
Our connectivity efforts focus on expanding internet access and adoption around the world. This includes our work on technologies like Terragraph, our collaboration with mobile operators on efforts to expand rural access, our work as part of the Telecom Infra Project, and programs like Free Basics. As we’ve continued working on Free Basics, we’ve listened to feedback and recommendations from civil society and other stakeholders. We have developed Discover specifically to address and incorporate those recommendations into a new product that supports connectivity. Today, Facebook Connectivity and our partners at Bitel, Claro, Entel, and Movistar are launching a trial of Discover in Peru.
Providing this service while keeping people safe from potential security risks was a tough technical challenge. We wanted to develop a model that would allow us to securely present webpages from all available domains, including their resources (scripts, media, style sheets, etc.). Below, we walk through the model we built, the unique architecture choices we made along the way, and the steps we’ve taken to mitigate risks.
Where we started
For Free Basics, our challenge was to find a way to provide a no-cost service to people who use the mobile web, even on feature phones with no third-party app support. Mobile carrier partners could provide the service, but network and gateway equipment constraints meant only traffic to certain destinations (usually IP address ranges or a list of domain names) could be made free of charge. With more than 100 partners globally and the time and difficulty involved in changing carrier network equipment configurations, we realized we needed to come up with a new approach.
That new approach required us to first build a web-based proxy service where the operator could make the service available free to a single domain: freebasics.com. From there, we would fetch webpages on behalf of the user and deliver them to their device. Even on modern browsers, there are some concerns with web-based proxy architectures. On the web, clients are able to evaluate security HTTP headers like cross-origin resource sharing (CORS) and Content Security Policy (CSP) and make use of cookies directly from the site. But in a proxy server configuration, the client is interacting with the proxy, and the proxy acts as a client to the site. Proxying third-party websites through a single namespace violates some assumptions around how cookies are stored, how much access scripts have to read or edit content, and how CORS and CSP are evaluated.
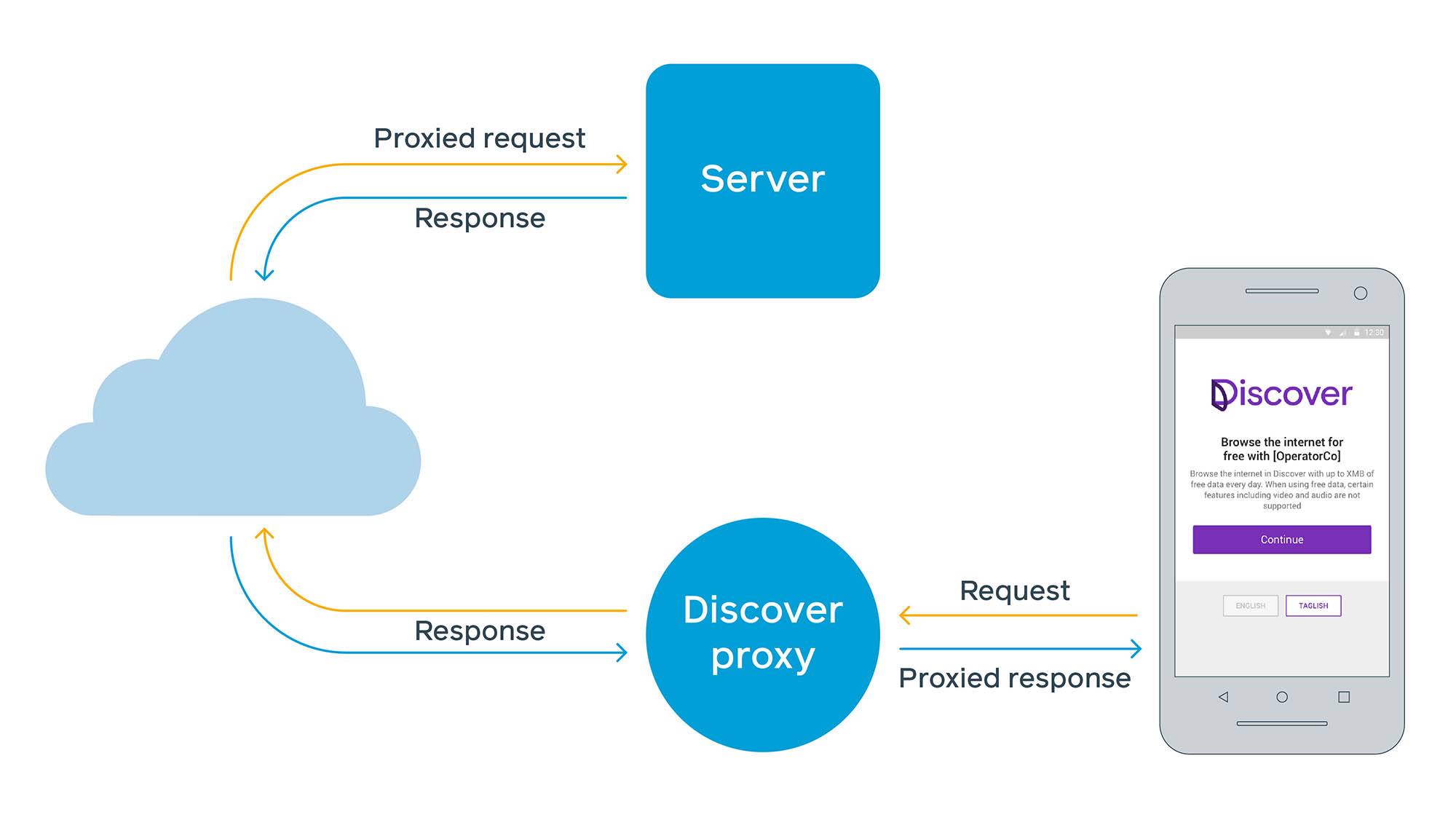
To address these concerns, we initially imposed some straightforward limitations, including which sites could be visited with Free Basics and the inability to run scripts. The latter has become more of an issue over time as many websites, including mobile sites, have started to rely on JavaScript for critical functionality, including content rendering.
