspect every connection without needing any changes at the application level, we needed to do some work in the kernel context. We use eBPF extensively, and it provides all of the capabilities needed for SSLWall to achieve its goals. We leveraged a number of technologies that eBPF provides:
- tc-bpf: We leveraged Linux’s traffic control (TC) facility and implemented a filter using eBPF. At this layer, we are able to do some computation on a per-packet basis for packets flowing in and out of the box. TC allows us to operate on a broader range of kernels within Facebook’s fleet. It wasn’t the perfect solution, but it worked for our needs at the time.
- kprobes: eBPF allows us to attach programs to kprobes, so we can run some code within the kernel context whenever certain functions are called. We were interested in the tcp_connect and tcp_v6_destroy_sock functions. These functions are called when a tcp connection is established and torn down, respectively. Old kernels played a factor in our use of kprobes as well.
- maps: eBPF provides access to a number of map types, including arrays, bounded LRU maps, and perf events
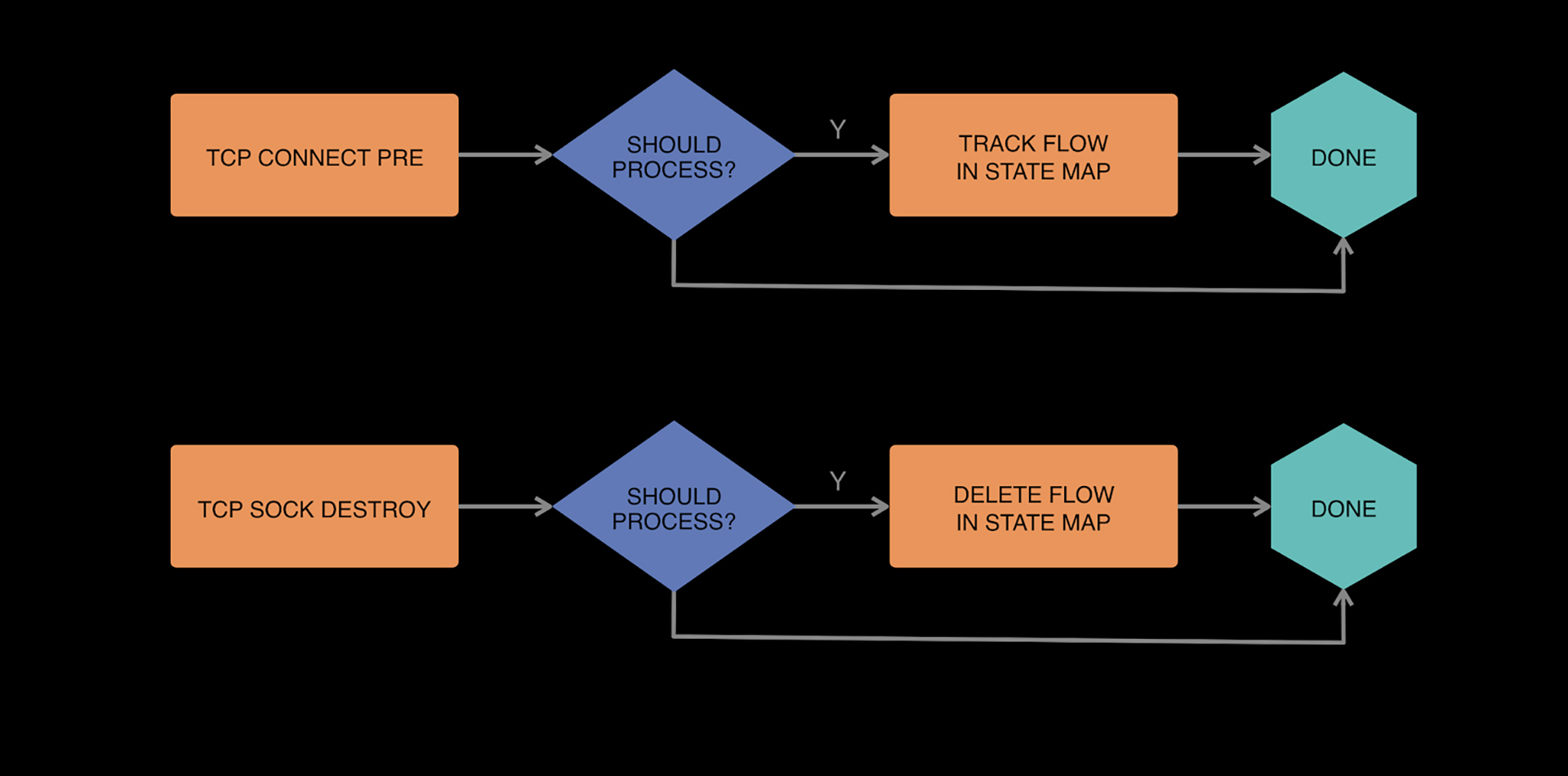
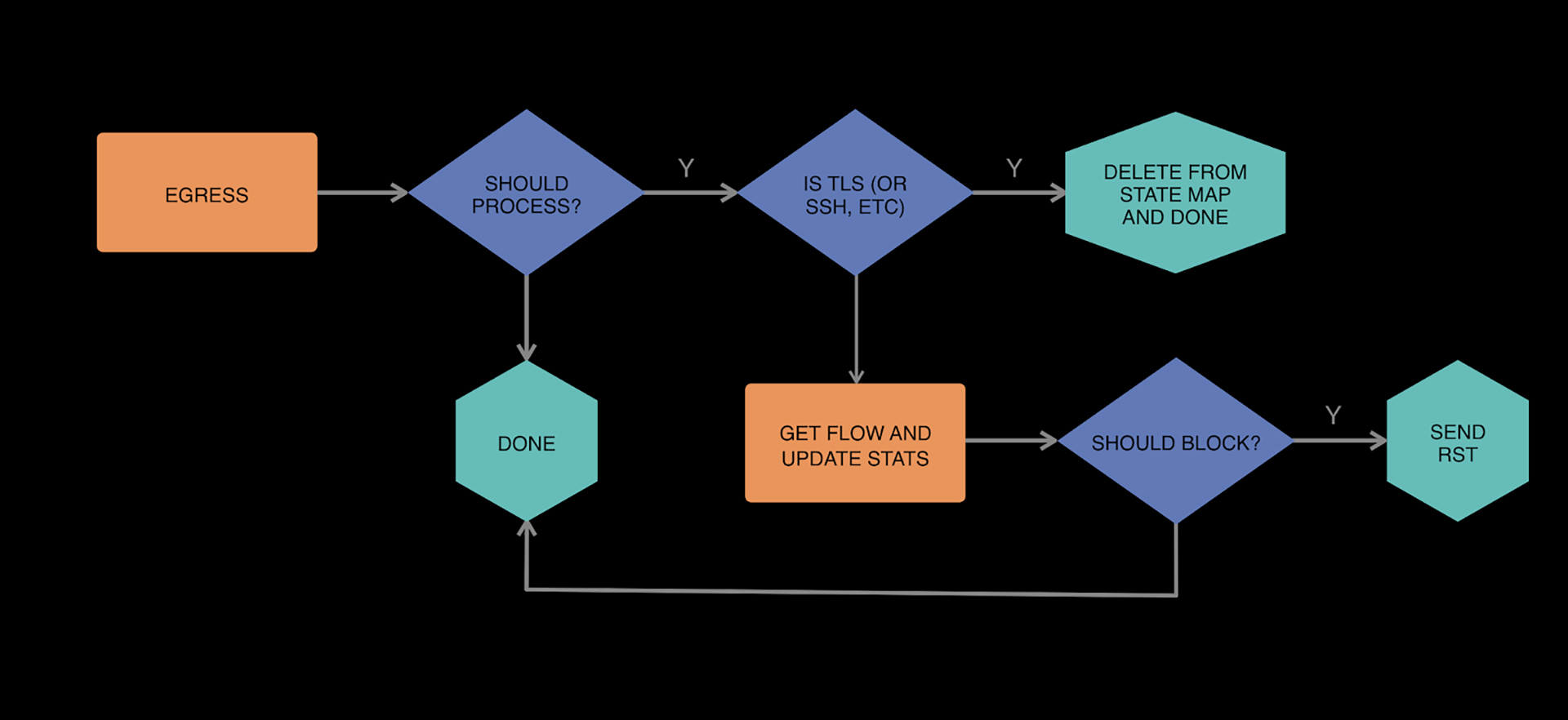
The management daemon
We built a daemon, which manages the eBPF programs we install and emits logs to Scribe from our perf events. The daemon also provides the ability to update our TC filter, handles configuration changes (leveraging Facebook’s Configerator), and monitors health.
Our eBPF programs are also bundled with this daemon. This makes management of releases easier to deal with, as we only have one software unit to monitor instead of needing to track a daemon and eBPF release. Additionally, we can modify the schema of our BPF tables, which both user space and kernel space consult, without compatibility concerns between releases.
