
Meta’s overall network usage and traffic volume has increased as we’ve continued to add new services. Due to the scarcity of fiber resources, we’re developing an explicit resource reservation framework to effectively plan, manage, and operate the shared consumption of network bandwidth, which will help us keep up with demand and limit network disruptions during unexpected usage spikes.
When people access one of our services, such as Ads, Storage, or News Feed, the global network provides the connectivity for their requests. People who use our products can perform their tasks because the backbone production network interconnects points of presence (PoPs), which are shared connections between two or more networks or devices, and hundreds of data centers (DCs) worldwide.
Each service is considered a separate customer for our backbone network, with its growth, agility, bandwidth, availability, and latency requirements. However, the services may have different priority levels for each of these properties. Because it is difficult to accurately attribute disruptions to network misuse or poor network management, we often face accountability challenges between our network and our services.
In the past, we focused on completely protecting our backbone network, which led to supply and efficiency challenges that are hard to overcome. However, we are making a shift to scaling our infrastructure using the guiding philosophy that a network is a finite resource.
As we’ve searched for solutions to manage network traffic more effectively, we’ve determined that Network Entitlement, a resource reservation framework, will allow us to reserve bandwidth per service for a predefined period for each region.
We presented our work, “Network Entitlement: Contract-based network sharing with agility and SLO guarantees,” at Sigcomm 2022.
Challenges around network resources
To build an effective resource reservation system, we must overcome the following challenges:
- Use of capacity: Services running on Meta’s infrastructure are agile and have distinct traffic patterns. For example, one might send sudden chunks of traffic during certain intervals and then no traffic for the rest of the day. However, another may have constant traffic. As the number of services with different demands and priorities increases, it becomes more challenging to use network resources efficiently.
- Lack of isolation from misbehaving services: While quality of service (QoS) allows us to prioritize critical traffic, services in different classes are not necessarily isolated from one another’s problems. A sudden traffic surge from one service impacts those in the same class and those in the lower QoS classes.
- Lack of accountability: The lack of service isolation leads to operational churn. Attributing a disruption to either network misuse (bursty traffic from services) or poor network management requires extensive, time-consuming analysis. The lack of accountability has become an even greater challenge as we’ve added more services.
- Long-term service-level objective (SLO) guarantees: Meta’s services require SLO guarantees for longer periods of time. However, wide-area network (WAN) capacity is sourced opportunistically, so the capacity across multiple regions is not uniform. The lack of built-in redundancy in WAN architecture, combined with a lack of accountability and service isolation, makes it challenging to provide long-term SLO guarantees for service owners.
- High contextual tax on services: Services can usually forecast, calculate, and reserve their storage and compute requirements as consumable entities. However, forecasting does not work when they share network resources. In the past, we used services to provide traffic estimates per data center pair, such as “traffic is estimated to grow at O(N^2) for N data centers.” Determining estimates in this way requires understanding network complexity, constraints, and deployment schedules. As the data centers continue to scale and the operating requirements change, this process becomes difficult to manage.
Network Entitlement
With the Network Entitlement framework, a service guarantees a bandwidth quota per region per class of service (CoS) with an agreed SLO guarantee, which serves as a contract.
From a service owner’s perspective, the network guarantees SLO for the portion of traffic within the agreed bandwidth quota. However, the network does not forcefully limit the bandwidth that a service can consume. Instead, bandwidth demand that exceeds the entitlement is allowed to flow through the network if capacity is available, but it does not receive an SLO guarantee. The portion of traffic that conforms to the entitlement is called conforming traffic, while traffic that exceeds the reservation is called nonconforming traffic.

When services exceed their allotment at end hosts, causing traffic congestion, we move or down-mark the nonconforming traffic to a lower class, which reduces the impact of the nonconforming traffic on other services. However, if network capacity is available, nonconforming traffic is allowed. The decision to drop traffic occurs at network devices only when there is congestion.
The Network Entitlement framework has five key properties:
- Isolation for reliability: The Network Entitlement framework allows us to re-mark the nonconforming traffic of misbehaving services to a lower priority. Those that conform to their entitlement contracts within the same CoS are then protected.
- Guarantee and accountability: The framework sets equal expectations for services and network teams. For all the conforming traffic, the network guarantees an SLO for availability. If a service generates traffic within entitlement and the network is unable to support it, the network team is accountable. However, if the service breaches the contract and generates more traffic than the approved entitlement, the service is accountable for the misuse of the network. This eases troubleshooting and the attribution of disruptions.
- Abstraction: The framework abstracts network complexity. Service owners can then measure, forecast, and reserve their short-term and long-term network requirements as they can with other consumable components. By creating hoselike networks, with aggregate traffic originating or terminating at a data center, we eliminate planning for a traffic matrix. Additionally, we reduce the overall context that services need to devise their growth strategy. Learn more details about hose-based traffic estimation and planning here.
