
In any emergency or crisis, sending and receiving real-time alerts efficiently and at scale is mission critical. One of the reasons Facebook’s Safety Check feature has been successful is because of its ability to immediately identify those likely to be in an affected area, collect their safety status, and send that information out to friends and family in real time.
Facebook Enterprise Engineering has developed a similar feature for companies via our Workplace business collaboration tool. Safety Check for Workplace incorporates important modifications to enable management by a company’s designated security team and to ensure accuracy even when multiple companies are affected simultaneously, as is likely in the case of a major crisis.
How Safety Check for Workplace functions
In Workplace, designated Safety Operators create and send out a Safety Check notification to their work community in a three-step process:
- Locate: Identify whom the crisis may affect.
- Notify: Alert affected employees via Workplace Chat, a post atop their News Feed, push notifications, and email. Ask them to confirm whether they are safe or need assistance.
- Iterate: Continue attempting to make contact with any who are not yet confirmed safe — through different channels until everyone is accounted for.
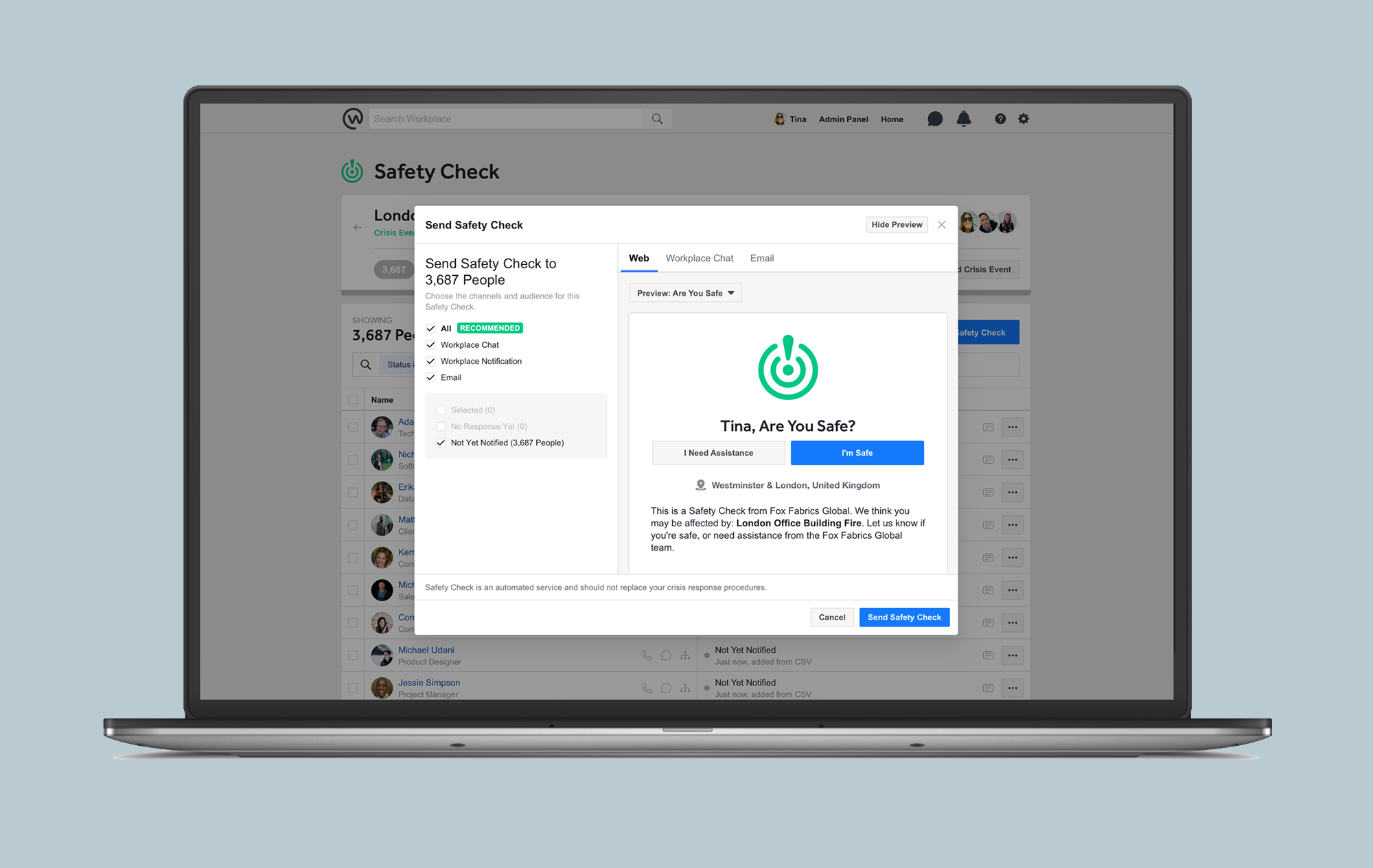
To ensure that the right people in an organization (i.e., security or human resources) manage Safety Check for Workplace, a company’s system administrators enable the tool, and can then designate a safety team.
