
Every day, more than a billion people use Facebook on Android and iOS devices to connect with their friends. Securing data in transit between our mobile apps and our servers helps ensure that people have a safe experience on Facebook.
Our mobile apps use a custom networking stack called Mobile Proxygen, a C++14 cross-platform HTTP client we built using our open source Proxygen library. This has allowed us to share the same code between our servers and our clients and deliver new security and performance features quickly.
We use the Transport Layer Security (TLS) 1.2 protocol in our mobile apps and use Folly with OpenSSL as the backing implementation of TLS. TLS 1.2 adds time to the establishment of a connection including at least one round-trip, and over the past few years several new protocols and modifications have emerged to help reduce the latency of TLS. The transport security team at Facebook has worked to make TLS as fast as possible by using techniques such as terminating TLS connections at edge locations near users, reusing HTTP2 connections, using session resumption and TLS false start, starting connections speculatively, and using modern cipher suites. Most TLS connections from our mobile apps to Facebook add only one additional round-trip (1-RTT).
When looking at data about a year ago, we found that the time taken by the 1-RTT optimized security handshake during connection establishment was quite high. For example, in emerging markets like India, people would spend 600ms (75th percentile) trying to establish a TLS connection. We knew we needed to do something to reduce the latency of these requests and reduce the time to establish a secure connection.
We decided to experiment with zero round-trip (0-RTT) security protocols. Unlike 1-RTT security protocols such as TLS 1.2, these protocols aim to establish a secure connection with no additional round-trip latency for security. TCP is integrated deeply into our infrastructure, and we wanted to experiment incrementally to avoid having to overhaul our entire infrastructure at once. TLS 1.3, which is over TCP, currently has features for 0-RTT. However, at the time we were exploring options, TLS 1.3 was in a nascent phase and didn't have 0-RTT yet. Alternatively, QUIC is a 0-RTT protocol over UDP, and its crypto had received reasonable academic attention analyzing its security model. We wanted to bring the low latency of QUIC over UDP to TCP for fast, secure connections, so we built an experimental Zero protocol over TCP based on QUIC's crypto protocol.
Over the past year, we've built and deployed Zero protocol to our mobile apps and load balancers. We've seen performance improvements that include a 41 percent reduction in connection latency and 2 percent reduction in total request time. We've learned several practical engineering lessons about the trade-offs associated with 0-RTT protocols, such as API design, security properties, and deployment, and have contributed some of our findings to TLS 1.3, which is now near maturity. We hope the lessons we share here are applicable to apps that will deploy TLS 1.3 in the future.
Protocol changes made to QUIC
We made several changes to QUIC crypto in Zero protocol to make it more efficient and secure. We also made changes so that we could run it over TCP. As a result, we'll describe Zero protocol as a series of changes over the original QUIC crypto specification. This section has several details about cryptography, and knowledge of crypto would be useful to understand.
At a high level, the QUIC crypto protocol works as follows: If a client has never spoken to a server before, it sends an Inchoate Client Hello and downloads a short-lived message called a Server Config (SCFG) over 1-RTT. This contains a Diffie-Hellman share that can used by the client the next time to derive an initial key (or 0-RTT key), which it can use to encrypt data immediately. After 1-RTT the server sends a new ephemeral Diffie-Hellman share to derive a new set of keys called the forward secure keys.
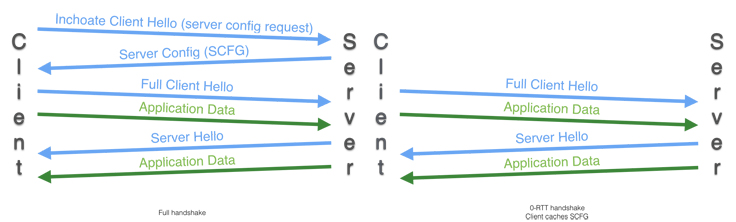
Changing QUIC key derivation
The original QUIC specification had two types of keys:
- Initial keys (or 0-RTT keys), which are used to send the initial data. These are derived from a long-lived server config.