Early architecture
Domain design
To accommodate the limited functionality of many mobile operator gateways, we considered alternative architectures, including:
- A cooperative solution where websites can allocate a subdomain (e.g.,
free.example.com) and resolve it to our IP space for operators to make it free of charge to the user.
This solution had pros:
- It allowed for direct end-to-end communication between client and server.
- It required minimal intervention on the proxy side.
However, it also had some cons:
- Sites needed to opt in to this scheme, incurring extra engineering costs for site owners.
- Browsers would have to request a specific domain through Server Name Indication (SNI), so the proxy would know where to connect. However, support for SNI isn’t universal, which made this solution less viable.
- If subscribers accidentally browsed to
example.comdirectly, rather than to thefree.example.comsubdomain, they would incur charges — and wouldn’t necessarily get redirected to the subdomain unless the operator had implemented some extra logic.
- IPv4-in-IPv6 encapsulation, where we can encapsulate the entire IPv4 space within a single free data IPv6 subnet. A customized DNS resolver then resolves IPv4 recursively and responds with encapsulated IPv6 answers.
This solution also had pros:
- It didn’t require cooperation from the website owner.
- There was no need for SNI to resolve the remote IP.
And cons:
- Browsers would see the
www.example.com.freebasics.comdomain, but thewww.example.comcertificate would result in an error. - Only a few carriers gateways supported IPv6 in this way.
- Even fewer devices supported IPv6, especially older OS versions.
Neither of these was a viable solution. Ultimately, we decided that the best possible architecture would be origin collapsing, where our proxy runs within a single origin-collapsed domain namespace under freebasics.com. Operators can then allowlist traffic to this destination more easily and keep their configurations simple. Each third-party origin is encoded in a subdomain, so we can guarantee that name resolution will always direct traffic to a free IP.
For example:
https://example.com/path/?query=value#anchor
Is rewritten to:
https://https-example-com.0.freebasics.com/path/?query=value#anchor
There is extensive server-side logic in place to make sure links and hrefs are correctly transformed. This same logic helps ensure that even HTTP-only sites are delivered securely over HTTPS on Free Basics between the client and the proxy. This URL rewriting scheme allows us to use a single namespace and TLS certificate, rather than requiring a separate certificate for every subdomain on the internet.