Evolving an internal tool into an external product at scale
The idea for this Workplace feature began at a company hackathon in our London office. As we thought about how our external customers might use Safety Check for Workplace, we had to reevaluate our entire design with enhanced scale, speed, and accuracy for enterprises in mind. We realized this would require some new design considerations and a revision of the entire product for the Workplace platform.
At its core, our internal tool was built on a database that was not scalable for a product which might need to support millions of people across multiple companies. To address this, we moved our storage to TAO, Facebook’s distributed data store for the social graph, where Workplace information resides. With the move to an external product, we could no longer rely on our standard internal access management and data security controls. So we created our own module for access management and strong privacy checks. As we continued our journey to build a life safety system at scale, we focused on three major parts of the product workflow: locate, notify, and iterate.
Locate
Once a crisis response is initiated, security or human resources staff must first locate the people who are affected. Security and HR staff pull from a range of different and unique sources for their seated and traveling employees. We quickly realized that we want to augment that data with systemic ways of locating people.
Our next step was to pick the Workplace profile location, as populated by the respective company, as one of the main sources of information. Our primary problem is that this field is free-form text, and every company can have its own text. As a result,we could not guarantee valid locations. To solve for that, we created a location parser, which can run for a given company and try to index all its locations. These indexed locations would be used, along with the crisis location, to locate employees.