Technical challenges
As one would expect, we encountered a number of interesting technical challenges while rolling out SSLWall at Facebook’s scale. A few highlights include:
- TCP Fast Open (TFO): We hit an interesting challenge around kprobe and TC filter execution order that was exposed by our use of TFO within the infra. In particular, we needed to move some of our flow tracking code to a kprobe prehandler.
- BPF Program Size Limit: All BPF programs are subject to size and complexity limits, which may vary based on the kernel version.
- Performance: We spent many engineering cycles optimizing our BPF programs, particularly the TC filter, so that SSLWall’s CPU impact on some of our critical high QPS services with high fanout remained trivial. Identifying early exit conditions and using BPF arrays over LRUs where possible proved effective.
TransparentTLS and the long tail
With enforcement in place, we needed a way to address noncompliant services without significant engineering time. This included things like torrent clients, open source message queues, and some Java applications. While most applications use common internal libraries where we could bake this logic in, the ones that do not need a different solution.
Essentially, the team was left with the following requirements for what we refer to as Transparent TLS (or TTLS for short):
- Transparently encrypt connections without the need for application changes.
- Avoid double encryption for existing TLS connections.
- Performance can be suboptimal for this long tail.
It’s clear that a proxy solution would have helped here, but we needed to ensure that the application code didn’t need to change and that configuration would be minimal.
We settled on the following architecture:
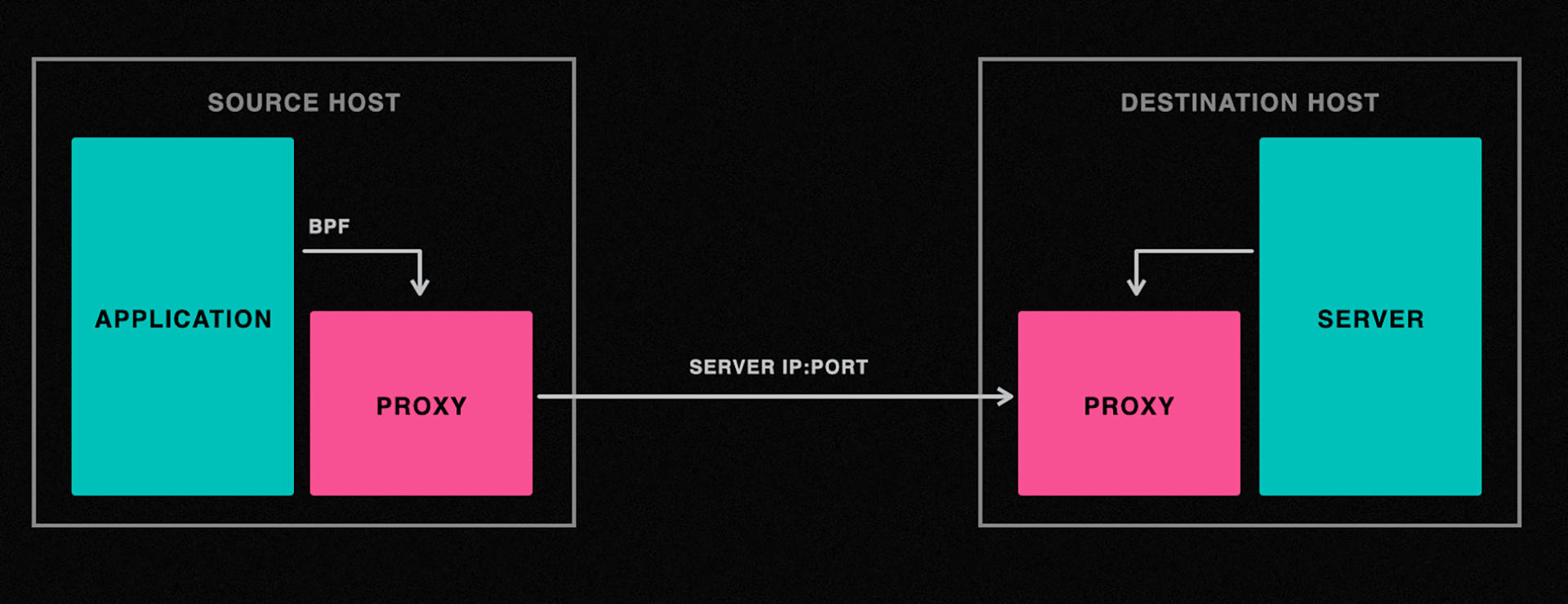
The challenge with this approach is transparently redirecting application connections to the local proxy. Once again, we use BPF to solve this problem. Thanks to the cgroup/connect6 hook, we can intercept all connect(2) calls made by the application and redirect them to the proxy as needed.