All internet origins become siblings under 0.freebasics.com, which raises certain security considerations. We were not able to take advantage of adding the domain to the Public Suffix List, as we would have to issue a different cookie for every origin, which would eventually exceed browser cookie limits.
Cookies
Unlike web clients, which can make use of cookies directly from the site, the proxy service requires a different setup. Free Basics stores user cookies on the server side for several reasons:
- Downlevel mobile browsers often have limited cookie support. If we issue even just one cookie per site under our proxy domain, we could be limited to setting just tens of cookies. If Free Basics were to set client-side cookies for each site under
0.freebasics.com, older browsers would quickly hit local cookie storage limits — and even modern browsers would reach a per-domain limit. - The domain namespace constraints that we needed to implement also precluded the use of sibling and hierarchical cookies. For instance, a cookie set on any subdomain at
.example.comwould normally be readable at any other subdomain. In other words, ifa.example.comsets a cookie on.example.com, thenb.example.comshould be able to read it. In the case of Free Basics,a-example-com.0.freebasics.comwould be setting a cookie onexample.com.0.freebasics.com, which isn’t allowed per the standard. Since that doesn’t work, other origins, likeb-example-com.0.freebasics.com, wouldn’t be able to access cookies set for their parent domain.
To allow the proxy service to access this server-side cookie jar, Free Basics leverages two client-side cookies:
- The
datrcookie, a browser identifier used for site integrity purposes. - The
ick(internet cookie key), which contains a cryptographic key used to encrypt the server-side cookie jar. As this key is stored only on the client side, the server-side cookie jar cannot be decrypted by Free Basics when the user isn’t utilizing the service.
To help protect user privacy and security when storing their cookies in a server-side cookie jar, we make sure that:
- Server-side cookies are encrypted with an
ickthat’s kept only on the client. - When the client provides the
ick, it is forgotten by the server in each request without ever being logged. - We mark both client-side cookies as
SecureandHttpOnly. - We hash the index of a cookie using the client-side key so that the cookie isn’t traceable back to the user when the key is not present.
Allowing scripts to run risks the fixation of server-side cookies. To prevent this, we exclude the use of JavaScript from Free Basics. Additionally, even though any website can be part of Free Basics, we review each site individually for potential abuse vectors, regardless of content.
Improving what we had built
To support a model serving any website, with the ability to run scripts more securely, we needed to significantly rethink our architecture to prevent threats, such as scripts being able to either read or fixate the user’s cookies. JavaScript is extremely difficult to analyze and prevent unintended code from being executed.
As an example, here are some ways an attacker could inject code that we would need to be able to filter:
setTimeout(['alert(1)']);
location = ' javascript:alert(1) <!--';
location = 'javascript\n:alert(1) <!--';
location = '\x01javascript:alert(1) <!--';
var location = 'javascript:alert(1)';
for(location in {'javascript:alert(1)':0});
[location] = 'javascript:alert(1)';
location.totally_not_assign=location.assign;
location.totally_not_assign('javascript:alert(1)');
location[['href']] = 'javascript:alert(1)';
Reflect.set(location, 'href', 'javascript:alert(1)')
new Proxy(location, {}).href = 'javascript:alert(1)'
Object.assign(window, {location: 'javascript:alert(1)'});
Object.assign(location, {href: 'javascript:alert(1)'});
location.hash = '#%0a alert(1)';
location.protocol = 'javascript:';The model we came up with extended the Free Basics design, but it also protects the cookie that is storing the encryption key from being overwritten by scripts. We use an outer frame that we trust to attest that the inner frame, which presents third-party content, is not being tampered with. The following section shows in detail how we mitigate session fixation and other attacks, such as phishing and clickjacking. We lay out a method to safely serve third-party content while enabling JavaScript execution.
Architecture improvements in Discover
References to the domain at this point will change to our new domain, a similarly origin-collapsed discoverapp.com.
JavaScript and cookie fixation
In allowing JavaScript from third-party sites, we have had to acknowledge that this enables certain vectors for which we needed to prepare, as scripts can modify and rewrite links, access any part of the DOM, and, in the worst case, fixate client-side cookies.
