
Most web-based services begin as a collection of front-end application servers paired with databases used to manage data storage. As they grow, the databases are augmented with caches to store frequently-read pieces of data and improve site performance. Often, the ability to quickly access data moves from being an optimization to a requirement for a site. This evolution of cache from neat optimization to necessity is a common path that has been followed by many large web scale companies, including Facebook, Twitter[1], Instagram, Reddit, and many others.
Last year, at the Data@Scale event and at the USENIX Networked Systems Design and Implementation conference , we spoke about turning caches into distributed systems using software we developed called mcrouter (pronounced “mick-router”). Mcrouter is a memcached protocol router that is used at Facebook to handle all traffic to, from, and between thousands of cache servers across dozens of clusters distributed in our data centers around the world. It is proven at massive scale — at peak, mcrouter handles close to 5 billion requests per second. Mcrouter was also proven to work as a standalone binary in an Amazon Web Services setup when Instagram used it last year before fully transitioning to Facebook’s infrastructure.
Today, we are excited to announce that we are releasing mcrouter’s code under an open-source BSD license. We believe it will help many sites scale more easily by leveraging Facebook’s knowledge about large-scale systems in an easy-to-understand and easy-to-deploy package.
Features
Since any client that wants to talk to memcached can already speak the standard ASCII memcached protocol, we use that as the common API and enter the picture silently. To a client, mcrouter looks like a memcached server. To a server, mcrouter looks like a normal memcached client. But mcrouter’s feature-rich configurability makes it more than a simple proxy.
Some features of mcrouter are listed below. In the following, a “destination” is a memcached host (or some other cache service that understands the memcached protocol) and “pool” is a set of destinations configured for some workload — e.g., a sharded pool with a specified hashing function, or a replicated pool with multiple copies of the data on separate hosts. Finally, pools can be organized into multiple clusters.
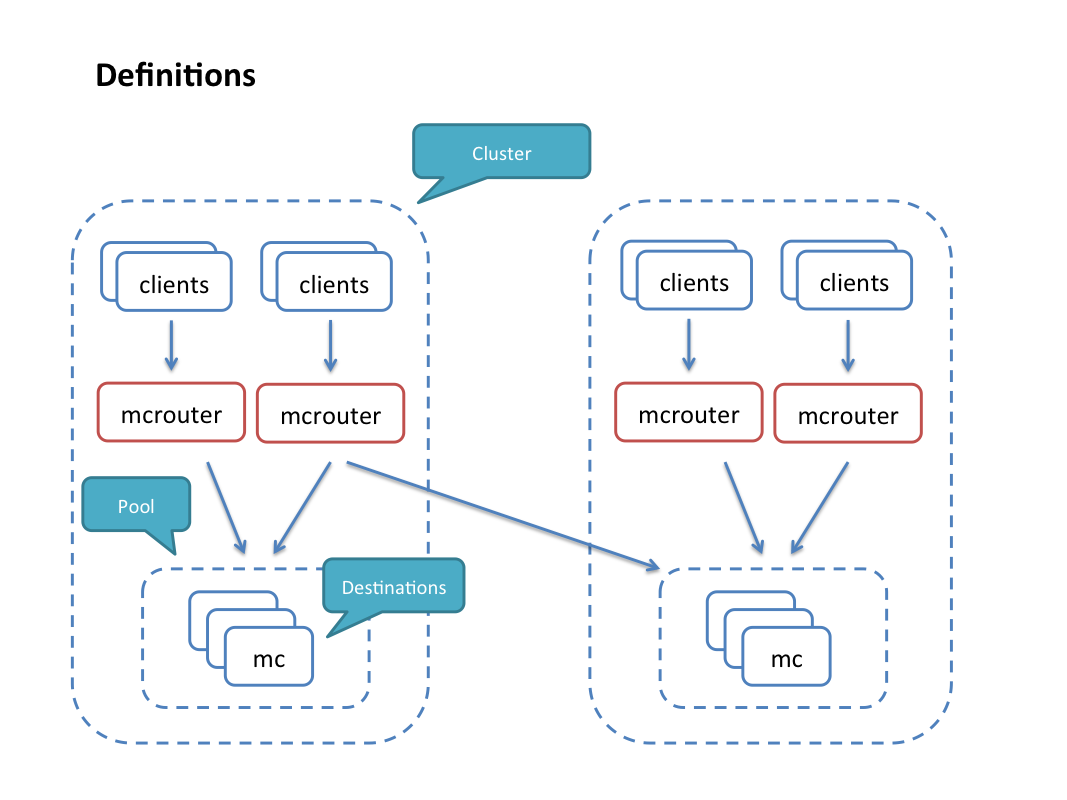
- Standard open source memcached ASCII protocol support: Any client that can talk the memcached protocol can already talk to mcrouter — no changes are needed. Mcrouter can simply be simply dropped in between clients and memcached boxes to take advantage of its functionality.
