

Facebook Messages represents one of the most technically challenging products that we’ve ever created. As we mentioned when we launched Facebook Messages, we needed to build a dedicated application server to manage its infrastructure.
We recently discussed the Messages back end and how we scaled the service to handle all the communication coming from email, SMS, Facebook Chat, and the Inbox. Today we’ll explore the internals of the application server.
The Application Server Business Logic
The application server integrates with many Facebook services and shields this complexity from these various clients. It provides a simple interface for its clients to perform standard message operations, including creating, reading, deleting, and updating messages and the Inbox.
The flow for each of them is as follows.
When creating new messages or replying to existing ones, the application server delivers the message to the recipients on behalf of the sending user. If a recipient is specified by his or her email address, the server fetches the attachment from HayStack (if any), constructs the HTML body, and builds an RFC2822 message.
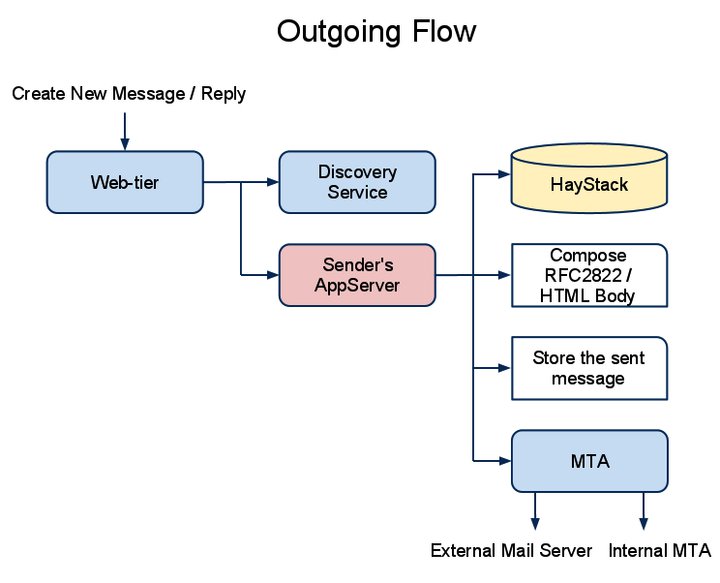
When messages are sent to a user, the server receives them from external email addresses and dispatches incoming messages to the proper recipients if the address is a reply handler. The server finally delivers the message to the user’s mailbox, running all pre- and post-processing as needed, and determining the folder and thread where the message should be routed based on a number of signals.
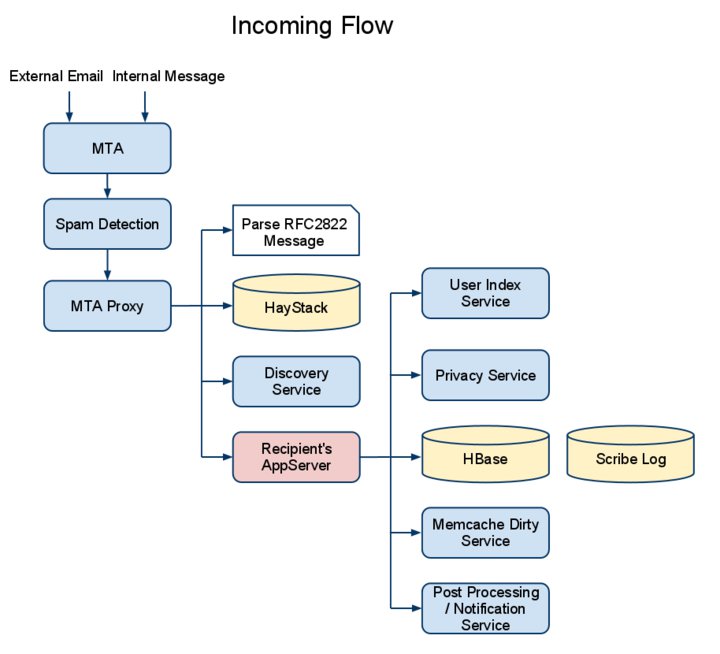
When reading messages, the server gets various statistics about the user’s mailbox, like its capacity; number of messages, threads and replies; and the number of friends with whom the user has interacted. It also gets folder statistics and attributes, the list of threads by various search criteria (folder, attributes, authors, keywords, and so forth), and thread attributes and the individual messages in the thread.
When deleting messages, the server marks messages and threads as deleted. An offline job actually removes the message contents.
When updating messages and threads, the server changes the message- or thread-level attributes, like its read and archive statuses, any tags, and so forth. It also handles subscribe and unsubscribe requests on threads with multiple users.
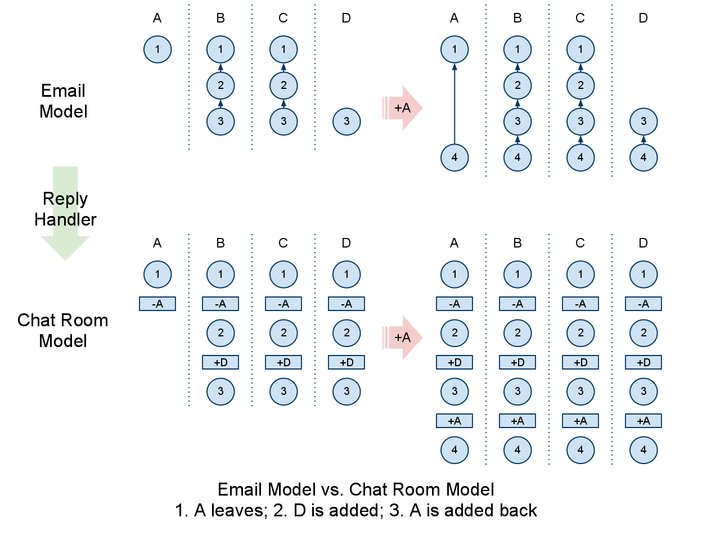
Managing Group Threads
Facebook Messages manages group message threads using a chat room model. Users can be added (subscribed) to and leave (unsubscribe from) threads. To enforce this model when email addresses are specified for recipients in a thread, the application server creates a reply handler, like a chat room ID. When an email recipient replies to a thread, the message is sent to the reply handler address.
To optimize read performance and simplify migration and backup processes, message threads are stored with a denormalized schema, so each user has his or her own copy of thread metadata and messages. The server broadcasts subscription and unsubscribe events, synchronizing the thread metadata among all recipients so it can handle the subscription and reply handler in a decentralized manner. The server also manages various corner cases when interacting with users who still have the old Inbox or were subscribed by their email addresses.
Caching User Metadata
When a user access his or her Inbox, the application server loads the most common user metadata (called active metadata) and stores it in a least recently used cache. Subsequent requests from the same user can be served promptly with fewer HBase queries.
We need to make fewer HBase queries because HBase doesn’t support join. To serve one read request, the server may need to look up multiple indexes and fetch metadata and the message body in separate HBase queries. HBase is optimized for writes rather than reads, and user behavior usually has good temporal and spatial locality, so the cache helps to solve this problem and improve performance.
We’ve also put a lot of effort into improving cache efficiency by reducing the user memory footprint and moving to finer-grained schema. We can cache 5%-10% of our users and have an active metadata cache hit rate of around 95%. We cache some extremely frequently accessed data (like unread message counts displayed on the Facebook home page) in the global memcache tier. The application server dirties the cache when new messages arrive.
Synchronization
HBase has limited support for transaction isolation. Multiple updates against the same user might occur simultaneously. To solve potential conflicts between them, we use the application server as the synchronization point for user requests. A user is served by a particular application server at any given time. This way, requests against the same user can be synchronized and executed in a completely isolated fashion on the application server.