The solution we came up with needed to address cookie fixation, so instead of trying to parse and block certain script calls, we decided to detect it as it happens and render it useless. This is achieved by the following:
- On signup, we generate a new, secure random
ick. - We send
ickto the browser as anHttpOnlycookie. - We then HMAC a value called
icktfrom a digest of bothickanddatr(to avoid fixation for both) and store a copy ofickton the client, in a location inlocalStorageto which a potential attacker cannot write. The location we use ishttps://www.0.discoverapp.com, which never serves third-party content. Since this origin is sibling to all third-party origins, domain lowering or any other kind of domain modification cannot occur, and the origin is deemed trusted. - We embed
ickt, derived from theickcookie seen in the request, inside the HTML in every third-party proxy response. - When the page loads, we compare the embedded
icktwith the trustedicktusingwindow.postMessage(), and invalidate the session if there’s a mismatch by deleting thedatrandickcookies. - We prevent user interaction with the page until this process completes.
As additional protection, we set a new datr cookie if we detect multiple cookies at the same location, embedding a timestamp so we can always use the most recent one.
Two-frames solution
For validation, we need a way for a third-party page to query the ickt value and validate it. We do this by embedding the third-party site within an <iframe> in a page at the secure origin and injecting a piece of JavaScript into the third-party site. We build a secure outer frame and a third-party inner frame.
Inner frame
Within the inner frame, we inject a script into every proxied page we serve. We also inject the ickt value calculated from the ick seen in the request along with it. The inner frame’s behavior is as follows:
- Check with outer frame:
postMessageto top withicktembedded in the page.- Wait.
- If the script gets an acknowledgement from the secure origin, we let the user interact with the page.
- If the script waits too long or gets a reply from an unexpected origin, we’ll navigate the frame to an error screen with no third-party content (our “Oops” page), because it’s possible the outer frame is either not there or is different than the inner frame expects.
- Check with
parent:postMessagetoparent.- Wait.
- If the script gets a reply with
source===parentand origin under.0.discoverapp.com, it will proceed. - If the script waits too long, or gets a reply from an unexpected origin, we’ll navigate to the “Oops” page.
Some notes on the inner frame:
- Even if it is circumvented, potential attackers would be able to fixate only on an origin they can achieve code execution on, making cookie fixation vectors redundant.
- We assume that a benign origin will not deliberately circumvent the inner-outer messaging protocol.
Outer frame
The outer frame is there to attest that the inner frame is consistent:
- We make sure that the outer frame is always the top frame with JavaScript and
X-Frame-Options: DENY. - Wait for
postMessage. - If the outer frame receives a message:
- Is it from an inner frame origin?
- If yes, does it report the correct
icktvalue?- If yes, send an acknowledgment message.
- If no, delete the session, delete all the cookies, and navigate to a safe origin.
- If the outer frame does not receive a message for a few seconds or the subframe is not the topmost inner frame, we remove the location from the secure frame’s address bar.
Page interaction
To avoid race conditions where a person might enter a password under a fixated cookie before the inner frame has completed verification, it is important to prevent people from interacting with the page before the inner frame’s verification sequence completes.
To prevent this, the server adds style="display:none" to the <html> element of every page. The inner frame will remove it when it gets the outer frame’s confirmation.
JavaScript code is still allowed to run, and resources are still fetched. But as long as the person hasn’t entered any input to the page, the browser does nothing a potential attacker couldn’t have done simply by visiting the site — unless the site is already vulnerable to cross-site request forgery (CSRF).
By choosing to go with this solution, we then had to solve for other possible outcomes, specifically:
- Asynchronous cookie fixation.
- Clickjacking due to framing.
- Phishing impersonating the Discover domain.
Asynchronous cookie fixation
Up to this point, the protections we have implemented have accounted for synchronous fixations, but they can also occur asynchronously. To prevent this, we use a classic CSRF prevention method. We require POSTs to carry a query parameter with the datr seen when the page loaded. We then compare the query param with the datr cookie seen in the request. If they do not match, we do not fulfill the request.
To avoid datr leakage, we embed an encrypted version of the datr inside the inner frame and ensure that this query parameter is added to every <form> and XHR object. Since the page cannot derive the datr token on its own, the datr added is the one seen at that time.
