
As Facebook Live and Facebook Watch have grown, the content shared there has expanded to include professionally produced, broadcast-quality content, like shows and live event coverage. This type of professional broadcasting from providers like La Liga, CONMEBOL, and UEFA is a very different challenge from user generated content (UGC) and viewers’ expectations are much higher. Viewers who are used to the reliability and quality of traditional TV broadcasts expect a near-flawless viewing experience for these Live streams.
While many companies do one or the other well, we need to support both UGC and broadcast-quality Live streams at a very large scale. These videos have to work every time — for everyone. To accomplish this, we built a system capable of managing both UGC (captured on all kinds of devices at differing quality levels) and broadcast-quality high-res streaming — and working reliably for billions of people around the world.
To deliver a seamless streaming experience at this scale, the entire system, from ingest to delivery, needs to be reliable — but the overall system is only as reliable as its weakest component. Most UGC content uses public internet, which comes with some risk of variable network conditions: A capacity limit somewhere in the network may degrade quality, or a failure might cause a video stall or buffer for viewers. We never want viewers to experience interruptions like these on either social streaming or professional broadcasts, but for big events like the UEFA Champions League Final, the impact of losing audio or video for even a few seconds is high.
We built new ingestion capabilities to bridge the gap between traditional TV production and the internet-based ingestion designed for our UGC audience. We built in redundancy at every point — transport, ingestion, processing, delivery, and playback — to make sure the system could withstand most types of failure. And we scaled our delivery infrastructure to support streams with unprecedented viewership. Along the way, we discovered new failure modes — as well as ways to mitigate them in time for the next broadcast.
That video system is now in production, supporting millions of Live streams every day across both UGC and professional broadcast. In August, the system proved itself when we reached a huge number of concurrent viewers on the Facebook Live broadcast of the UEFA Champions League final. Viewership peaked at 7.2 million concurrents across both the Brazil and Spanish-speaking Latin America streams. Ensuring this level of seamless reliability required work on both ingestion and delivery.
