")
The Power of Disaggregation
Disaggregation has proven to be a useful strategy for Facebook. The idea of breaking down systems into their core components and putting them back together in ways that make more sense has resulted in flexibility and scalability gains for our infrastructure.
What do we mean by disagreggation? When engineers usually deploy various types of servers in racks — each of which has its own CPU, memory, and flash or hard disk — each server configuration uses a different ratio of these resources. The services that run on the servers utilize resources in a fixed aggregated way. Disaggregation, in contrast, creates specialized server pools, each focused on a single resource type such as compute, or memory, or HDD storage, or flash storage, etc.
Breaking the system down into building blocks and then letting the pieces specialize in their strong suits can create a multitude of advantages:
- Hardware replacement efficiencies and utilization efficiencies: We can upgrade and replace each resource type individually, potentially reducing the total amount of hardware replaced. In addition, each resource (e.g. CPU, RAM) can be better scaled so that it can be fully utilized with minimal waste.
- Custom configuration: We can tailor storage design, for example, to our needs.
- Speed of new tech adoption: Whenever a new hardware technology becomes available, we can likely adopt it quickly.
- Software product reliability and performance: The components of the software product can be re-designed and each component can run on a separate server pool, in a disaggregated manner. This allows software performance tuning and reliability can all be improved.
- CPU efficiency: Heterogeneous workloads might not be working well together in the same server. It is harder for kernel or the processor to manage workloads well in order to achieve high CPU utilization.
In one example of this, we leveraged the disaggregation concept to redesign Multifeed, a distributed backend system that is involved in News Feed. When a person goes to his or her Facebook feed, Multifeed looks up the user’s friends, finds all their recent actions, and decides what should be rendered based on a certain relevance and ranking algorithm. The disaggregation results with respect to infrastructure were impressive across multiple areas tracked:
- Efficiency: 40% efficiency improvement via total memory and CPU consumption optimization for Multifeed Aggregator and Leaf infrastructure
- Performance: 10% Multifeed aggregator latency reduction
- Scalability: each component (i.e. Aggregator and Leaf) of Multifeed can be scaled independently
- Reliability: increased resilience to traffic spikes; component failures (i.e. Aggregator and Leaf) are isolated.
Multifeed Building Blocks
To understand how we got these results, we should first break down the major high-level components of Multifeed.
- Aggregator: The query engine that accepts user queries and retrieves News Feed info from backend storage. It also does News Feed aggregation, ranking and filtering, and returns results to clients. The aggregator is CPU intensive but not memory intensive.
- Leaf: The distributed storage layer that indexes most recent News Feed actions and stores them in memory. Usually 20 leaf servers work as a group and make up one full replica containing the index data for all the users. Each leaf serves data retrieval requests coming from aggregators. Each leaf is memory intensive but not CPU intensive.
- Tailer: The input data pipelines directs user actions and feedback into a leaf storage layer in real time.
- Persistent storage: The raw logs and snapshots for reloading a leaf from scratch.
Multifeed, the Old Way: Aggregated Design
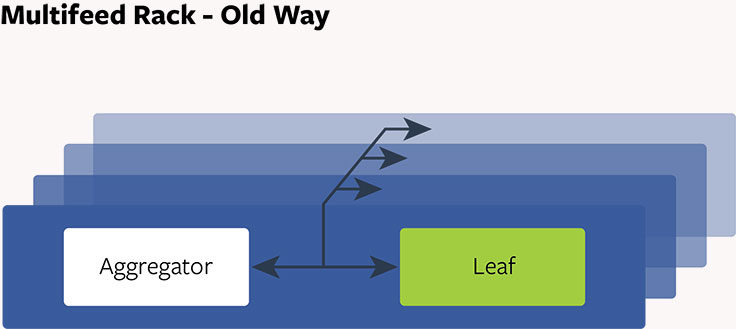
In the past, each Multifeed Aggregator was paired with one leaf, and they co-located on a shared server. Twenty such servers were grouped together, working as one replica and containing users’ News Feed data. Each replica had 20 aggregators and 20 leaves. Upon receiving a request, each aggregator fanned out the request to all the leaves to fetch data, rank and filter data, and return results to clients. We gave the Multifeed server high CPU power and large memory storage. Everything worked with this design, but it had some issues:
- Reliability: It was not uncommon for an aggregator to get a heavy request from a user with a lot of friends, leading to a sudden spike in CPU usage. If the spike is large enough, as the aggregator consumed the CPU, the leaf running on the same server could become unstable. Any aggregator (and its corresponding server) that interacted with the leaf could also become unstable, leading to a cascade of problems within the replica.
