
Facebook has used flash extensively for many years for our cache and database applications, and most recently as boot drives. The number of applications and the capacity footprint have grown rapidly, which means we need to rethink our approach, as current solutions simply cannot scale effectively. We are challenged to minimize the number of hardware building blocks, but at the same time maximize the amount of flash available to applications. One solution for continuing to improve operational efficiency within our data centers is to disaggregate the hardware and software components. In keeping with that trend, we have created a flash building block – a flash sled – that we can use to better scale out the flash capacity across multiple applications and tune the compute-to-storage ratio. Today we announced that we are contributing this solution to the Open Compute Project.
Why NVMe, and why Lightning?
SSD density has been doubling every 1.5 years. Efficiently scaling out this increased storage capacity and iops/TB required us to rethink our disaggregated storage appliance. Enter Lightning.
What is Lightning?
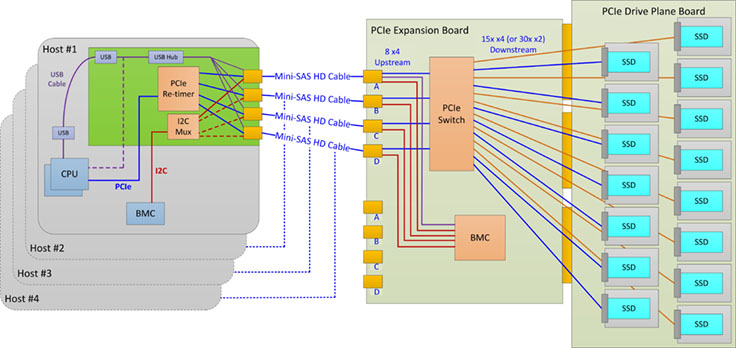
Lightning is our first version of a NVMe JBOF (just a bunch of flash). It is designed to provide a PCIe gen 3 connection from end to end (CPU to SSD). Additionally, we leveraged the existing Open Vault (Knox) SAS JBOD infrastructure to provide a faster time to market, maintain a common look and feel, enable modularity in PCIe switch solutions, and enable flexibility in SSD form factors. The block diagram below shows the topology that has been implemented.
New boards
- PCIe retimer card. This x16 PCIe gen 3 card is installed in the Leopard server, which is used as a head node for the JBOF. It is a simple, low-cost, low-power design to retransmit the PCIe signals over external mini-SAS HD (SFF-8644) cables of at least 2 meters.
- PCIe Expansion Board (PEB). The PCIe switch, the Lightning BMC, and all the switch support circuitry are located on this board. One PEB is installed per tray of SSDs and replaces the SAS Expander Board (SEB) used in Knox. This allows us to use a common switch board for both trays and also allows us to easily design new or different versions (with next generation switches, for example) without modifying the rest of the infrastructure. Each PEB features up to 32x lanes of PCIe as the uplink(s) to the retimer in the head node and 60x lanes of PCIe to the SSDs. The PEB can be hot-swapped if it fails without affecting the other tray in the system.
- PCIe Drive Plane Board (PDPB). The PDPB contains the 15x SFF-8639 (U.2) SSD connectors and support circuitry. Each SSD connector, or slot, is connected to 4x lanes of PCIe, PCIe clocks, PCIe reset, and additional side-band signals from the PCIe switch or switches on the PEB. Each SSD slot can also be bifurcated into 2x x2 ports, which allows us to double the number of SSDs per tray from 15x to 30x (from 30x per system to 60x per system) without requiring an additional layer of PCIe switching.
Features
- Lightning can support a variety of SSD form factors, including 2.5", M.2, and 3.5" SSDs.
- Lightning will support surprise hot-add and surprise hot-removal of SSDs to make field replacements as simple and transparent as SAS JBODs.
- Lightning will use an ASPEED AST2400 BMC chip running OpenBMC.
- Lightning will support multiple switch configurations, which allows us to support different SSD configurations (for example, 15x x4 SSDs vs. 30x x2 SSDs) or different head node to SSD mappings without changing HW in any way.
- Lightning will be capable of supporting up to four head nodes. By supporting multiple head nodes per tray, we can adjust the compute-to-storage ratio as needed simply by changing the switch configuration.
What are some of the Lightning design challenges?
The NVMe ecosystem is continuing to evolve and has presented some interesting challenges that need to be solved before NVMe JBOFs are viable in data centers. Here are some of the challenges that we are addressing:
- Hot-plug. We want the NVMe JBOF to behave like a SAS JBOD when drives are replaced. We don't want to follow the complicated procedure that traditional PCIe hot-plug requires. As a result, we need to be able to robustly support surprise hot-removal and surprise hot-add without causing operating system hangs or crashes.
- Management. PCIe does not yet have an in-band enclosure and chassis management scheme like the SAS ecosystem does. While this is coming, we chose to address this using a more traditional BMC approach, which can be modified in the future as the ecosystem evolves.
- Signal integrity. The decision to maintain the separation of a PEB from the PDPB as well as supporting multiple SSDs per “slot” results in some long PCIe connections through multiple connectors. Extensive simulations, layout optimizations, and the use of low-loss but still low-cost PCB materials should allow us to achieve the bit error rate requirements of PCIe without the use of redrivers/retimers or exotic PCB materials.
- External PCIe cables. We chose to keep the compute head node separate from the storage chassis, as this gives us the flexibility to scale the compute-to-storage ratio as needed. It also allows us to use more powerful CPUs, larger memory footprints, and faster network connections all of which will be needed to take full advantage of high-performance SSDs. As the existing PCIe cables are clunky and difficult to use, we chose to use mini-SAS HD cables (SFF-8644). This also aligns with upcoming external cabling standards. We designed the cables such that they include a full complement of PCIe side-band signals and a USB connection for an out-of-band management connection.
- Power. Current 2.5" NVMe SSDs may consume up to 25W of power! This creates an unnecessary system constraint, and we have chosen to limit the power consumption per slot to 14W. This aligns much better with the switch oversubscription and our performance targets.
Lightning provides a simplified and scalable solution for flash. We narrowed the focus of the design to provide flexibility where it adds value for us and removed it where it does not. We removed the added complexity of redundancy and shared PCIe endpoints. We added the ability to support multiple SSD form factors and multiple head nodes, and we focused on a power level that makes sense for our targeted IOPs/TB. Finally, we are providing the entire solution (hardware and software) to the OCP community to bolster the NVMe ecosystem and accelerate the adoption of NVMe SSDs.
Learn more
Additional details on the system are available in the preliminary specification on the Open Compute Project site.