For anonymous requests, we require them to have the datr query param, as well. Anonymity is preserved because we do not leak it to the third-party site — the ick cookie is missing, so we cannot use the cookie jar. However, in this case, we are not able to validate against the datr cookie, so anonymous POSTs can be made under fixated sessions. But since they’re anonymous and lacking the ick, no sensitive information can leak.
Clickjacking
When a site sends X-Frame-Options: DENY, it will not load in an inner frame. This header is used by websites to prevent exposure to certain types of attacks, such as clickjacking. We remove that header from the HTTP response but ask the inner frame to verify that parent is the top window frame using postMessage. If validation fails, we navigate the user to the “Oops” page.
Phishing
The “address bar” we provide in the secure frame is used to expose the topmost inner frame origin to the user. However, it can be copied by phishing sites that impersonate Discover. We prevent malicious links from navigating away from Discover by preventing top navigation using <iframe sandbox>. The outer frame can be escaped only by directly navigating to another site.
Client-side cookies
The document.cookie allows JavaScript to read and modify cookies that aren’t marked HttpOnly. Supporting this securely is challenging in a system that maintains the cookies on the server.
Accessing cookies: When a request is received, the proxy will enumerate all the cookies that are visible to that origin. It will then attach a JSON payload to the response page. Client-side code is injected to shim document.cookie and make these cookies visible to other scripts, as if they were real client-side cookies.
Modifying cookies: If scripts are allowed to arbitrarily set cookies that the server then accepts, this could lead to fixation, where origin evil.com could set a sensitive cookie on example.com.
Trusting the browser’s CORS capabilities would not be enough in this case — origin a.example.com trying to set a cookie on example.com will be blocked by the browser, since these origins are siblings and not hierarchical.