- Connection pooling: Multiple clients can connect to a single mcrouter instance and share the outgoing connections, reducing the number of open connections to memcached instances.
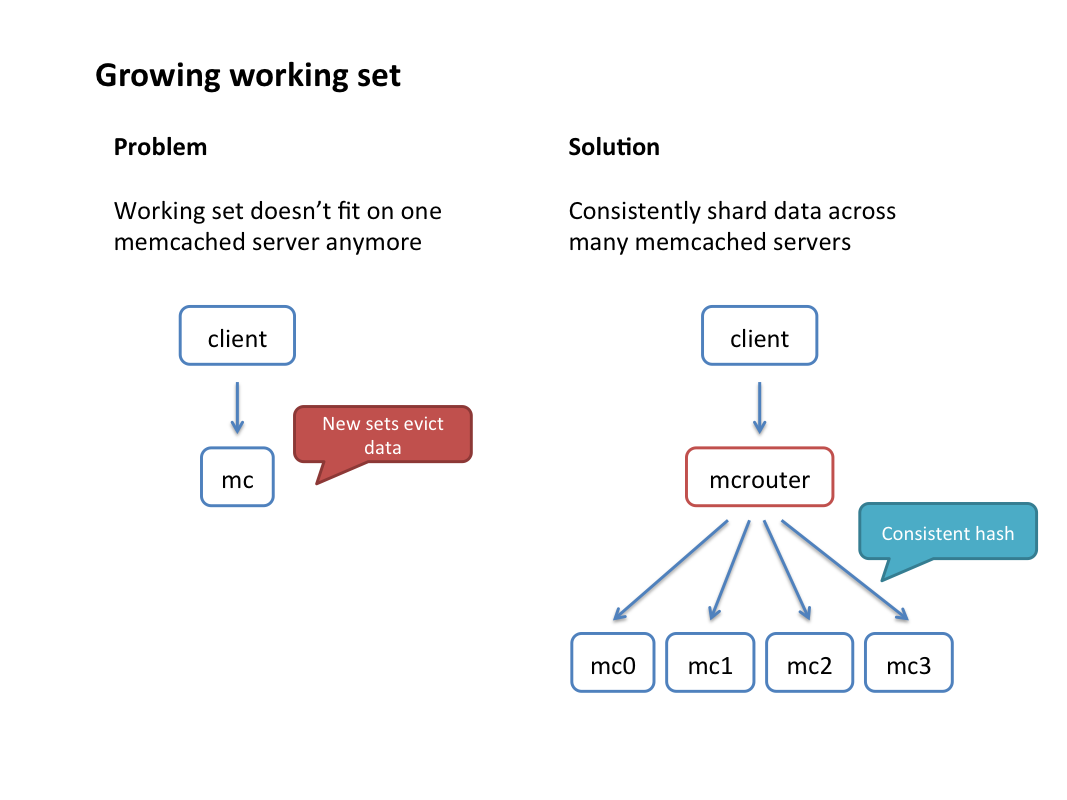
- Multiple hashing schemes: Mcrouter provides a proven consistent hashing algorithm (furc_hash) that allows distribution of keys across many memcached instances. Hostname hashing is useful for selecting a unique replica per client. There are a number of other hashes useful in specialized applications.