- Hardware scalability: We had many replicas in our infrastructure. The capacity was planned based on the CPU demand to serve user requests. We added hundreds of replicas to accommodate the traffic growth over time. Along the way, memory was added, coupled along with each CPU. It became clear that there was memory over-build since it was not the resource needed when more replicas were added.
- Resource waste: Each tailer forwards user actions and feedback to a leaf server. It is the real-time data pipeline for Multifeed. The leaf server spends 10 percent of CPU to execute these real-time updates. The number of replicas we have means we are using unnecessary our CPU resources just keeping our leaf storage up to date.
- Performance: Aggregator and leaf have very different CPU characteristics. Aggregator threads are competing with leaf threads for CPU cache, which leads to cache conflict and resource contention. There are also higher context switches because of many threads running.
Disaggregate Multifeed Design and Experiment
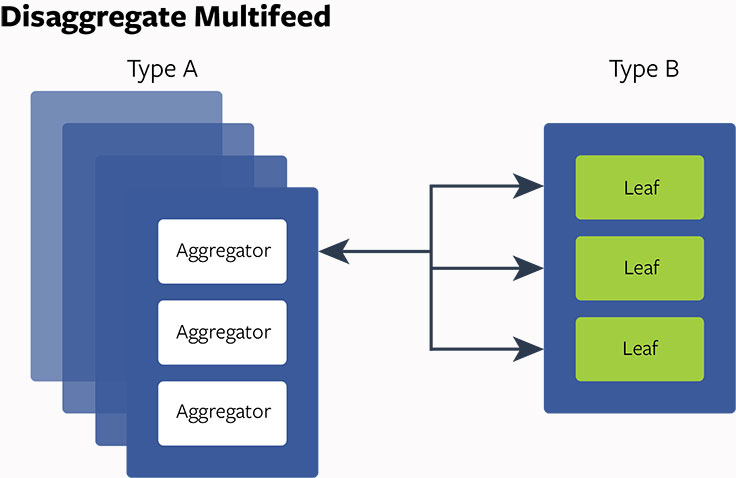
With the issues and problems identified, the question then became: How can we build the hardware and change the software product architecture to address these issues? After in-depth investigation and analysis, we decided to implement the disaggregated hardware/software design approach for Multifeed. First, we designed some servers to have intensive CPU capacity (server type A) and some to have large memory storage (server type B). Then we put aggregator on server type A and leaf on server type B, which gave us the ability to optimize the thread config, reduce context switches, enable better NUMA balancing, and also adjust the ratio between aggregators and leaves.
The disaggregated design has demonstrated improvements in our internal experiments:
- Optimal hardware/service usage: By adjusting the ratio between the aggregators and leaves, we can reduce the overall CPU-to-RAM ratio from 20:20 to 20:5 or 20:4. This is a 75 percent to 80 percent reduction in RAM consumption.
- Service capacity scalability: The aggregator and leaf capacity can be scaled up and down independent of each other. This allows software to be written with more flexibility.
- Performance: Average client latency from aggregator is 10 percent lower.
- Reliability: The disaggregated design is more resilient during a sudden write traffic spike. Any aggregator failure is an independent event, it won’t affect other aggregators and leaves.
With such encouraging results, we deployed the designs quickly. We went from conceptual design to final deployment in only a few months, and retrofitted the existing Multifeed config with the new disaggregated architecture. Next up: We are exploring disaggregated flash sled for other Facebook services such as Search, Operational Analytics and Database. We are optimistic that the benefits will be significant.








