
Facebook has a huge IPv6 deployment, so it is no surprise that we’ve pushed the Linux IPv6 stack to the limit. One of our pain points in deploying IPv6 is the size of the routing tree. We’ve solved this scalability issue by creating routing cache on demand.
In Linux, the size of the IPv6 routing tree grows as the number of peers that a machine is talking to grows. For example, if a machine has a ‘/64’ gateway route and it is talking to a million peers, a million ‘/128’ routing caches will be created and inserted to the tree. (It’s worth noting that whenever a packet is received or sent out, it has to look up the routing tree to decide the next hop. There are exceptions, but those don’t affect our discussion here.)
A big routing tree has the following problems:
- Scalability: With a much bigger, 128-bit address space, the IPv6 routing tree should scale at least as well as IPv4.
- ‘ip -6 r show’ takes forever (and a lot of CPU). It is a pain for operation.
- The GC (Garbage Collector) kicks in too often, and each run has a lot of cleanup work to do. (The GC keeps the size of the routing tree under a configured limit.)
- When a service has just restarted, many new connection requests come in. A lot of newly created route cache entries are inserted to the tree. This puts a great deal of pressure on the tree’s writer lock.
The solution
To solve these problems, we have implemented on-demand routing cache creation and contributed it to the upstream kernel. The patch series is here.
Before going into the details, here are some numbers:
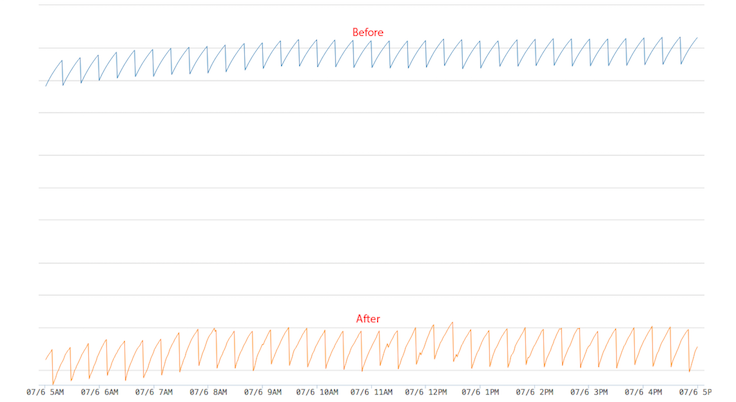
The following graph shows the number of routing entries in the tree. It is in log scale. The bottom orange line has the patched kernel. It has a lot fewer entries. The result is that the GC cleans up 500 instead of 200K routing caches in each run, and it is a multimagnitude improvement.
The benchmark test we used during development is called udpflood; you can see it in the chart below. The test continuously sends out UDP packets, which require a routing tree lookup. A dummy device is used as the outgoing interface. After removing the routing cache and adding a per-CPU entry optimization, we don’t see performance loss, and there is ~6 percent gain in the 40-process test:

Details
Why is a ‘/128’ routing cache needed?
The routing cache per peer is there to prepare for potential PMTU (Path MTU) exception. In IPv6’s case, it is the ICMPv6 too-big message. When an ICMPv6 too-big message comes in, it has to update the PMTU value for that particular ‘/128’ routing cache.
In one of our edge machines running Proxygen, the tree has 300K IPv6 routing caches, but only 1K of them have a different MTU. Hence, almost all of them are created for nothing.
Challenges
The fix seems obvious: Create a routing cache on demand. For peers with the default PMTU, share the gateway route. There are some interesting challenges, however. To name a few:
- Sharing usually comes with inefficiencies. In this case, the performance loss is caused by cache bouncing between different CPUs. (Solution: Create a per-CPU entry for the gateway route.)
- Many places in the kernel assume the next-hop route is a routing cache, which implies a ‘/128’ route. If a ‘/64’ gateway route is used instead, it will break them. Many subsystems (like TCP, UDP, IPSec, IPIP encapsulation, etc.) depend on this behavior. We have to ensure that the new change will not break them.
- Although the idea sounds similar to IPv4 (and there are some ideas we can borrow for sure), the IPv6 routing tree has enough differences that we cannot simply mimic from IPv4.
Other fixes:
- There are couple of bugs with the ‘/128’ routing entry. We have contributed fixes, removed inet_peer cache from IPv6 routing, and also cleaned up some existing workarounds. The upstream patch series is here.
- Optimize fib6_lookup(). The patch can be found here.
Going forward
With the on-demand routing cache, we solved the urgent scalability issue in IPv6. After that, we would like to further close the performance gap with IPv4 — the TCP connection test (like netperf TCP_CRR), IPv6 is still ~10 percent slower and we want to minimize some of the writer-lock usage or replace it with RCU. We think those changes would help IPv6 become the first choice among the Linux community. Some other ideas we’re considering include:
- At the high level, there is little reason to have one tree structure for IPv4 and a different one for IPv6. If the same one is used, they can benefit from the same optimization.
- We’d like to add IPv6 tests against the upstream kernel to our regression test system.
Thanks to Hannes Frederic Sowa, David Miller, Steffen Klassert, and Julian Anastasov for the roles they played in shipping these solutions.





")