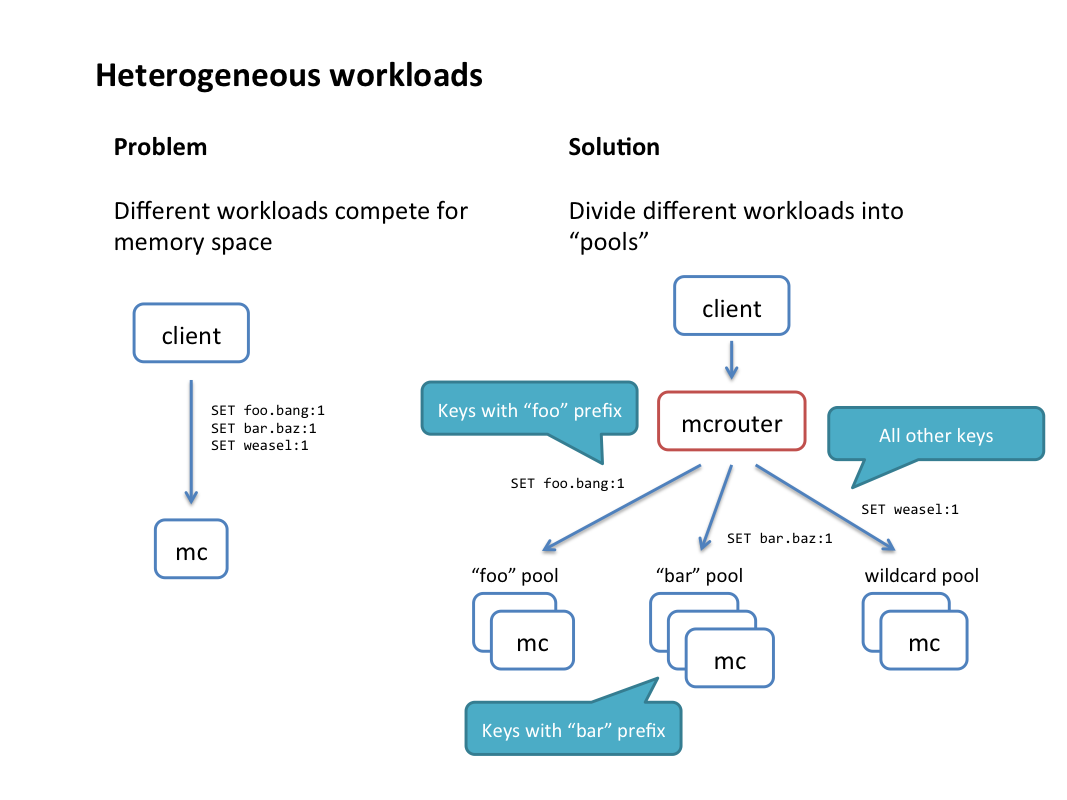
- Prefix routing: Mcrouter can route keys according to common key prefixes. For example, you can send all keys starting with “foo” to one pool, “bar” prefix to another pool, and everything else to a “wildcard” pool. This is a simple way to separate different workloads.
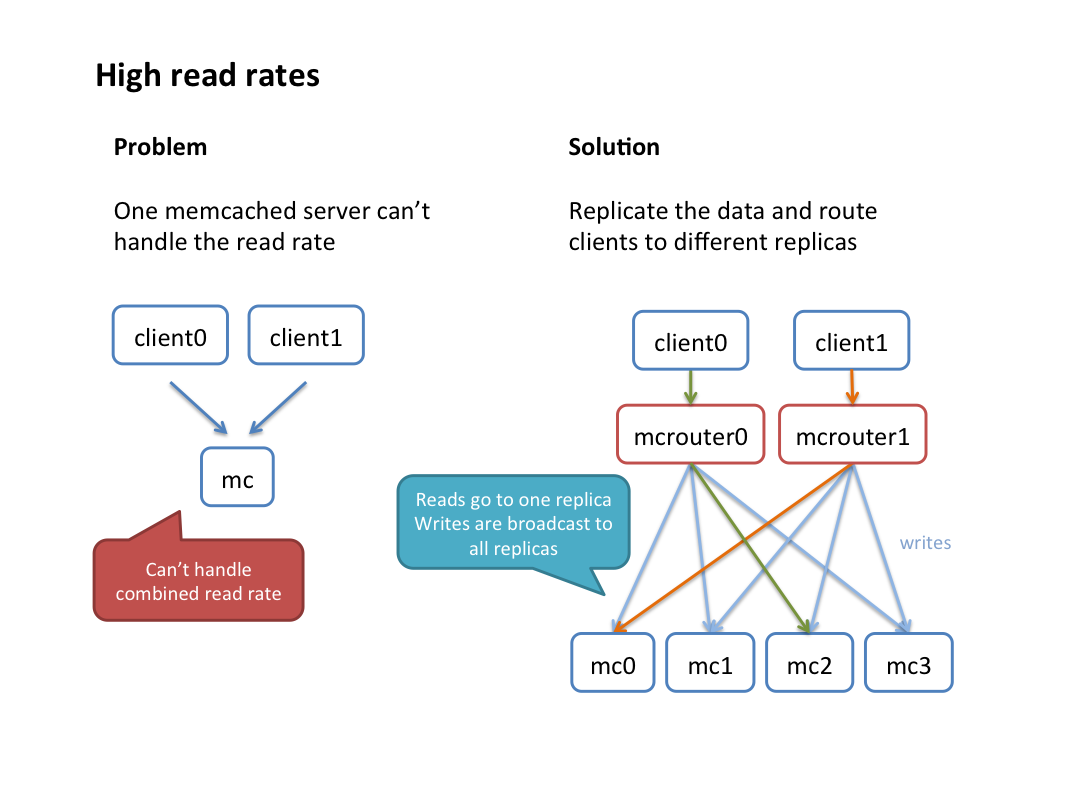
- Replicated pools: A replicated pool has the same data on multiple hosts. Writes are replicated to all hosts in the pool, while reads are routed to a single replica chosen separately for each client. This could be done either due to per-host packet limitations where a sharded pool would not be able to handle the read rate; or for increased availability of the data (one replica going down doesn’t affect availability due to automatic failover).
- Production traffic shadowing: When testing new cache hardware, we found it extremely useful to be able to route a complete copy of production traffic from