Even so, when the server receives a new cookie set by the client, it cannot securely enforce whether the target domain is allowed; the writer’s origin is known only on the client and isn’t always sent to the server in a way we can trust.
To force the client to prove it is eligible to set cookies on a specific domain, the server will send, in addition to the JSON payload, a list of cryptographic tokens for each of the origins at which the requesting origin is allowed to set cookies. These tokens are salted with the ick value, so they cannot be transferred between users.
The client-side shim for document.cookie takes care of resolving and embedding the token in the actual cookie text that is sent to the proxy. The proxy can then verify that the writing origin indeed possessed the token to write to the cookie’s target domain, and stores it in the server-side cookie jar, sending it to the client again the next time the page is requested.
Bootstrap protocol
The model contains three origin types: portal origin (Discover portal, etc.), secure origin (outer frame), and rewrite origin (inner frame). Each has a different need:
- Portal origin requires
datr. - Secure origin requires
ickt. - Rewrite origin requires
datrandick.
With localStorage protocol
Here’s a representation of the bootstrap process for most modern mobile browsers:
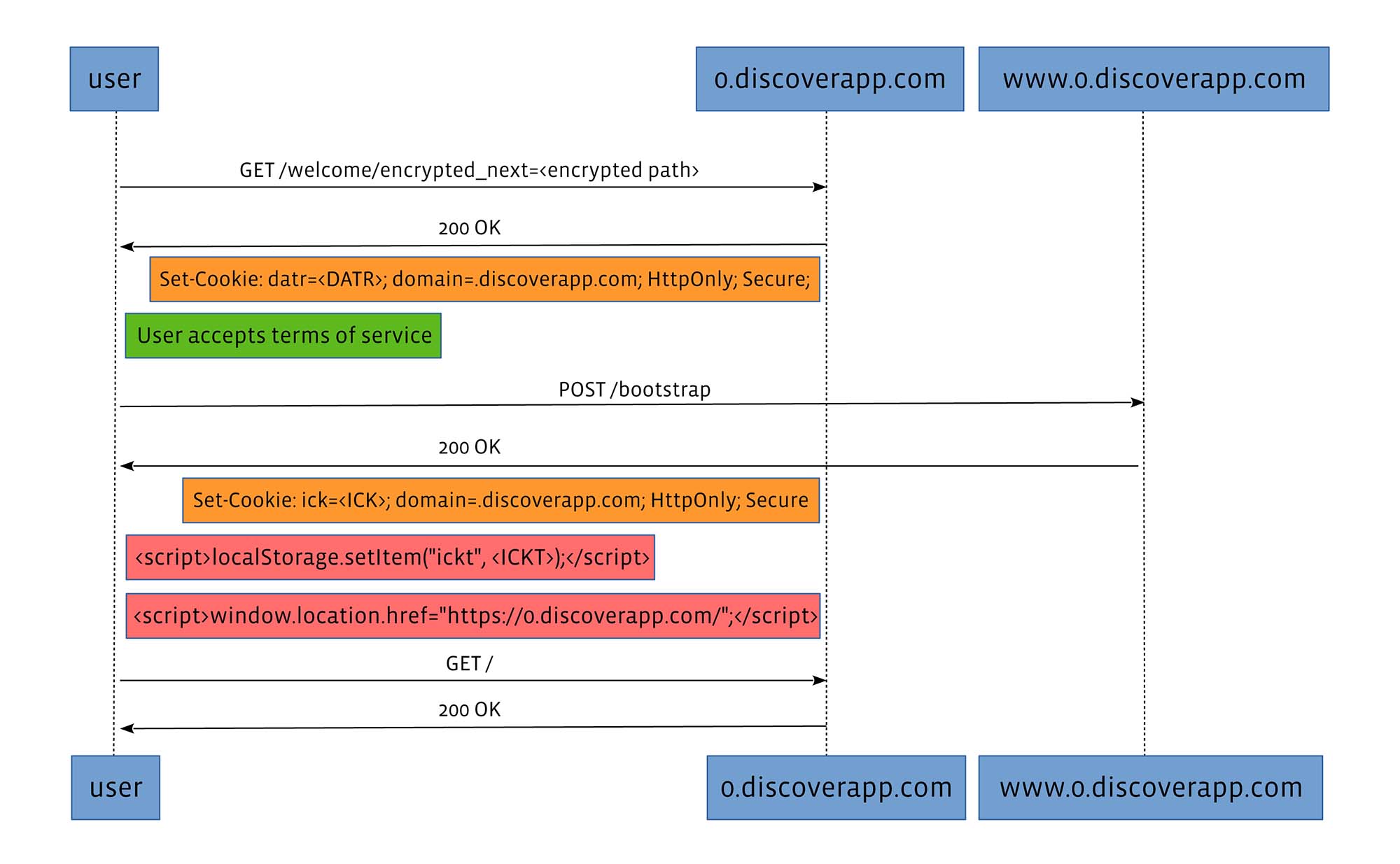
It’s important to note that to avoid reflection, the bootstrap endpoint at the secure origin always issues a new ick and ickt; ick never depends on user input. Note that because we set domain=.discoverapp.com on both ick and datr, they are available in all origin types, and ickt is available only on the secure origin.
Without localStorage protocol
Because certain browsers, such as Opera Mini (popular in many countries where Discover operates), do not support localStorage, we are unable to store the ick and ickt values. This means we have to use a different protocol:
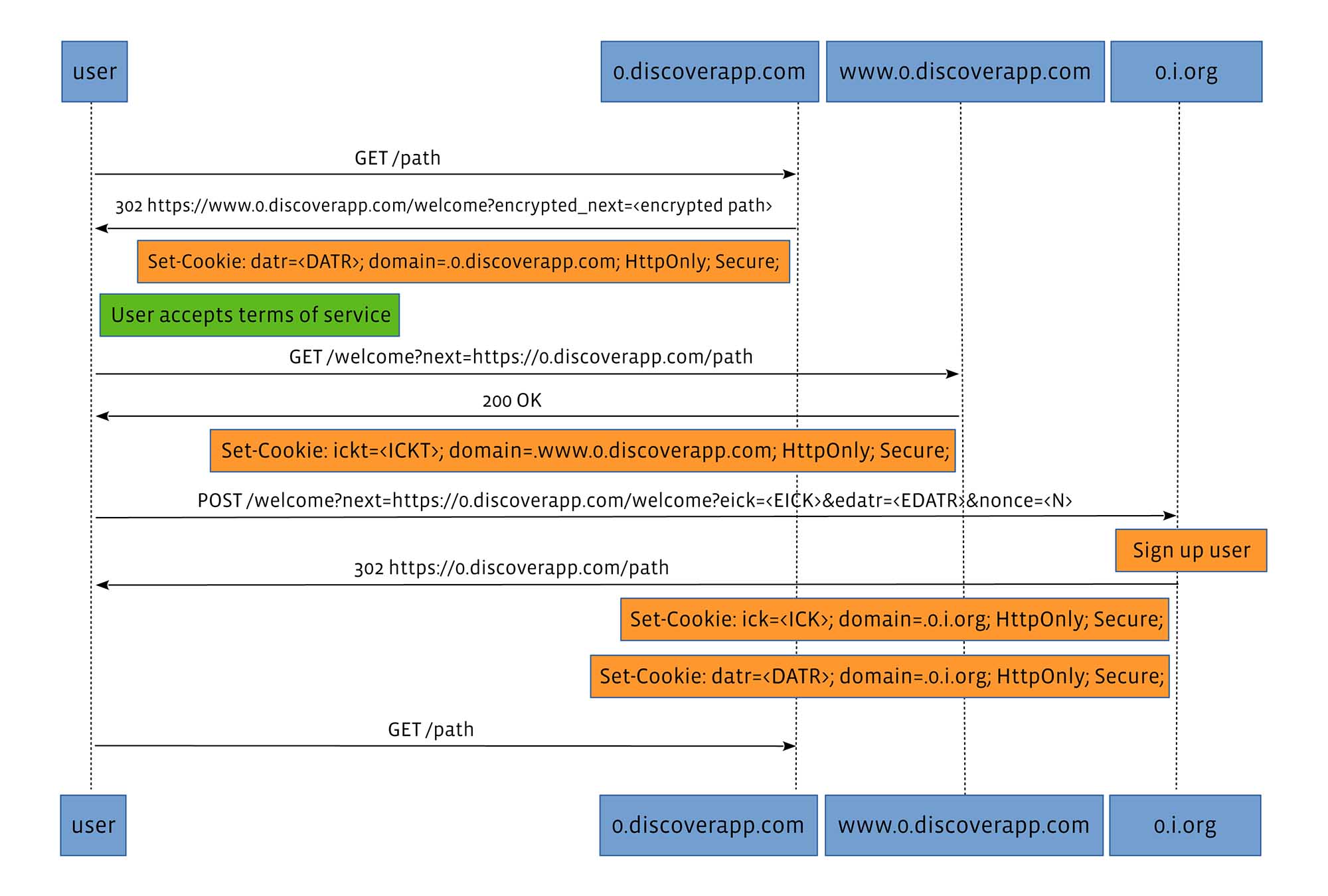