- Forward secure (or 1-RTT) keys, which are used to send data after the server has sent the Server Hello to the client.
After a client sends a Client Hello (CHLO), the server replies with an encrypted Server Hello (SHLO) message. This contains a new set of public keys (PUBS), which is a Diffie-Hellman share to use for deriving the forward secure keys. This message is encrypted using the initial 0-RTT keys. The server is authenticated by its ability to correctly encrypt the SHLO.
However, we discovered that this method of key derivation had a key reuse vulnerability. The initial keys and nonce to encrypt the SHLO were derived entirely from the Client Hello message. So if an attacker replays a CHLO, the server would encrypt different SHLO messages with the same key and nonce. The security properties of the AEAD crypto algorithm break down, and the security of QUIC would be compromised unless additional stateful methods were used to detect duplicate CHLO messages.
In Zero protocol, we introduced another nonce that is sent in plain text, and we encrypted the SHLO with a new key. We also reported the vulnerability to Google, and QUIC was changed to include a “diversification nonce” to solve this issue.
In-band server config rotation
We limit the length of time a server config is valid, because if it were stolen during this period, it could be used forever to impersonate a server. In QUIC, the only way for a client that has cached an older SCFG to use a new one is to use the old SCFG, get rejected, and then get a new SCFG. The disadvantage of this method is that if the client has sent 0-RTT data, it needs to be thrown away and replayed whenever the config is rotated.
We changed the protocol to allow us to send a new SCFG in-band. At any moment, the server maintains a list of three configs — the previous, current, and next config. If we detect that the client has used an old SCFG, we let the client complete the connection, and then we send the client a new SCFG in the encrypted SHLO. The client can then update its SCFG to the new one. This helps avoid the degenerate case where the client gets rejected for using an old config.
TLS 1.2 also provides a method to do this by refreshing the session ticket; however, it is not forward-secure because a new session ticket shares the same master key as the old ticket. In QUIC, a refresh is forward-secure since new keys need a Diffie-Hellman operation.
Retry safety after reject
Even after refreshing server configs in-band, we could run into a case where the client uses an old config. In this case, we cannot avoid rejecting the client and would have to fall back to 1-RTT, but the connection would still not be replay-safe. Clients could send 0-RTT data, but not send normal data immediately.
We added a performance optimization to Zero protocol that would send an additional server nonce to the client during a rejection of the client server config, so that it can use this nonce to start sending normal 1-RTT non-replay-safe data immediately.
Time-bound 0-RTT data
0-RTT data has different security properties than normal data that is sent over 1-RTT or protocols like TLS 1.2. Unlike normal 1-RTT data, 0-RTT data can be replayed ad infinitum by an attacker, and this can result in interesting attacks if an app does not protect itself. For example, an attacker could replay an HTTP POST request twice and cause it to be executed twice if something isn't done to prevent it. The attacker could also replay a GET request any number of times to your bank and look at the length of responses to see how your bank account balance changes. 0-RTT data must be handled very carefully and in a different way. After 1-RTT is completed, the client can send any data since the connection becomes safe against replay.
One mitigation we added was to reduce the time for which 0-RTT was valid. A client could send us the time it started the connection, and we could compare it with server time to determine how long ago the 0-RTT data had been created. If 0-RTT data is replayed after the validity has expired, it will be rejected by our servers, preventing attackers from being able to replay the data ad infinitum. However, as we lowered the validity interval, we observed that there were many clients that had a large clock skew, and we saw a lot of false positives.
To deal with this, when a client connects successfully, we send down a clock skew correction value. The next time the client connects, it computes its client time:
client_time = client_real_time + clock_skew_correction
We observed variance in the clock skew of clients, but because the variance of the clock skew is not that large, we were able to enforce tight 0-RTT data validity times.