Given that more locator information might be collected on the platform in the future, we implemented our locate classes as extendable. For our internal use case, we are able to extend the systematic locate function by connecting to other internal tools such as the travel system, calendar, etc. It is critical to reduce the process time to ensure that people are located and added to the crisis as quickly as possible. We create multiple asynchronous jobs that run simultaneously to locate and add people to the crisis based on the crisis location. Using TAO as a backend helps us make the parallel writes work faster across multiple shards.
Notify
To increase the reach to affected people, we implement the notifications across many channels and surfaces: We span the notification jewel, post on top of the feed, chat, and email across platforms such as web, mobile, and mobile site. We use the standard notification framework, which processes millions of notifications for all of the Facebook and Workplace notifications.
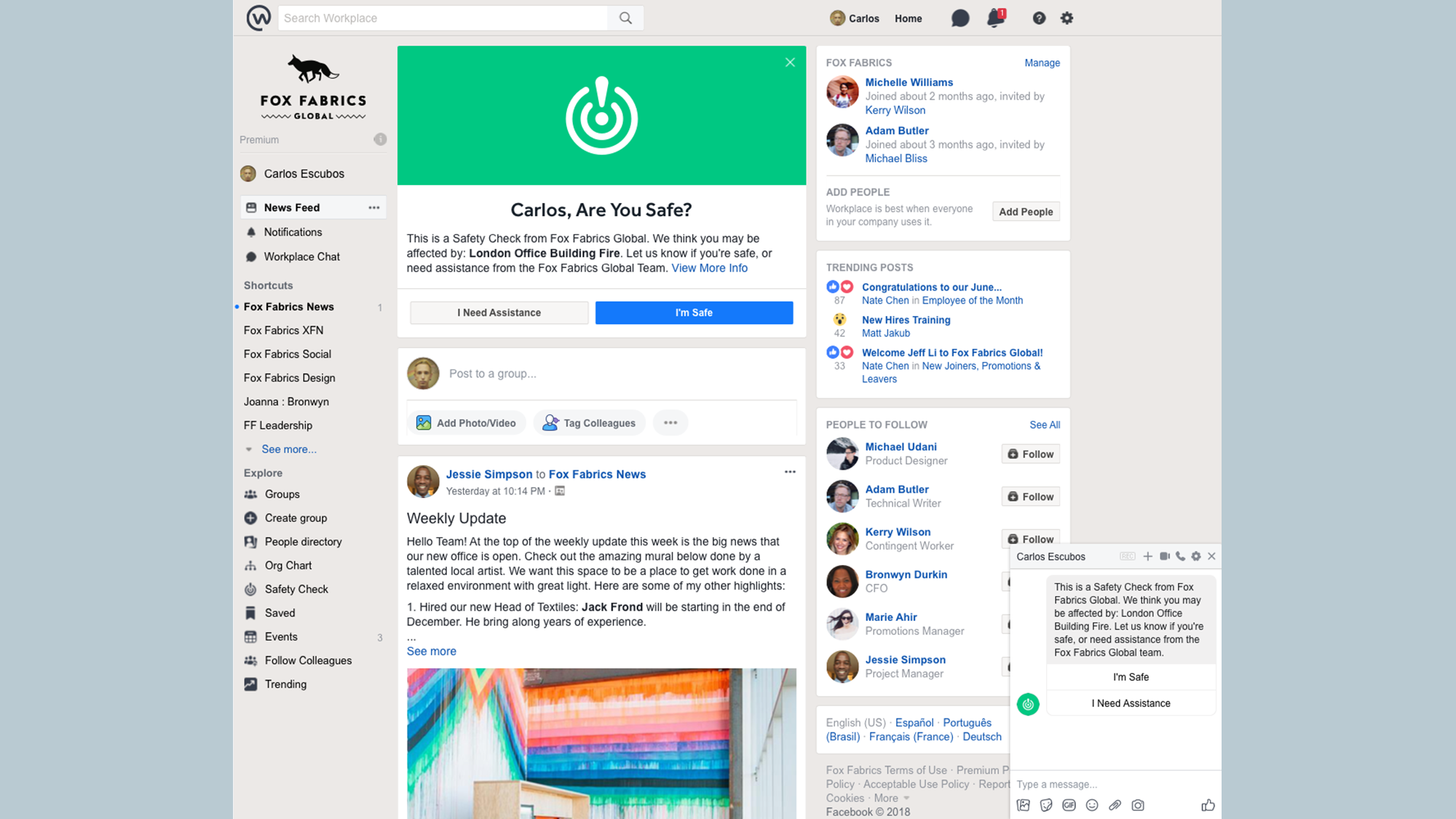
This multichannel distribution for large numbers of people can result in large volumes of responses. Every time a security or HR administrator sends a notification, it goes to our generalized worker pool of machines, called the “async tier,” which handles creating and executing our notify jobs. Initially, we designed a single job to process some fixed number of notifications, but we quickly noticed that we needed special handling for all failures. As a result, we altered our design to one job per person, which makes it very easy to manage high volumes of jobs with straightforward retry logic in case of failures. We also fan out the async jobs across different batches while still ensuring all notifications are sent within seconds. For bot notifications, we use Workplace Chat, which is built off of our Messenger infrastructure, allowing us to send notifications reliably and scale well beyond our immediate needs.
Iterate
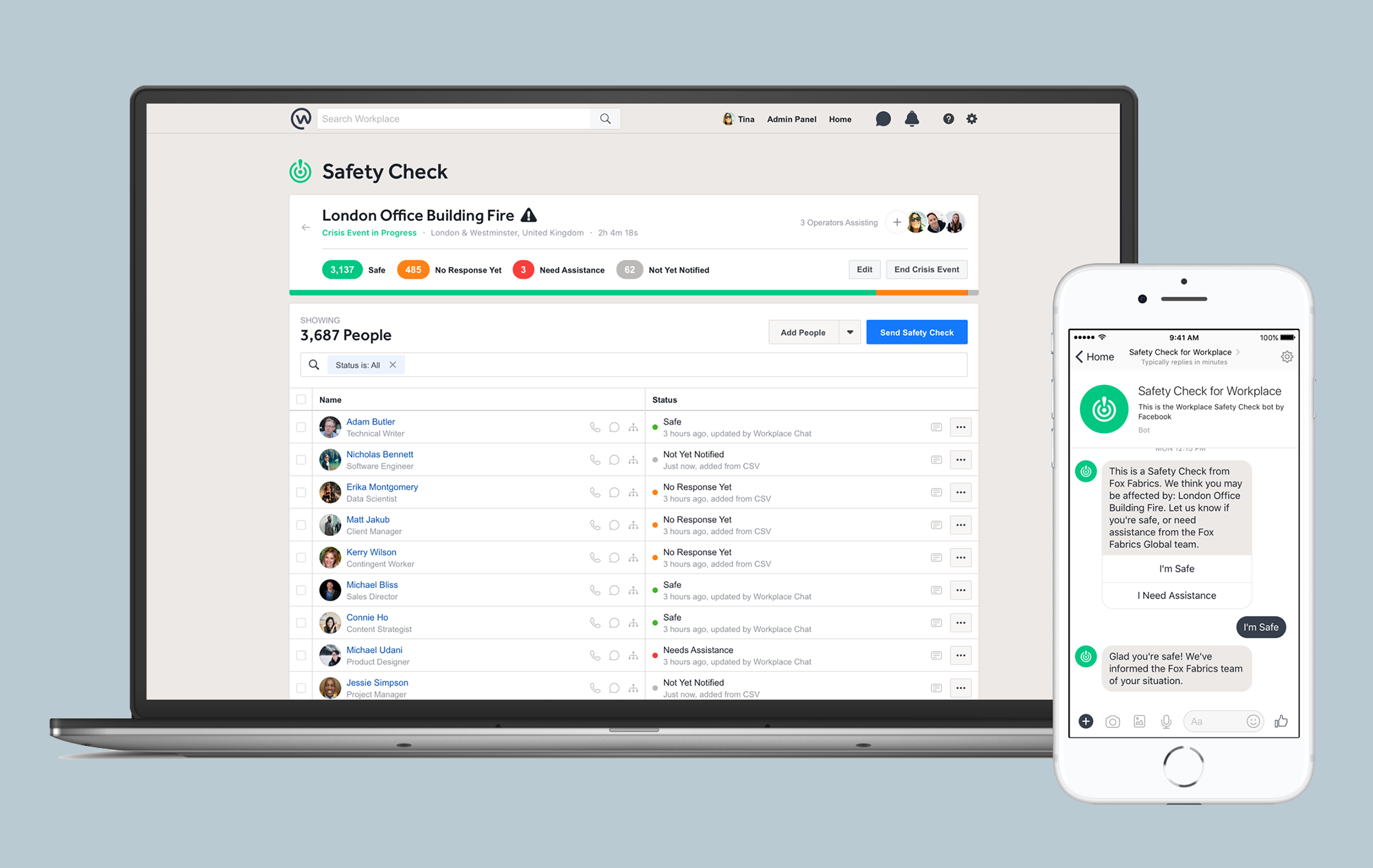
As designated security operators use Safety Check to locate, notify, and iterate, we have an additional technical challenge to solve how we handle responses. An important consideration is to ensure that the counts fully match the responses in real time. To do this, we store people’s statuses as edges on a graph to a Safety Check, for quick and accurate querying. Furthermore, when dealing with high request volume, we funnel all the requests via a queuing system to make sure we don’t lose any numbers, but we update the actual status immediately to provide current information for security and HR teams.
This system is built with our open source technologies such as React, Relay, GraphQL, and Hack. Our status updates leverage the GraphQL subscription, which, as part of page load, subscribes to all status change events so they update in real time.
Building on what we do with Safety Check for the Facebook community, we also perform extensive simulations to assess resiliency for extreme notification and response workloads. These simulations are run programmatically to ensure we continually test the underlying infrastructure and services on which we rely. We do this through scripts that run at various times throughout the day (as a crisis can occur at any time in any place) on a test instance that creates a crisis, locates large volumes of people, notifies them, and receives random spikes of responses.
With Safety Check for Workplace, we have a tool that started at a hackathon in London and has evolved into an enterprise employee safety feature. We’re excited to make it available to Workplace Premium users in the coming months. For more details, please visit facebook.com/workplace.