Storage Schema
MTA Proxy strips attachments and large message bodies and stores them in Haystack before they can reach the application server. However, metadata, including search index data and small message bodies, are stored in HBase and maintained by the application server. Every user’s mailbox is independent of every other user’s; user data is not shared in HBase. A user’s data is stored in a single row in HBase, which consists of the following parts:
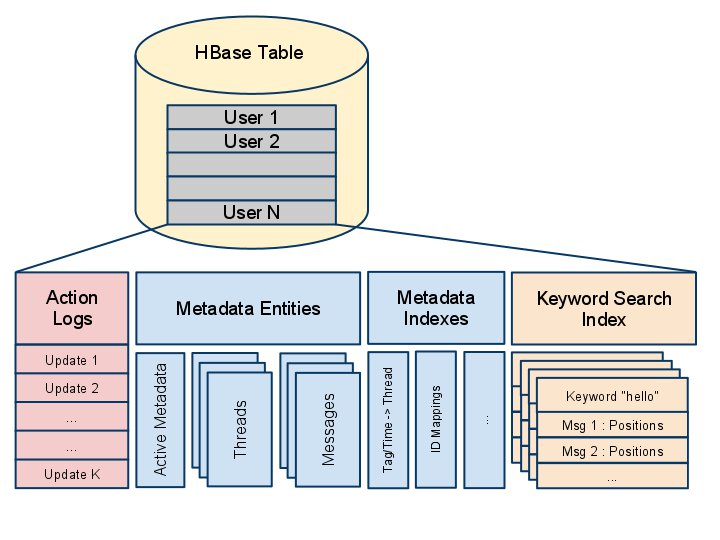
Metadata Entities and Indexes
Metadata entities contain the attributes of mailbox objects, like folders, threads, messages, and so forth. Each entity is stored in its own HBase column. Unlike a traditional RDBMS, HBase does not have native support for indexes. We maintain the secondary indexes at the application level, where they are stored as key/value pairs in separate columns as well.
For example, to answer the query “loading unread threads on the second page of the Other folder,” the application server first looks up the metadata index to get the list of threads that meet the criteria, then fetches the metadata entities of the specified threads, and constructs the response with their attributes.
As we mentioned earlier, caching and effective preloading reduces the number of HBase queries for better performance.
Action Logs
Any update to a user’s mailbox (like creating or deleting messages, marking threads as read, and so forth) is immediately appended to a column family in chronological order, called an action log. Small message bodies are also stored in action logs.
We can construct or reinstate the current state of user’s mailbox by replaying action logs. We use the ID of last action log replayed as the version of metadata entities and indexes. When a user’s mailbox is loaded, the application server compares the metadata version and latest action log ID, and updates the mailbox content if the metadata version lags behind.
Storing the action logs at the application level has brought great flexibility:
- We can seamlessly switch to a new schema by replaying the action logs and generating new metadata entities and indexes with an offline MapReduce job or online by the application server itself.
- We can perform large HBase writes asynchronously in batches to save on network bandwidth and reduce HBase compaction cost.
- It is a standard protocol to exchange persistence data with other components. For example, we do application-level backup by writing the action logs to a Scribe log. The migration pipeline converts users’ old Inbox data into action logs and generates metadata and indexes with offline MapReduce.
Search Indexing
To support full text search, we maintain a reverse index from keywords to matched messages. When a new message arrives, we use Apache Lucene to parse and convert it into (keyword, message ID, positions) tuples, then add them to an HBase column family incrementally. Each keyword has its own column. All messages, including chat history, email, and SMS, are indexed in real time.
Testing via a Dark Launch
The application server is new software we built from scratch, so we need to monitor its performance, reliability and scalability before we roll it out to more than 500 million users. We initially developed a stress test robot to generate fake requests, but we found that the results could be affected by quite a few factors, like message size, distribution of different types of requests, distribution of user activity rates, and so forth.
In order to simulate the real production load, we did a dark launch, where we mirrored live traffic from Chat and the existing Inbox into a test cluster for about 10% of our users. Dark launches help us uncover many performance issues and identify bottlenecks. We also used it as a convincing metric to evaluate various improvements we made. Over time, we’ll continue to roll out the new Messages system to all our users.
Jiakai is a software engineer on the Facebook Messages team.