Modifications for TCP
We removed explicit sequence numbers and added an explicit length field to QUIC packets in Zero protocol so that we could be compatible with TCP. QUIC did not need length fields since it is over UDP, and needed an explicit sequence number since packets can be reordered.
Deploying Zero protocol
Choosing a port
We decided to run Zero protocol on the same port 443 alongside TLS. On the server, we use MSG_PEEK on the accepted socket to peek at the first few bytes of the connection and determine whether to use TLS or Zero protocol. We had more granular methods of making clients decide whether to use Zero protocol, so we decided not to use Alt-svc.
Zero RTT API
One big decision we faced was how we would integrate 0-RTT into Mobile Proxygen. A networking stack is a complicated beast, and one of the major requirements was to make 0-RTT easily testable and maintainable in the future.
We considered two possible APIs:
- Changing our socket APIs so that
connect()takes data as well, for example,connectWithData (ip, port, data). - Having clients continue to the same
connect()andwrite()APIs on the socket. To enable 0-RTT, they call a newenableZeroRTT()API. We subsequently return calls toconnect()immediately, so that the client can start writing 0-RTT data usingwrite().
When we were looking at how to integrate 0-RTT into a client, we found that the first API was extremely difficult to integrate into a reasonably complicated networking stack like ours. The API fundamentally broke the separation between components that establish a connection and others that use it. Components like HTTP, which use a connection to send data, would need to handle a part of the connection logic, which makes them more complicated. It also precludes streaming of data, i.e., if the RTT of the network varies widely, it's hard to decide how much data we should wait to buffer before we invoke connectWithData.
As a result, we chose to build the second API. The other parts of the networking stack would just keep using the same API as they were using before. A disadvantage of this approach is that complexity moves into the implementation of Zero protocol, which would have to deal with states of 0-RTT. An advantage of this approach is that it allows us to keep streaming 0-RTT data until we get a Server Hello. The RTT has a large variance, so we empirically evaluated how much data we would send while waiting for the server to send its Server Hello, which takes 1-RTT. We found that the variance of that data was a lot as well. Without a streaming API, Mobile Proxygen would have to decide exactly how much data to wait for the app to generate before bundling a 0-RTT connectWithData(), which is complicated to do. Since the variance of the data is large, with the streaming API we don't need to decide a priori how much data we need to wait for, which makes it simpler and more efficient to deploy.
Choosing which requests are safe for 0-RTT
Having decided to build a streaming API, we needed to build a mechanism to ensure that only safe requests were sent over 0-RTT. Non-idempotent requests are not safe to be sent over 0-RTT, because an attacker can replay them, but even idempotent requests might not be safe. For example, if there is a GET transaction that returns your bank account balance, an attacker could replay a 0-RTT request several times and look at the length of the response to see the balance changing.
Only an app's code really understands whether it is safe to send its data over 0-RTT.
We added an API to Mobile Proxygen:
setRequestIdempotency(RETRY_SAFE).
This indicated to the networking stack that this data was safe not only to send over 0-RTT, but also to do other things, like retry requests. We initiated discussions about this with the HTTP working group and agreed that retry safety is a reasonable property to use. We only send retry-safe requests over 0-RTT and only when an app's code explicitly marks it safe. In contrast, browsers plan to send all data over 0-RTT.
Choosing when to send a retry-safe request
Our products could send several different types of requests at once. Once we knew which requests were retry-safe, we needed to know when it was safe to send a non-retry-safe request. A Zero protocol socket could be in a state where it is safe to send retry-safe requests but not non-retry safe requests, since it has not heard back from the server.
We wanted to keep the abstraction simple as well, and avoid buffering large amounts of data in memory.
In Mobile Proxygen, we built a request scheduler to schedule requests based on various criteria. For example, high-priority requests would be scheduled sooner than low-priority ones. We added a custom request scheduler for retry-safe requests. If a request is non-retry-safe, and the transport has not yet performed 1-RTT, the retry-safe scheduler prevents the request from dispatching its headers or its body and holds it back in a queue.