clients. Mcrouter supports flexible shadowing configuration. It’s possible to shadow test a different pool size (re-hashing the key space), shadow only a fraction of the key space, or vary shadowing settings dynamically at runtime.
- Online reconfiguration: Mcrouter monitors its configuration files and automatically reloads them on any file change; this loading and parsing is done on a background thread and new requests are routed according to the new configuration as soon as it’s ready. There’s no extra latency from client’s point of view.
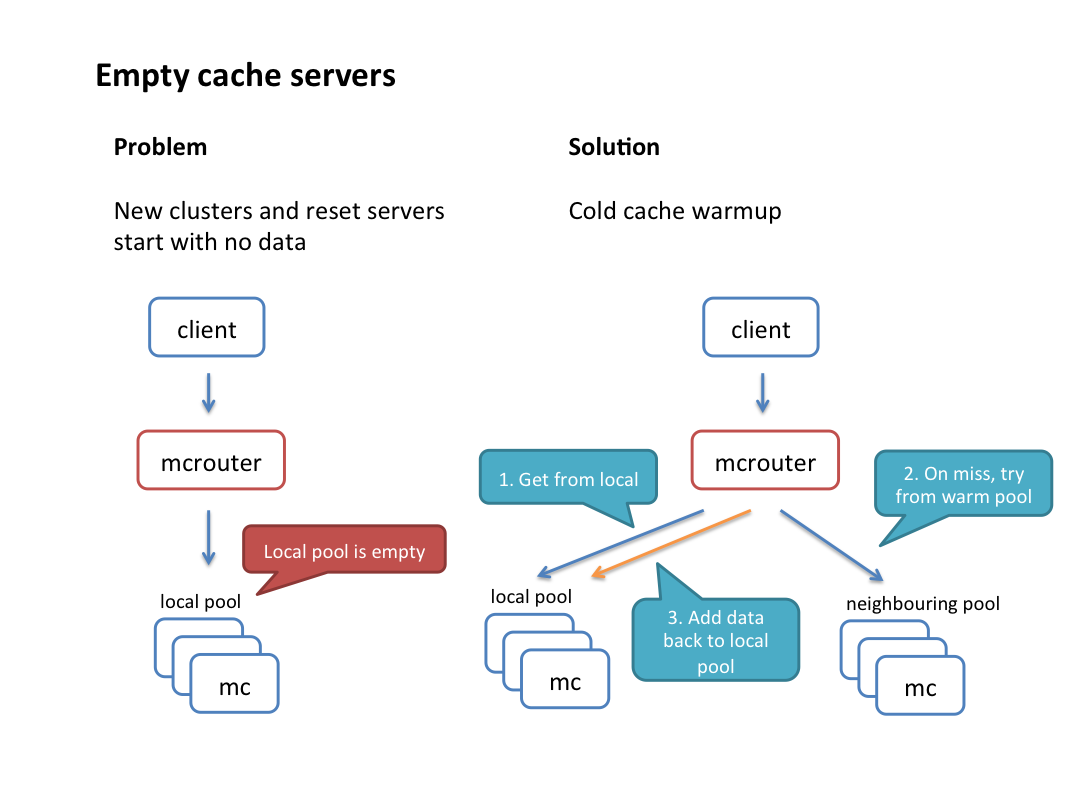
- Flexible routing: Configuration is specified as a graph of small routing modules called “route handles,” which share a common interface (route a request and return a reply) and which can be composed freely. Route handles are easy to understand, create, and test individually, allowing for arbitrarily complex logic when used together. For example: An “all-sync” route handle