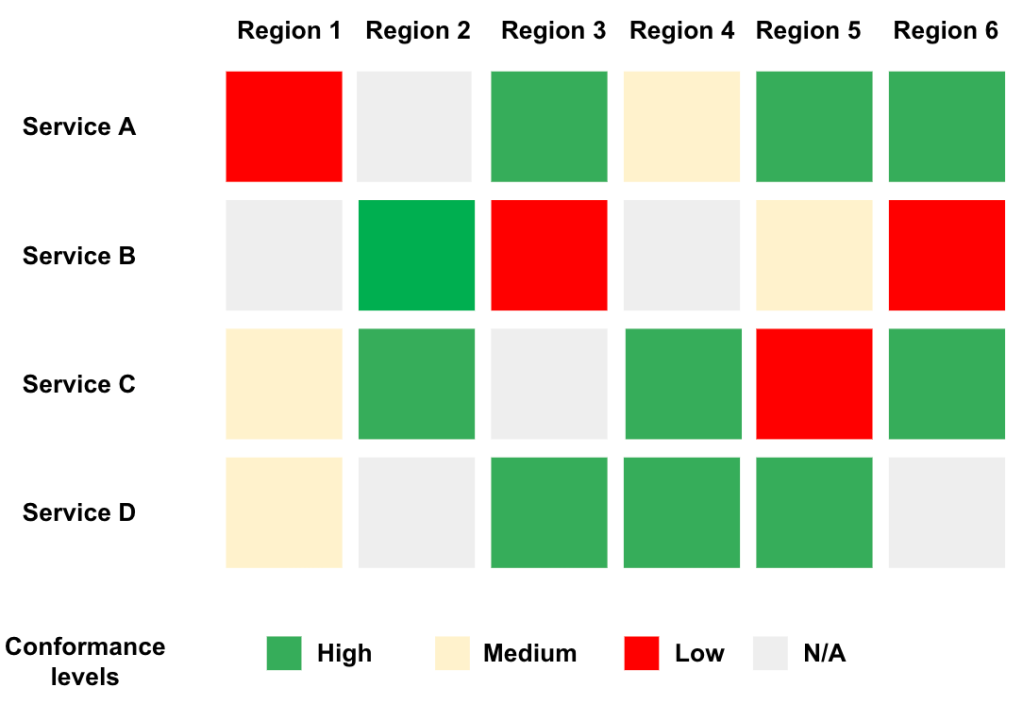
- Observability: For each finalized contract between network and services teams, we provide details about how the service consumes the network. The visualization allows both teams to flag anomalies. In addition to using metrics collected from the network, we use metrics reported by the services to evaluate the overall performance compared with the guaranteed SLO. Figure 2 shows a summary view of conformance levels for different services per region.
- Work-conserving: If capacity is available, the network delivers traffic generated by the service beyond its reservation. Enforcement of entitlement happens only during times of congestion. The network does not proactively drop or throttle traffic that is nonconforming.
Our Network Entitlement solution
The Network Entitlement framework consists of four distinct components:
Contract abstraction: This is the fundamental stage of the framework, and it requires services to forecast their future network bandwidth requirements. The contract lays out clear expectations for both services and the network in terms of bandwidth, SLO guarantee, duration, and accountability. The contract is represented using the hose model, the foundation of our long-term network planning.
Dynamic SLO-based guarantee service: To provide long-term SLO guarantees, our granting system analyzes possible network failures and changes (such as fiber cuts) in advance. By synthesizing demand, potential network failures, and available capacity, the system dynamically sets the bandwidth approval, based on the SLO target for each service, to meet SLO guarantees. However, this process is too computationally intensive to apply to every service.
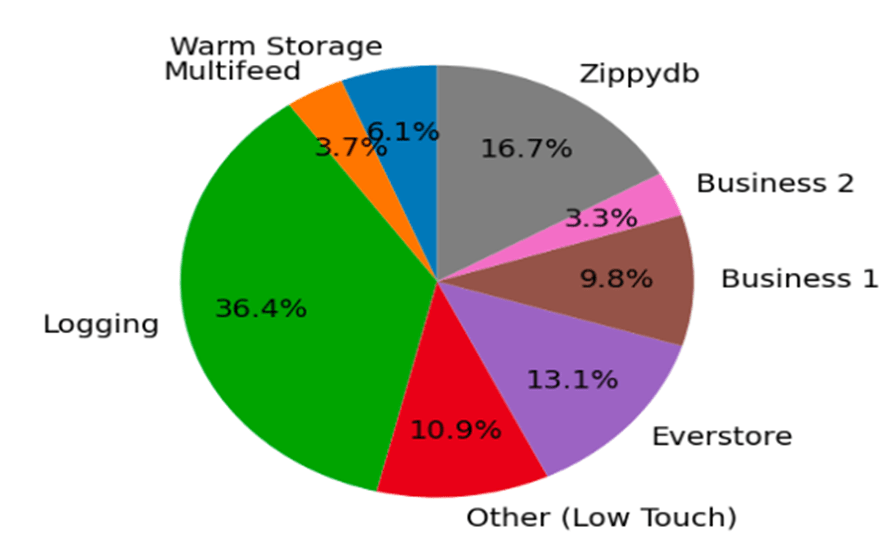
To overcome this challenge, Meta identifies high-touch services, the small set of network consumers that account for most usage (Figure 3). The granting system sets separate entitlement for high- and low-touch services, which significantly reduces operational and computational overhead. The network then grants a bandwidth quota based on the capability of the network and the SLO targets that we set for each CoS.