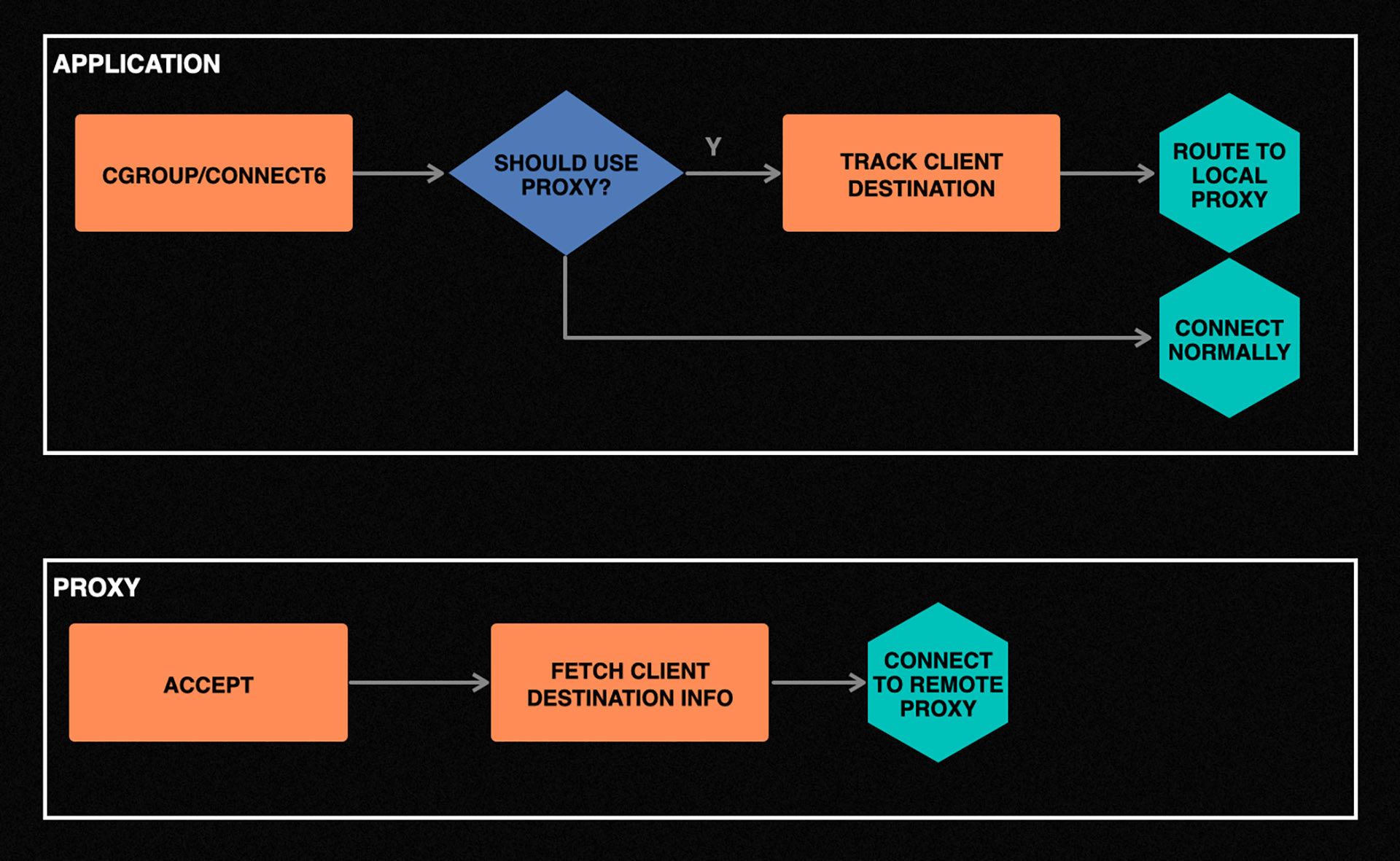
Aside from the application remaining unchanged, the BPF program makes policy decisions about routing through the proxy. For instance, we optimized this flow to bypass the proxy for all TLS connections created by the application to avoid double encryption.
This work on enforcement has brought us to a state where we can confidently say that our traffic is encrypted at our scale. However, our work is not yet complete. For instance, there are many new facilities that have come about in BPF that we intend to leverage as we remove old kernel support. We can also improve our transparent proxy solutions and leverage custom protocols to multiplex connections and improve performance.
We’d like to thank Takshak Chahande, Lingnan Gao, Andrey Ignatov, Petr Lapukhov, Puneet Mehra, Kyle Nekritz, Deepak Ravikumar, Paul Saab, and Michael Shao for their work on this project.