will be set up with multiple child route handles (which themselves could be arbitrary route handles). It will pass a request to all of its children and wait for all of the replies to come back before returning one of these replies. Other examples include, among many others, “all-async” (send to all but don’t wait for replies), “all-majority” (for consensus polling), and “failover” (send to every child in order until an non-error reply is returned). Expanding a pool can be done quickly by using a “cold cache warmup” route handle on the pool (with the old set of servers as the warm pool). Moving this handle handle up the stack will allow for an entire cluster to be warmed up from a warm cluster.
- Destination health monitoring and automatic failover: Mcrouter keeps track of the health status of each destination. If mcrouter marks a destination as unresponsive, it will fail over incoming requests to an alternate destination automatically (fast failover) without attempting to send them to the original destination. At the same time health check requests will be sent in the background, and as soon as a health check is successful, mcrouter will revert to using the original destination. We distinguish between “soft errors” (e.g., data timeouts) that are allowed to happen a few times in a row and “hard errors” (e.g., connection refused) that cause a host to be marked unresponsive immediately. Needless to say, all of this is completely transparent to the client.
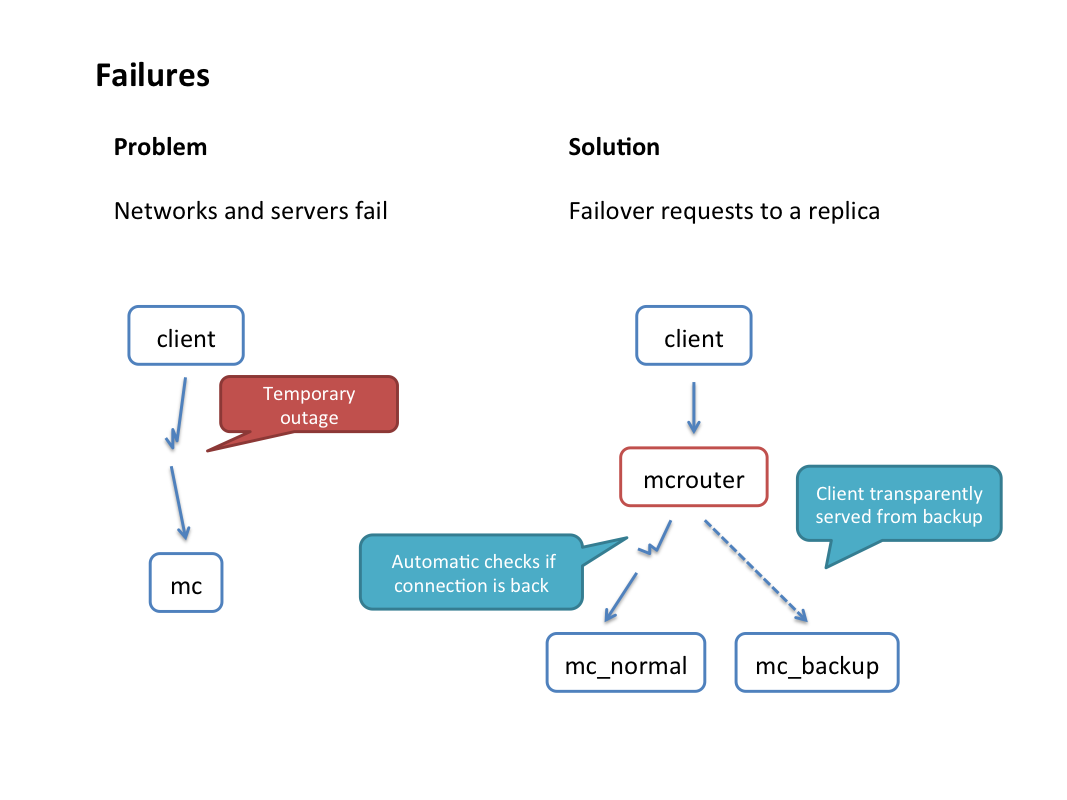
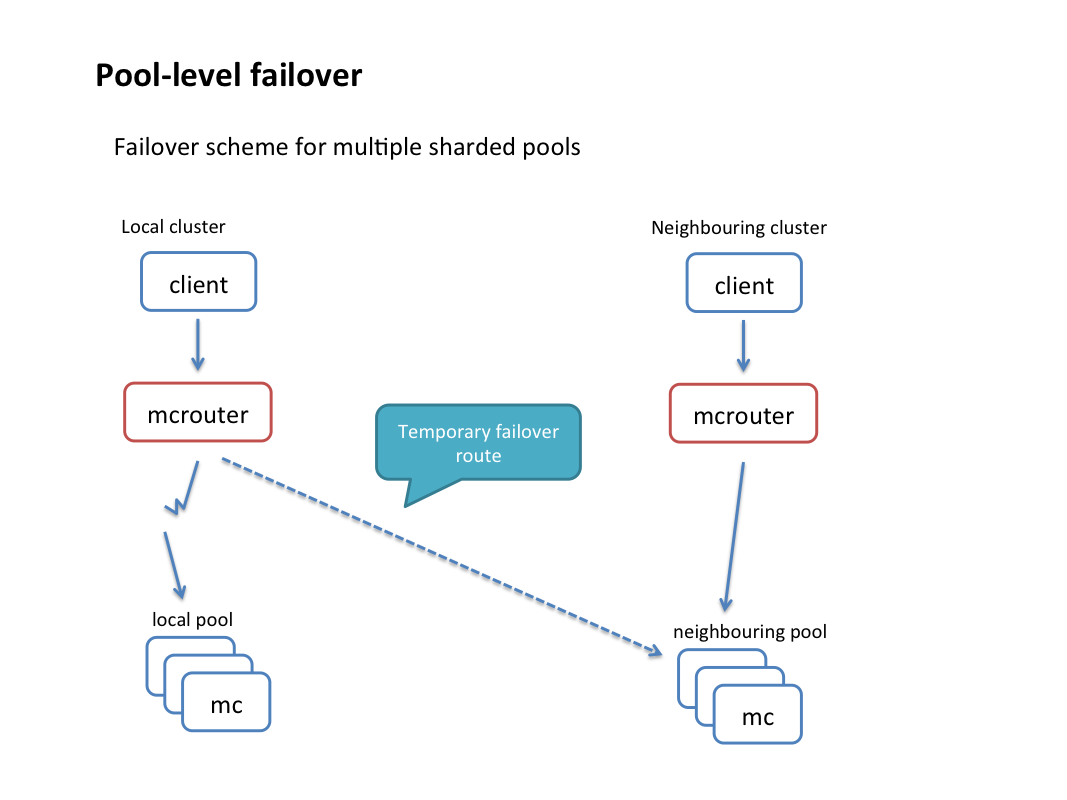
- Cold cache warm up: Mcrouter can smooth the performance impact of starting a brand new empty cache host or set of hosts (as large as an entire cluster) by automatically refilling it from a designated “warm” cache.
- Broadcast operations: By adding a special prefix to a key in a request, it’s easy to replicate the same request into multiple pools and/or clusters.