Reliable ingestion
Because the stakes are high, TV broadcasters keep everything on private, dedicated paths with guaranteed bandwidth. These paths are always geographically diverse: either two independent fiber-optic paths or a fiber-optic path with a satellite backup. To reliably support similar high-viewership broadcasts, we leverage a broadcast facility with our own managed encoders so we could easily access broadcast networks, usually private fiber and satellite links, to keep the video/audio quality and reliability as high as possible. That facility is connected to our data centers using dedicated and diverse connections.
We also built mechanisms that allow ingestion of main and backup streams into our infrastructure as well as the ability to manually or automatically failover from main to backup in case of issues, all while ensuring that the viewing experience remains flawless.
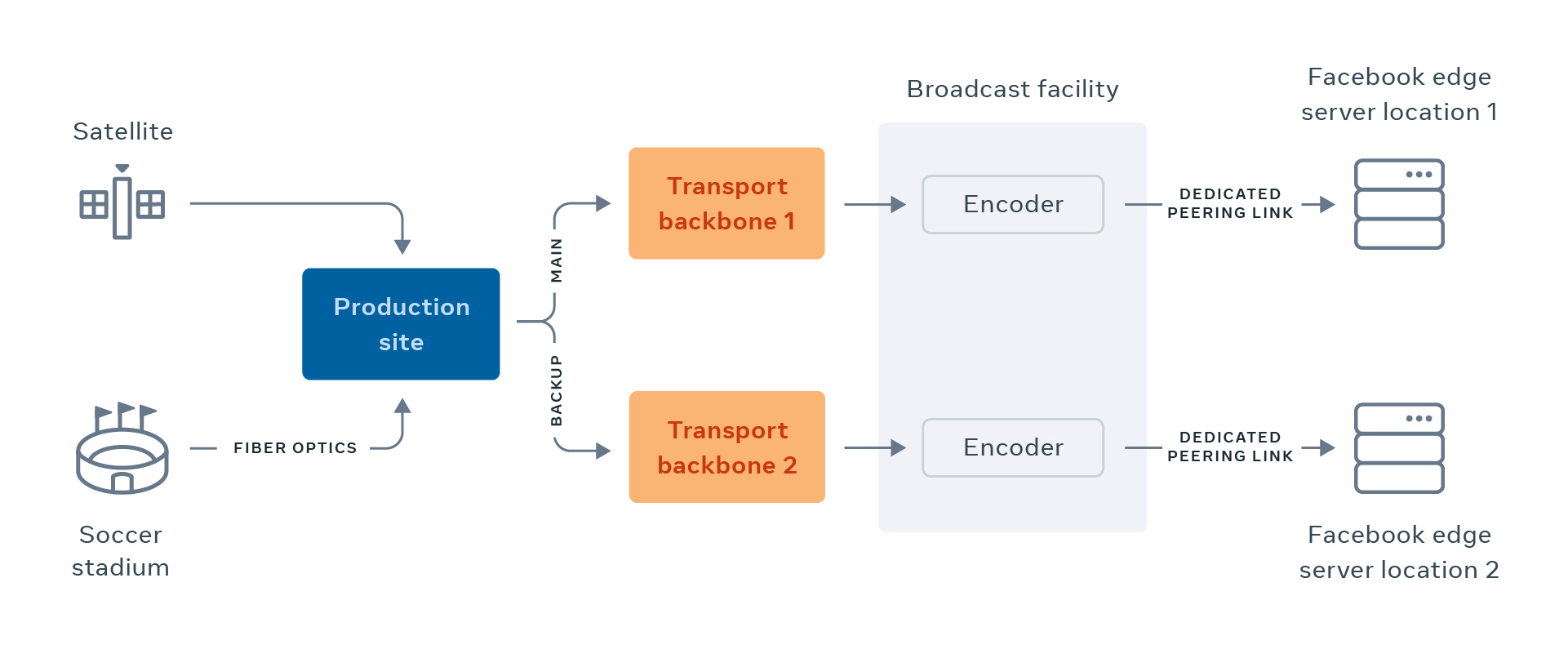
This shift from supporting broadcasts in aggregate to supporting a single broadcast means things we traditionally accepted (machine restarts, network failures, congestion, etc.) now require careful mitigations. These mitigations (coordinated failover, dedicated link capacity, multiple geo-distributed paths, etc.) need to happen over the entire duration of games, which can easily run longer than four hours with pre- and post-shows.
Massive delivery fanout
In addition to ingesting content seamlessly and at scale, we also need to manage massive scale delivery of video content to viewers. These big events and broadcasters are followed by millions of people who get notifications when the Live stream starts. This creates a spike of simultaneous viewers trying to watch the Live stream. When edge cache servers (located proximate to users) don’t have the requested content, they forward the request to underlying services. This causes what we call the thundering herd problem — too many requests can stampede the system, causing lag, dropout, and disconnection from the stream.
We have built robust infrastructure to protect our back-end services from such thundering herd issues by developing novel forms of request coalescing and cache sharding that allow us to reliably deliver video content while ensuring realtime playback.
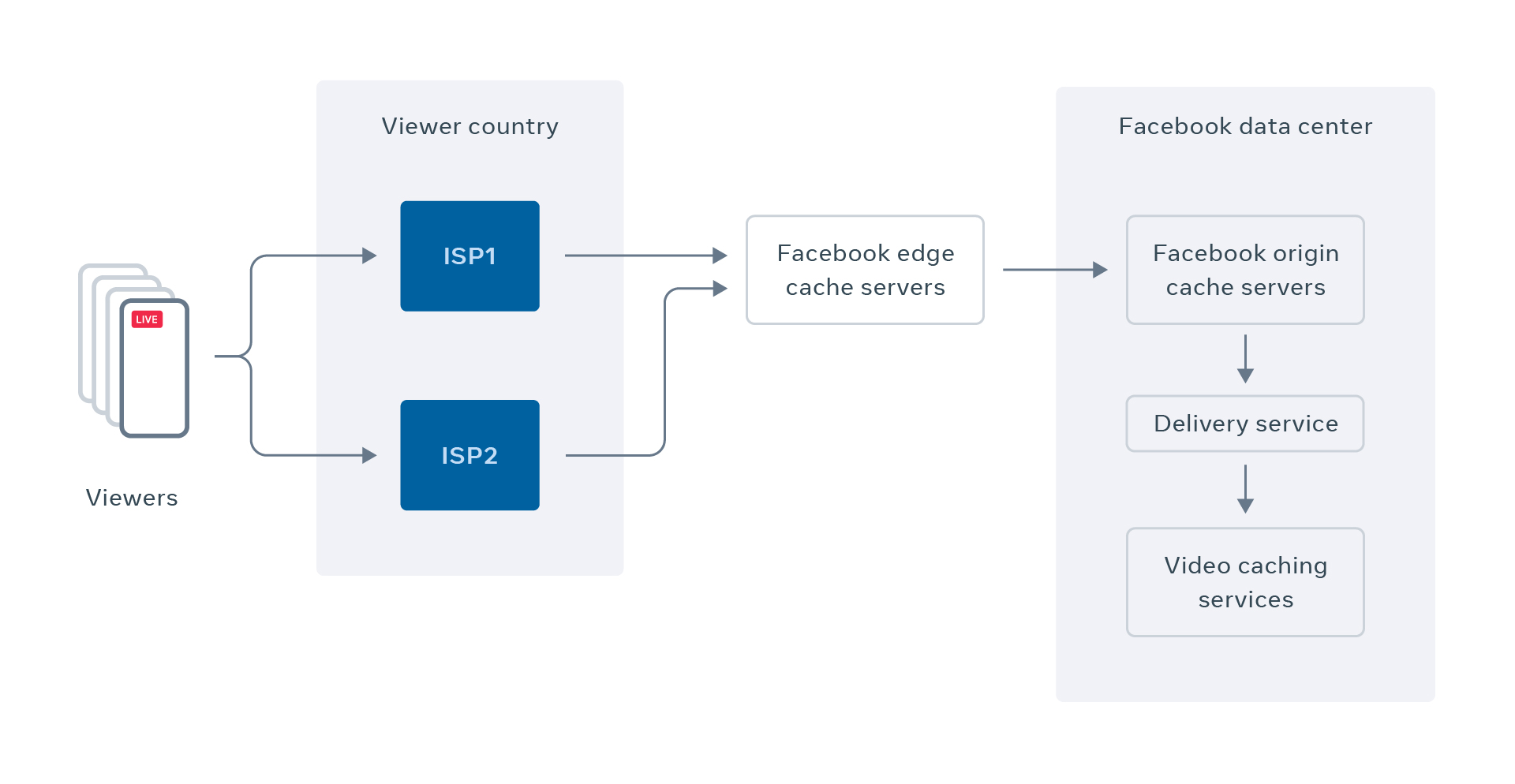
