
A touring alien from a galaxy far, far away is an avid Instagram user. Her Instagram Feed is dominated by:
- Friends and family posts
- Some space travel magazines
- A few general news accounts
- Lots of science fiction blogs
She logs in, scrolls through her feed gently — catching up with friends and family, keeping pace with general news in the galaxy, and sometimes taking a moment to catch up on an interesting science fiction short story.
After having caught up, she switches to the explore tab. She loves this tab as well. It has the right mixture of surprise and delight for her. She spends quite a lot of time engaging with the content. But, every once in a while she has an aha moment. She finds an account she actually wants to follow. Today, she found that slightly niche space travel magazine she wants daily updates from. This act of following increases the amount of content in her feed, and since the content is more personalized, she finds it more valuable.
This and many other such typical user stories inspired us to ask the following questions:
- Users spend a lot of time crafting the perfect home feed for themselves. How can we do some of that work for them and make it feel like they crafted these recommendations themselves?
- Anecdotally speaking, users who stay engaged keep finding newer sources of interests to follow. Can we help in this act of progressive personalization a bit?
The Home Feed Ranking System ranks the posts from the sources you follow based on factors like engagement, relevance, and freshness. On the other extreme lies the Explore Ranking System, which opens you up to many other public posts which might be relevant and engaging to you. Could we find a middle ground and design a ranking system which shows you posts from accounts you do not follow and yet feel like you crafted them yourselves?
In August 2020, we launched Suggested Posts in Instagram to achieve this objective, which currently show up at the end of your feed. Here’s how we designed this marriage of familiarity and exploration.
Design principle
Before we dive into the details of the machine learning system it is necessary to state the design principles which shall guide us along the way like a north star. “Feels Like Home.” Meaning, scrolling through the End of Feed Recommendations should feel like scrolling down an extension of Instagram Home Feed.
System overview
Typical, information retrieval systems have a two-step design: candidate generation and candidate selection. In the first step of candidate generation, based on a given user’s explicit or implicit interests we fetch all the candidates that a user could be possibly interested in. This is a recall-heavy stage. In the second stage of candidate selection, typically a more heavy-weight ranking algorithm works on these candidates and selects the best subset that is finally shown to a user. In real systems, these two stages could be divided into many sub-systems for better design and control. Based on this understanding we are ready to dive into the design of the Suggested Posts ranking system.
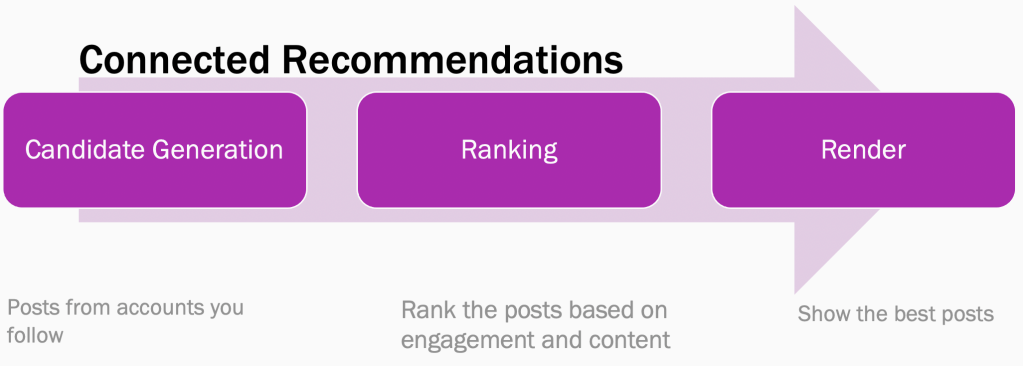
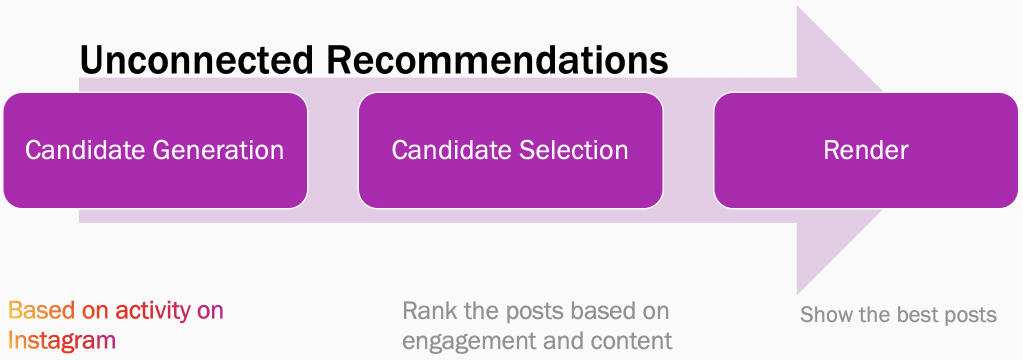
The following flowcharts display the key difference between a connected recommendation system versus an unconnected recommendation system. In a connected recommendation system, like Instagram Home Feed or some popular subscription-based news reader, the sources are explicitly defined by the end user. The ranking system picks the best posts provided by these sources and ranks them based on factors like engagement, relevance, user interests, content quality, and freshness. In an unconnected system (like Suggested Posts), sources are derived implicitly based on a user’s activity across Instagram and are then ranked based on similar factors.
Candidate generation
Let us say our touring alien follows a tech magazine which focuses on spaceship design. She regularly likes their content and comments on it. This provides us with an implicit signal that she might possibly be interested in a similar genre of tech magazines. Following this line of thought, we can enumerate all such candidates of interest algorithmically based on engagement and relevance.
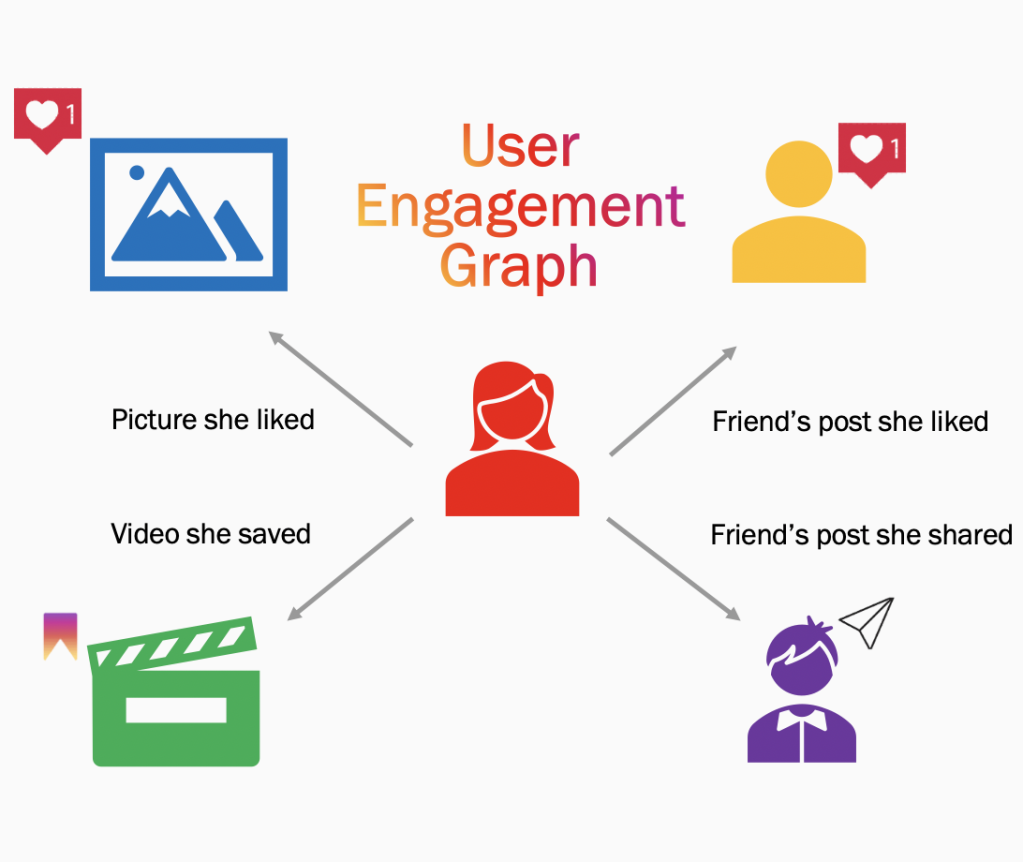
Let’s dive deeper. A user’s activities on Instagram helps us in building a virtual graph of their interests as shown below. Every node in this graph can now be a potential seed. Well, what is a seed? A seed is an author or media that one has shown explicit interest towards. Each seed can now be used as an input in our K-nearest neighbor pipelines which output similar media or similar authors. These KNN pipelines are based on two classic ML principles:
- Embeddings based similarity: We used user engagement data to build account embeddings. This helps us in finding accounts which are thematically and topically similar to one another. We learnt account embeddings similar to how word embeddings are learnt. Word embeddings are a vector representation of a word, learnt from the context the word appears in, across sentences in a corpus. Similarly, account embeddings are learnt by treating various accounts/media that a user interacts with, as a sequence of words in a sentence (example: say a certain user likes their BFF’s selfies). We can then find the most similar accounts to the seed by finding the nearest accounts in the vector space.
- Co-occurrence based similarity: This method of similarity is based on the idea of frequent pattern mining. Firstly, we generate co-occurred media lists by using user-media interaction data (example: our touring alien likes posts about science fiction and spaceships). We then calculate co-occurrence frequencies of media pairs (example: spaceship posts and science fiction posts co-occur). Finally, we aggregate, sort and get the top N of our co-occurred media as our recommendations for a given seed.
We at Instagram have developed a query language to quickly prototype sourcing queries (also referenced here). This leads to high-speed iteration while designing and testing new high quality sources. Here is a sample query:
user
.let(seed_id=user_id)
.liked(max_num_to_retrieve=30)
.account_nn(embedding_config=default)
.posted_media(max_media_per_account=10)
.filter(non_recommendable_model_threshold=0.2)
.rank(ranking_model=default)
.diversify_by(seed_id, method=round_robin)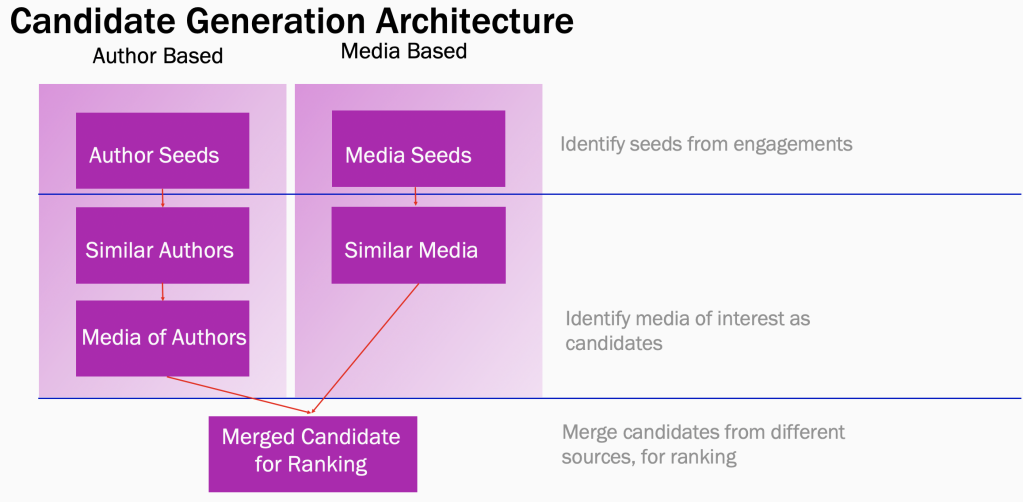
Cold start problem
Many new (and some seasoned) users may not have enough recent engagement on Instagram to generate a big enough inventory of candidates for them. This brings us to the familiar situation of dealing with a cold start problem in recommendation systems. We deal with the problem in the following two ways.
- Fallback graph exploration: For users whose immediate engagement graph is relatively sparse, we generate candidates for them by evaluating their one-hop and two-hop connections. Example: If a user A hasn’t liked a lot of other accounts, we can probably evaluate the accounts followed by the accounts A has liked and consider using them as seeds. A → Account Liked by A → Accounts followed by the accounts A likes (Seed Accounts). The diagram below visualizes this line of thinking.
- Popular media: For extremely new users, we typically get them started with popular media items and then adapt our parameters based on their initial response.

Candidate selection
We rank a given post based on many factors of engagement and aversion which act as labels in our ranking pipeline. These include positive engagement factors such as like, comment, and save; and negative factors such as not interested and see fewer posts like these. We combine the probabilities learnt for these respective labels in a user value model which is a log-linear model of the following form.
Value(Post) = (probability_like)^weight_like * (1- probability_not_interested)^weight_see_lessThe weights are tuned using a) offline replay over user sessions and b) online Bayesian optimization. We tune these factors and weights frequently as our system evolves.
As far choice of model classes are concerned, we use point-wise classification algorithms which minimize cross-entropy loss:
- MTML (Multi Task Multi Label Sparse Neural Nets): The multiple labels being acts of engagement such as like, save.
- GBDT (Gradient Boosted Decision Trees)
We also use list-wise session based algorithms such LambdaRank which minimize the NDCG loss directly.
The overall architecture and hyperparameters are tuned frequently during training, offline-replay, and online A/B tests. Additionally, depending on the task, we experiment with multi-stage ranking and distillation models as and when necessary.
We use a plethora of features to make our models increasingly intelligent and efficient. We have listed some of them below:
- Engagement features
- Author-Viewer Interaction based features
- Counters or trend based features for author and media
- Content quality based features
- Image or video understanding based features
- Knowledge based features
- Derived functional features
- Content understanding based features
- User embeddings
- Content aggregation embeddings
- Content taxonomy based features
The above list is just a snapshot and is neither complete not comprehensive. We use appropriate selection mechanisms and A/B tests to add or subtract more features as needed. We ensure the model output’s distributional robustness by frequently calibrating our models to a standard distribution.
Feels Like Home
We will now turn our attention to the implementation of our primary product principle, “Feels Like Home”. The are some of the steps we take to ensure suggested posts feel like a continuation of the Home Feed.
- Instagram has many recommendation surfaces (Home, Explore, Reels, Shopping etc.) and we could potentially find seed accounts for a user on all of our surfaces. Let’s denote the seed accounts we receive from Home as H and the ones we receive from other surfaces as R. Let us denote the seed accounts we receive from any other backup mechanism, like personalized graph exploration, as F. In order to ensure that our recommendations feel similar to posts in Home Feed we prioritize accounts that are similar to accounts a user encounters in Home. The final merge order is as follows: H >> R> F. We also use author embeddings to measure and tune the similarity of a recommended account with the that of Home accounts.
- In the candidate selection step while training and evaluating our ranking models we ensure that the overall distribution is not skewed away from Home-based sources.
- We follow the same freshness and time sensitivity heuristics as Home Feed to ensure that suggested posts provide a similar kind of fresh feeling as the rest of Home Feed.
- We also ensure that the mixture of media types (like photos/videos/albums etc.) are relatively similar in Home and suggested posts.
- Finally, we receive regular qualitative guidance from user experience researchers and user surveys. They inform and guide our strategies for ensuring a Home-like feeling in suggested posts.
Parting words
The suggested posts recommendation system was designed on a bedrock of subjective design principles rather than purely objective metrics such as ROC-AUC and NDCG. Overall, we are committed as a team to deliver a personal, relevant, useful, and curation-worthy feed which prioritizes long term quality of the product. If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, or follow us on Facebook.