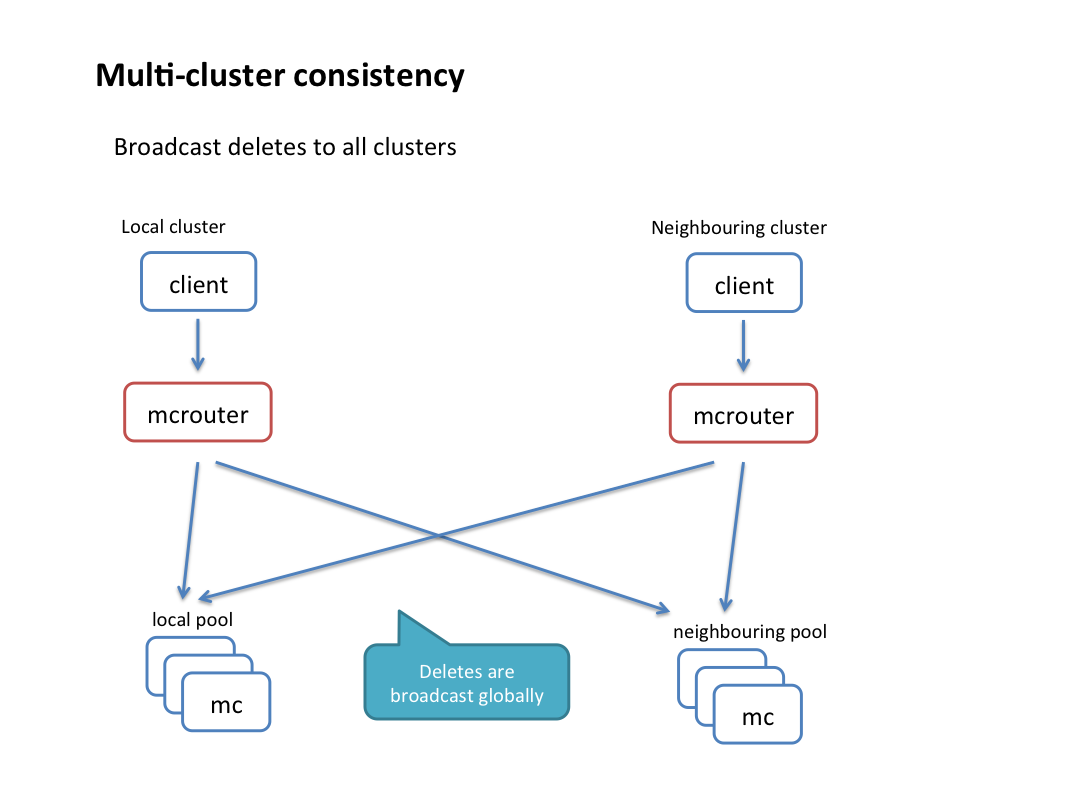
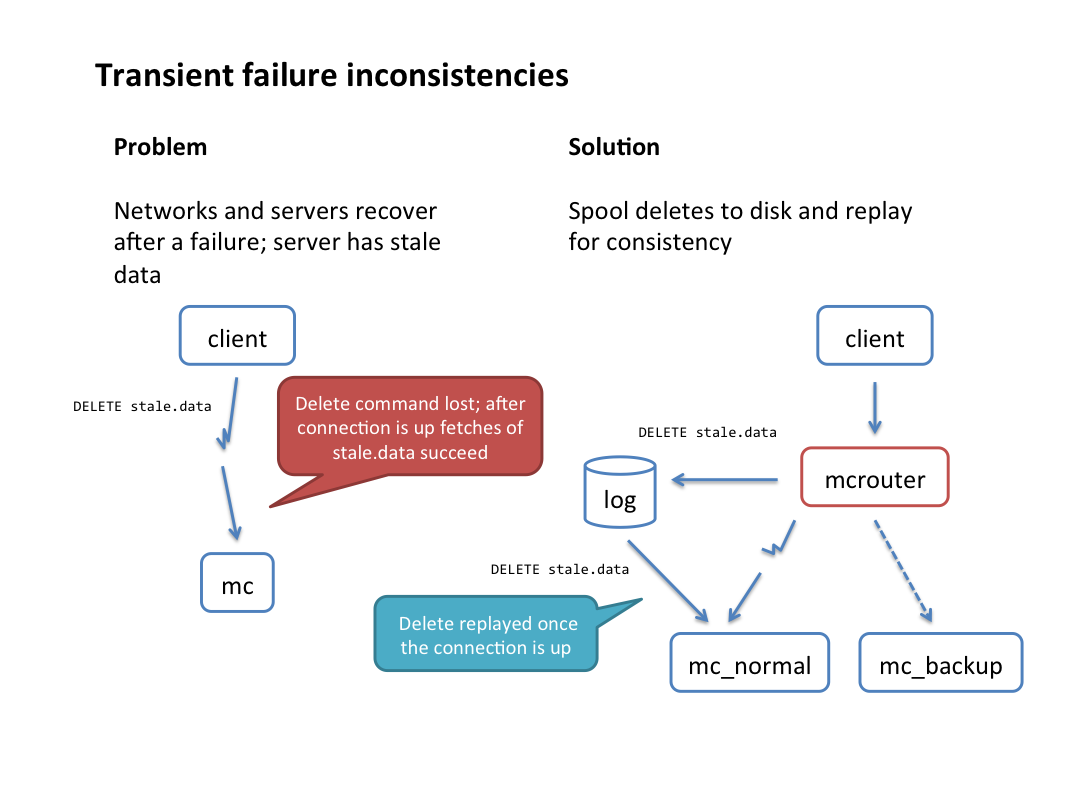
- Reliable delete stream: In a demand-filled look-aside cache, it’s important to ensure all deletes are eventually delivered to guarantee consistency. Mcrouter supports logging delete commands to disk in cases when the destination is not accessible (due to a network outage or other failure). A separate process then replays those deletes asynchronously. This is done transparently to the client — the original delete command is always reported as successful.
- Multi-cluster support: Configuration management for large multi-cluster setups is easy. A single config can be distributed to all clusters and, depending on command line options, mcrouter will interpret the config based on its location.
- Rich stats and debug commands: Mcrouter exports many internal counters (via a “stats” command; also to a JSON file on disk). Introspection debug commands are also available, which can answer questions like “Which host would a particular request go to?” at runtime.
- Quality of service: Mcrouter allows throttling the rate of any type of request (e.g., get/set/delete) at any level (per-host, per-pool, per-cluster), rejecting requests over a specified limit. We also support rate limit requests to slow delivery.
- Large values: Mcrouter can automatically split/re-stitch large values that would not normally fit in a memcached slab.
- Multi-level caches: Mcrouter supports local/remote cache setup, where values would be looked up locally first and automatically set in a local cache from remote after fetching.
- IPv6 support: We have strong support internally for IPv6 at Facebook, so mcrouter is IPv6 compatible out of the box.
- SSL support: Mcrouter supports SSL connections (incoming or outgoing), as long as the client or the destination hosts support it as well. It is also possible to set up multiple mcrouters in series, in which case the middle connection between mcrouters can be over SSL out of the box.