We decided to separate the rewrite origin from the secure origin so that they do not share the same host suffix as per the Public Suffix List. We use www.0.discoverapp.com for storing the secure copy of ickt (as a cookie), and move all third-party origins under 0.i.org. In a well-behaved browser, setting a cookie on the secure origin will make it inaccessible to all rewrite origins.
Since the origins are now separate, our bootstrap process becomes a two-step process. Before, we could set ick in the same request we provision localStorage with ickt. Now, we need to bootstrap two origins, in separate requests, without opening ick fixation vectors.
We solve this by bootstrapping the secure origin with the ickt cookie first and giving the user an encrypted version of ick, with a key known only to the proxy. The ick ciphertext is accompanied with a nonce that can be used to decrypt that particular ick in the rewrite origin and set a cookie, but only once.
An attacker could choose to either:
- Use the nonce to reveal the
ickcookie. - Pass it to the user to fixate its value.
In either case, the attacker cannot simultaneously know and force a particular ick value on a user. The process also synchronizes datr between the origins.
This architecture has been through substantial internal and external security testing. We believe we have developed a design that is robust enough to resist the types of web application attacks we see in the wild and securely deliver connectivity that is sustainable for mobile operators. Following the launch of Discover in Peru, we’re planning to roll out additional Discover trials with partner operators in a number of other countries where we have been beta testing product features, including Thailand, the Philippines, and Iraq. We anticipate that Discover will be live in these additional countries in the coming weeks, and we’ll explore additional trials where partner operators want to participate.
We’d like to thank Berk Demir for his help on this work.
In an effort to be more inclusive in our language, we have edited this post to replace “whitelist” with “allowlist.”



")




