In the past eight years, we’ve broken ground on 15 data centers around the world. During this time, the number of people using Facebook every month topped 2.2 billion. Those people are all sharing memories through posts, images, and videos. Initially, we were able to ensure low-latency, continuous access for everyone by storing replicas of the entire data set in each data center region. But as we continue to grow, that solution is no longer scalable.
To help solve this problem, Facebook developed Akkio, a new data placement service (DPS) that operates on trillions of small entities to determine how and when to move information in order to optimize retrieval speed for people across the globe, using the minimum required number of copies. Developed over the last three-plus years and leveraging Facebook’s unique software stack, Akkio is now in limited production and delivering on its promise with a 40 percent smaller footprint, which resulted in a 50 percent reduction of the corresponding WAN traffic and an approximately 50 percent reduction in perceived latency.
Where to place the information?
Akkio helps reduce data set duplication by splitting the data sets into logical units with strong locality. The units are then stored in regions close to where the information is typically accessed. For example, if someone on Facebook accesses News Feed on a daily basis from Eugene, Oregon, it is likely that a copy is stored in our data center in Oregon, with two additional copies in Utah and New Mexico. The three data centers are in proximity to one another, providing for comparable end user latencies in case of regular traffic shifts, as well as disaster recovery. By having Akkio optimize where to store these copies — rather than storing copies in every region — we can reduce storage and drastically drive down the cross-region network usage caused by data replication and save significant network capacity.
What makes this complicated is that these mappings are fluid; they change according to traffic variations. If the Prineville Data Center becomes overloaded with traffic requests, then we might serve people on the West Coast from a different region. Most people accessing Facebook stay within a small, fairly predictable group of no more than two or three regions. To satisfy fault tolerance requirements, we typically need a few copies, spread to three regions. Using fewer copies not only reduces our storage footprint and cross-data center traffic, but for each new region going forward, it also eliminates the need for additional capacity to maintain our data access service level agreements. We can simply move capacity from existing regions to the new region. These returns and added efficiency have been impressive at the Facebook size and scale; it is unlikely that smaller organizations would have the same results.
What about caching?
A common strategy to obtain localized data access is to deploy a distributed cache at each data center. While caching works well in certain scenarios, in practice this alternative is ineffective for most of the workloads important to Facebook:
- First, low read-write ratios lead to excessive communication over cross-data center links, because the data being cached will constantly be invalidated through frequent writes.
- Second, many of the data sets accessed by our services require strong consistency. While providing strongly consistent caches is possible, it significantly increases the complexity of the solution, and it incurs a large amount of extra cross-data center communication, further exacerbating WAN latency overheads. It is notable that the widely popular distributed caching systems that are scalable, such as Memcached or Redis, do not offer strong consistency. And for good reason.
- Finally, unless the cache hit rate is extremely high, average access latencies will be high if the target data is not located in the local data center.
Akkio’s architecture
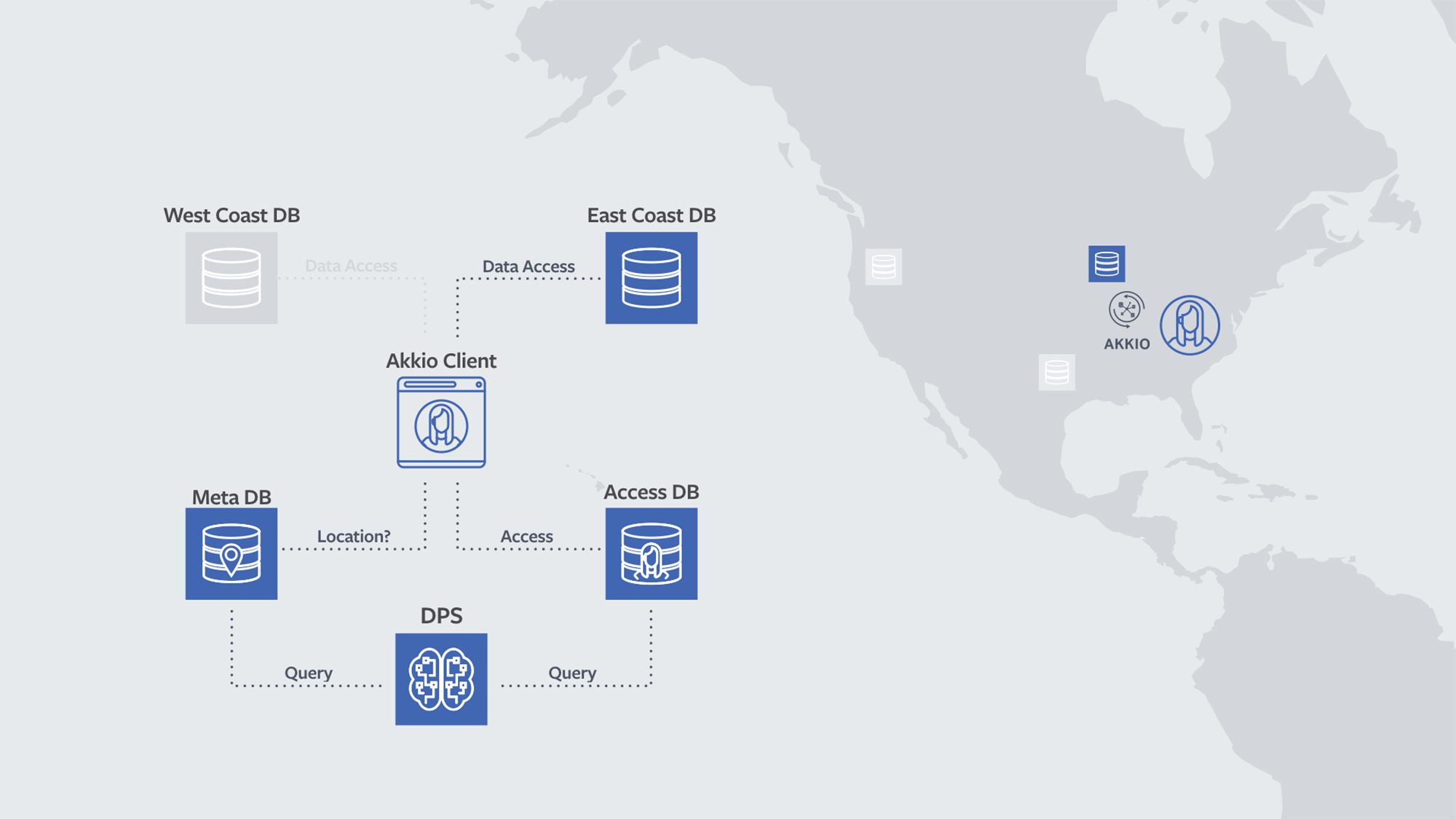
The Akkio metadata database
The unit of data management in Akkio is called a microshard. Each microshard is defined to contain related data that exhibits some degree of access locality with client applications. Akkio can easily support trillions of microshards. For example, for services that store user information, each person can be in his or her own microshard.
Akkio optimizes data placement, so when the backend client gets a request from the application service to act on a particular microshard, it needs to know where the data is placed. The Akkio metadata tier stores a mapping from a microshard to its physical placement that is looked up by the Akkio client on every access to the microshard.
The backend client talks to the Akkio client, which does the lookup and passes back the placement. The encoding of the placement is opaque, as far as Akkio is concerned: just a bunch of bytes that are passed back to the client. The placement itself can be a shard prefix, or it can be an actual shard, or it can be a region — in fact, it can be whatever the backend wants. The only thing that Akkio needs to know, for every placement option, is the set of data centers associated with it. The backend service needs to tell Akkio all the available placements and associated regions.
Storing access patterns
When making data placement decisions, Akkio needs to understand how the data is being accessed currently, as well as how it has been accessed in the recent past. These access patterns are stored in the Akkio Access DB. Although we store 10 days’ worth of history, we typically query for only three days, to get a much better picture of the recent past.
It might seem excessive to do this for every microshard access. In reality, that isn’t an issue — especially if these are batched. For example, for News Feed, a microshard boils down to one per user. Typical QPS for feed services on Zippy DB are millions per second. That quantity of updates, especially when batched, drops drastically and poses no issues. Moreover, this data set doesn’t need to be populated for every single Akkio-enabled service. It can actually be shared. In other words, we need to populate user locality data only in the context of an individual News Feed, and the rest can take advantage of the same data set.
Time-windowed counters
We use the time-windowed counters provided natively by ZippyDB to store this data. For each client application service, Akkio stores a single counter per microshard per data center. The counters are currently configured to be stored for 10 days, but data can be looked up for any arbitrary time period within that 10-day window.
Note that this isn’t the only way to consume data surrounding access patterns. The other way to do this is to consume it using an offline pipeline such as Scribe. That method offers less real-time responsiveness, however.
Akkio is built to support a variety of backends. It works for both strongly consistent backends and eventually consistent backends. If you have an eventually consistent service, data migration is simple because you don’t have to worry about stale reads being served while the data is being migrated. However, with a service that needs strong consistency, the challenges increase. At the higher level, we use different strategies for different backends to ensure that we aren’t serving stale reads during data migration.
Data placement service
The data placement service figures out where to place data and when current data placements need to be changed for optimization. The DPS receives hints on suboptimally placed microshards from the Akkio client. The Akkio client knows this because it knows the placement for a given microshard — thanks to the lookup it performed on the metadata tier; and it also knows the set of regions associated with a placement.
Considering all this information and the region from which the call is originating, the Akkio client will know if the call is going cross-region or not. If it is going cross-region, then it is basically suboptimal. In that case, it fires an asynchronous notification to the DPS, asking it to reevaulate the given microshard. When the DPS receives a hint about the suboptimality of a microshard, it runs a service-specific set of policies to figure out the eligibility of a potential migration. The DPS investigates whether the number of allowed or pending migrations for the current time window has been exceeded, or some other eligibility threshold has been crossed.
Once eligibility is confirmed, the DPS then retrieves the microshard access pattern from the Akkio Access DB to figure out how often the microshard has been accessed in the recent past (basically, the past three days) from the different regions. This factors into a score that is assigned to each region; but other important factors also come into play. The score is also based on how much capacity is available in that region.
Considering capacity
By factoring in available capacity, we ensure that migrations don’t overwhelm the backend. This evaluates all types of capacity: disk space, current network usage, current disk IOPS usage, and more. Using the per-region score, the DPS generates a per-placement score, which is just a summation of the score for the associated regions. Then the system picks the best option. If the microshard is already placed in this option, nothing changes. If it isn’t, then the system initiates a migration of the data to the new placement.
New microshard creation goes through the DPS as well. We don’t do this from the Akkio client, to avoid race conditions (i.e., we don’t want the client to start accessing a microshard that has not been created). For new microshards, the DPS doesn’t have any microshard access history; the DPS knows only the current region from which the microshard is being accessed. It uses this along with the backend capacity in all regions to find an optimal placement.
Intelligent mapping
The DPS talks to this custom logic using placement handles. This custom logic knows how to map the placement handle to the backend’s data model. For example, in the case of ZippyDB, it knows how to take the shard prefix and microshard and determine the exact physical shard within that shard prefix — which basically is done using a deterministic hash function.
To ensure that there aren’t concurrent migrations for the same microshard, migrations are serialized through a lock on the metadata tier. If lock acquisition fails, then the DPS knows that another DPS instance is operating on the microshard. It aborts any work for the microshard until the next time it is notified by a client of potentially suboptimal placement for that microshard.
For additional deep-dive information into Akkio, read the white paper.
The future of Akkio
To the best of our knowledge, Akkio is the first dynamic locality management service for geo-distributed data store systems that migrates data at microshard granularity, offers strong consistency, and operates at Facebook scale. With Akkio, we also introduce and advocate for a finer-grained notion of data sets called microshards. Akkio’s design is simple yet effective and novel in several aspects. Key to Akkio’s implantation has been its use of Facebook’s unique global consistency key-value storage system ZippyDB and Facebook’s highly efficient backbone network. You can read more of the details of Akkio in the paper we are presenting at OSDI 2018.
Going forward, more applications are being moved to run on Akkio. Further developments include an extra per-server caching layer and better integration with the network. Finally, work has started using Akkio to migrate data across different storage types and to migrate data more gracefully onto newly created shards when resharding is required to accommodate (many) new nodes.