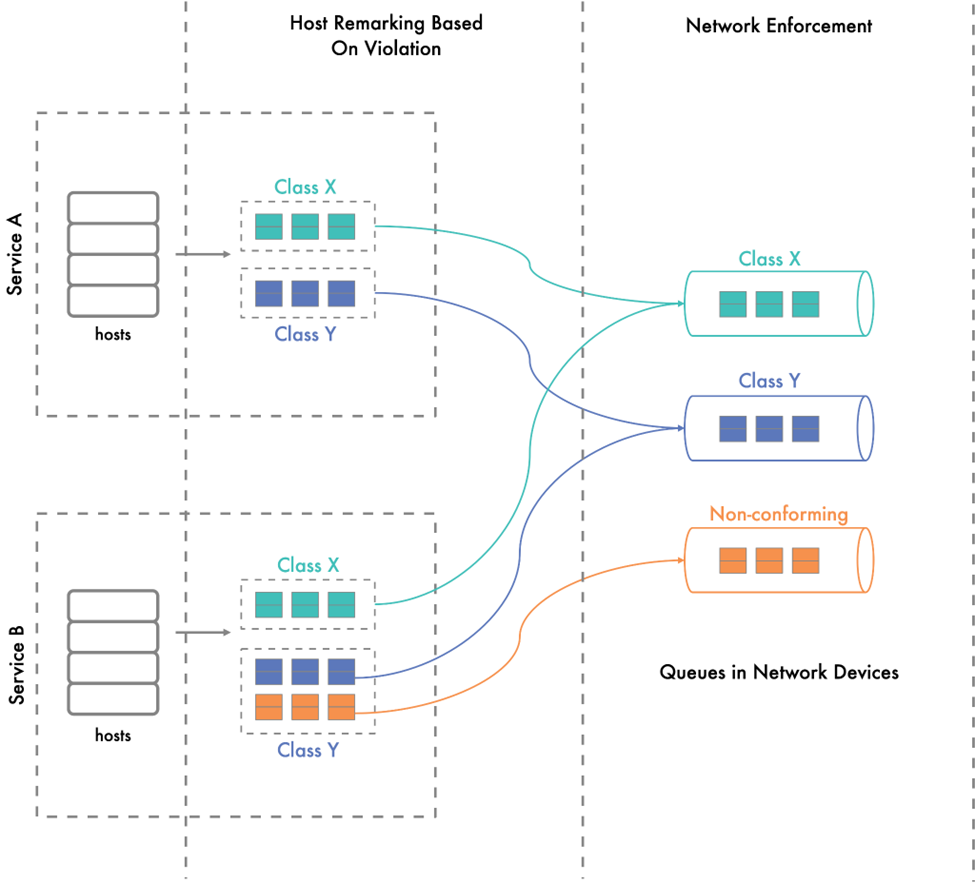
Runtime enforcement system: Meta uses a distributed runtime enforcement system in which the end hosts mark the packets in the appropriate QoS class based on the contract. During the process, the system assesses traffic in real time and re-marks nonconforming flows.
Figure 4 shows two services spread across multiple hosts. Services send traffic belonging to two QoS classes: class X and class Y. Service B sends more than the entitled traffic in class Y. The enforcement system identifies this violation and marks the excess traffic from service B in class Y as nonconforming. This nonconforming traffic has a separate, lower-priority queue set up in network devices.
Policy verification using production drills: Network teams verify the policies and effectiveness of the overall framework using extensive real-world test drills. We perform these tests every few months by introducing actual congestion with careful control of service traffic. We also use these tests to better monitor the success of service isolation and bandwidth guarantees.
Read the paper
Network Entitlement: Contract-based network sharing with agility and SLO guarantees
Acknowledgments
Many people contributed to this project, but we’d particularly like to thank Soshant Bali, Kapil Bisht, Yilun Chen, Prabhakaran Ganesan, Josh Gilliland, Varun Gupta, Rajiv Krishnamurthy, Biao Lu, Debottym Mukherjee, CS Natarajan, Gaya Nagarajan, Saci Nambakkam, Mahesh Nayak, Max Noormohammadpour, Steve Politis, Mouli Radhakrishnan, Alaleh Razmjoo, Mario Sanchez, Grace Smith,Jimmy Williams, Yuxiang Xiang, Ying Zhang, and Hao Zhong