When serving video data, we work with ISPs when possible to prevent network overload because of these high-concurrency events. For example, when we found that viewer experience in Rio de Janeiro was degraded by congestion between Facebook and a particular ISP, we increased our local interconnection capacity from 20 Gbps to 120 Gbps.
As a result, we were able to keep almost all our Live video traffic within the viewer’s ISP’s network. This kept our traffic in-country and off congested international links, which benefits both the ISP (reducing its cost) and the viewers (improving their experience). With our Live video caches and dense connectivity to ISPs, we are closer to our viewers than ever before, so we can deliver higher-resolution video with fewer stalls. These investments ensured that millions of Facebook viewers had a seamless experience for the UEFA Champions League Final.
Looking forward
The streaming of the UEFA Champions League Final to 7.2 million concurrent viewers was a success and gave us more insight into last-mile connectivity challenges. We were able to seamlessly ingest the video, process it, and deliver it to the edge (where we interconnect with ISPs), but last-mile radio delivery was a big challenge for popular games because of limitations of current cellular technology. To solve this for the future, we are exploring using LTE-Broadcast to share a single copy of the stream for everyone on the same cell tower to overcome this last-mile challenge.
Investing in connectivity and internet infrastructure is important to help bring reliable, affordable internet to more people. We are nearing completion of a new submarine cable, which will improve connectivity and improve redundancy and resilience in Latin America. And we will continue to evaluate deployment of new edge locations in order to help create healthy ecosystems for interconnectivity between networks and keep traffic in-country, not only for Facebook but also between ISPs within the same country.
While this was a big milestone (and a learning experience) for us, it’s not the end of the road. Our next big challenge will be New Year’s Eve, which is the inverse of the challenges we faced with the UEFA Champions League Final. We traditionally see a spike of Live streams from individual devices as millions of people stream fireworks and celebrations at the same time when the clock strikes midnight around the world! For New Year’s Eve, instead of optimizing caches for a small number of very popular broadcasts, we need to optimize our processing, I/O, and storage for a huge number of simultaneous smaller-reach streams.