When the transport is retry-safe, the retry-safe scheduler gets a callback that it is safe to dispatch non-retry-safe requests and releases the queue of requests.
Reliability of data delivery
When doing performance analysis of TLS versus Zero protocol, we found that TLS connections had a slightly lower error rate than Zero protocol connections. From our networking stack data, we observed that a majority of request errors happened while establishing a connection. As a result of the streaming API, we return a Zero protocol connection immediately to Mobile Proxygen when we know that it is ready to send 0-RTT encrypted data. By the time the networking stack obtains a connection that is capable of sending data, Zero connections have had only one TCP round-trip, versus TLS, which have had two round-trips (including TCP).
This is relevant because at connection establishment time, networking stacks try to open multiple connections. TLS connections have a greater probability of succeeding than Zero connections because they wait for more round-trips, which are effectively additional retries of the connection.
To bring parity between TLS and Zero protocol, we added retry behavior in Mobile Proxygen to increase the rate of retry when we know a request has failed before receiving a response from the server. This helped increase the reliability of Zero connections and is relevant to TLS 1.3 clients as well.
We also built a fallback from Zero protocol to TLS 1.2 to be resilient to middleboxes, but we didn't see many instances of these in the wild, and they were isolated to only a few ASNs.
Replay cache
Having a small time window when 0-RTT data is valid significantly reduces the risks of an attacker replaying 0-RTT requests forever. However, within this time window it is still possible to replay requests many times, potentially allowing an attacker to statistically analyze the timing of responses to learn more about a request. To combat this, we have been experimenting with a replay cache, which caches the 0-RTT Client Hello sent within each time window to reject duplicates. A replay cache does not entirely prevent replay, as we expect clients to automatically resend rejected 0-RTT requests as 1-RTT data, but it does limit replay to the number of times a client is willing to retry. Using a bloom filter, our replay cache is able to handle a large number of handshakes with minimal resource requirements in exchange for a small false-positive rate. We have not fully enabled our replay cache with Zero protocol (with Zero protocol, we can finely control which requests are sent as 0-RTT data, because we control the client code choosing which requests are replay-safe), but we believe it is realistic to deploy a replay cache when we deploy TLS 1.3.
Results
Performance
Zero protocol demonstrated good performance improvements over TLS 1.2. We saw connection establishment time reduced by 41 percent at the 75th percentile, and an overall 2 percent reduction in request time. Not all requests are created equal, and Zero protocol especially helps requests that are made when the app starts up and cannot reuse a connection. This resulted in a nontrivial reduction in our app's cold start time.
Contributions to TLS 1.3
Zero protocol is an experiment and has been very successful so far in delivering the performance benefits we expected. The majority of traffic from our Android and iOS apps uses Zero protocol. We've contributed the lessons we've learned to TLS 1.3 as well as to QUIC. For example, the ticket lifetime feature in TLS 1.3 is inspired by Zero protocol. We presented our API designs during TRON 2 and argued for streaming, so that servers would not have to wait for the end of early data before sending a response. We initiated several discussions about retry safety to understand the impact of 0-RTT on browsers. In the future, we hope the community can enjoy similar performance benefits with TLS 1.3.
Future
Our transport security team is in the process of building our own TLS 1.3 implementation, which will subsume Zero protocol once it is operational. We believe that TLS 1.3 has an excellent protocol design that many people in the community have contributed to. TLS 1.3 not only brings improvements in performance but also has a much simpler and more secure design. We are very excited to implement and deploy it in the near future.
We intend to keep Zero protocol as an experiment to compare with TLS 1.3. A lot of the engineering abstractions and designs we've built for Zero protocol will be immediately reusable for TLS 1.3.
Any app that cares about both security and performance should look into TLS 1.3, as well as how the considerations of 0-RTT data in this post apply to them. Zero protocol has helped us understand the implications of 0-RTT data and contribute to the development of TLS 1.3.