- Multi-threaded architecture: Mcrouter can take full advantage of multicore systems by starting one thread per core.
Implementation
Mcrouter is written mostly in C++ (with heavy use of C++11 features), with some library code written in C and protocol parsing code written in Ragel. It uses Facebook’s open source libraries Folly and fbthrift (for async networking code).
A mcrouter process starts up multiple independent threads, each running an event loop that processes all network events asynchronously (using libevent). Once each request or reply is parsed, it’s processed inside its own lightweight thread or “fiber”; we have a custom fiber library implementation built on top of boost::context.
Mcrouter configuration is written in JSON format and allows specifying an arbitrary route handle scheme to easily adapt to any routing task. We have presented some common use cases in depth on our wiki.
What’s next
We invite software engineers using memcached everywhere to evaluate mcrouter and see if it helps to simplify the site administration while providing the new capabilities listed above (shadow testing, cold cache warmup, and so on). Instagram used mcrouter for the last year, before transitioning to Facebook’s infrastructure, so mcrouter is proven in an Amazon Web Services setup. Prior to open sourcing, we partnered with Reddit for a limited beta test, and they are currently running mcrouter in production for some of their caches.
We would also love to see patches come back that will make mcrouter more helpful to you and to others in the memcached community.
Mcrouter source code has been open sourced at https://github.com/facebook/mcrouter. We’re always looking for ways to improve mcrouter’s performance, fix bugs, and add new features. We will continuously update the external Github repo with our internal changes, so you can benefit from this work as well. We maintain mcrouter documentation on the Github wiki. We have also set up a Facebook discussion group.
Footnotes:








