Aria is a set of initiatives to dramatically increase PrestoDB efficiency. Our goal is to achieve a 2-3x decrease in CPU time for Hive queries against tables stored in ORC format. For Aria, we are pursuing improvements in three areas: table scan, repartitioning (exchange, shuffle), and hash join. Nearly 60 percent of our global Presto CPU time is attributed to table scan, making scan improvements high leverage and thus the area we chose to focus on first. Table scan optimizations are specific to queries that access data stored in ORC format but can be extended to support Parquet as well. This post describes how we are making table scan more efficient.
We aim to reduce CPU time by using the following strategies:
- Subfield pruning: We have large amounts of data stored using complex types: maps, arrays, and structs. Machine learning workloads and various frameworks tend to create very large values, maps with hundreds and sometimes thousands of keys, but the queries access only a handful of these. Extracting these values from ORC files and converting them into Java objects is computationally intensive. Pruning complex types while extracting data from ORC files can save a lot of CPU cycles.
- Adaptive filter ordering: Some filters are more efficient than others; they drop more rows in fewer CPU cycles. Today, Presto evaluates filters in the order in which they have been specified in SQL. Adaptively changing the order in which filters are applied saves CPU cycles by reducing the amount of data that is extracted from the ORC file. Not projecting the columns that are used only to filter data saves CPU cycles as well.
- Efficient row skipping: Currently, if a filter on one column matches for only a handful of rows, Presto still reads all values in later columns and immediately discards most of them. Skipping rows by reading and throwing away individual values is wasteful. With efficient row skipping, we can read only the necessary values. Implementing proper skipping in the ORC readers saves CPU cycles.
As part of Aria, we are reimplementing scan to support subfield pruning, adaptive filter ordering, and efficient row skipping to achieve performance gains by doing less work. We have a working prototype of the scan optimizations that shows ~20 percent CPU gains on a small sample of production workload for the overall query. We ran this experiment on the same sample that we use to verify Presto releases.
New architecture of scan
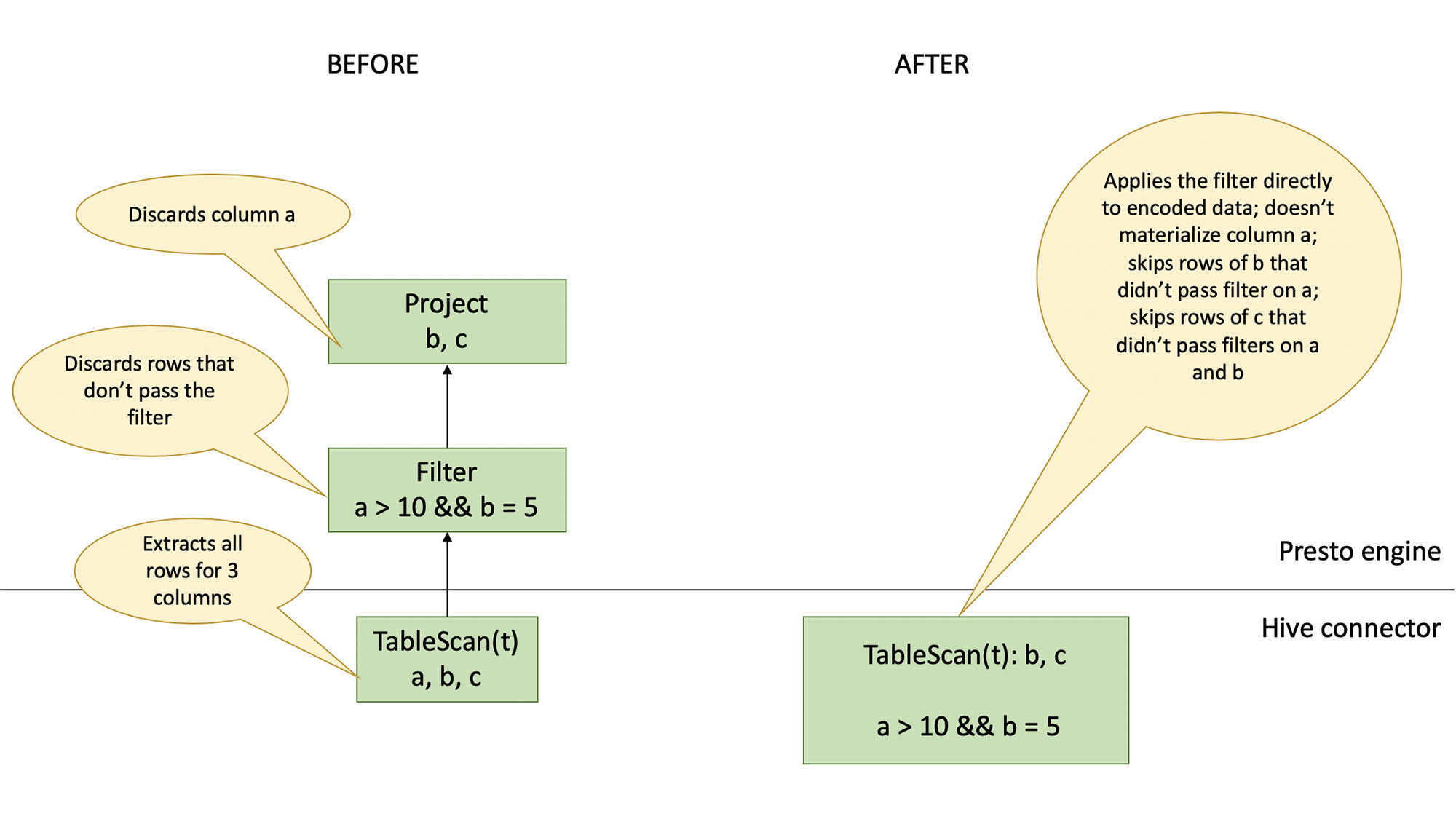
In the new implementation, we are shifting filter evaluation from the engine into the Hive connector. We also add an optimizer rule to collect subfields that are referenced in the query and pass this info to the connector to enable subfield pruning. The scan logic for query SELECT counts[“red”] FROM t will no longer produce a counts map with all available keys. It will instead produce maps with at most one key (“red”). The rest of the keys and their values will be discarded with efficient skipping at the stage of decoding from ORC.
Stream reader
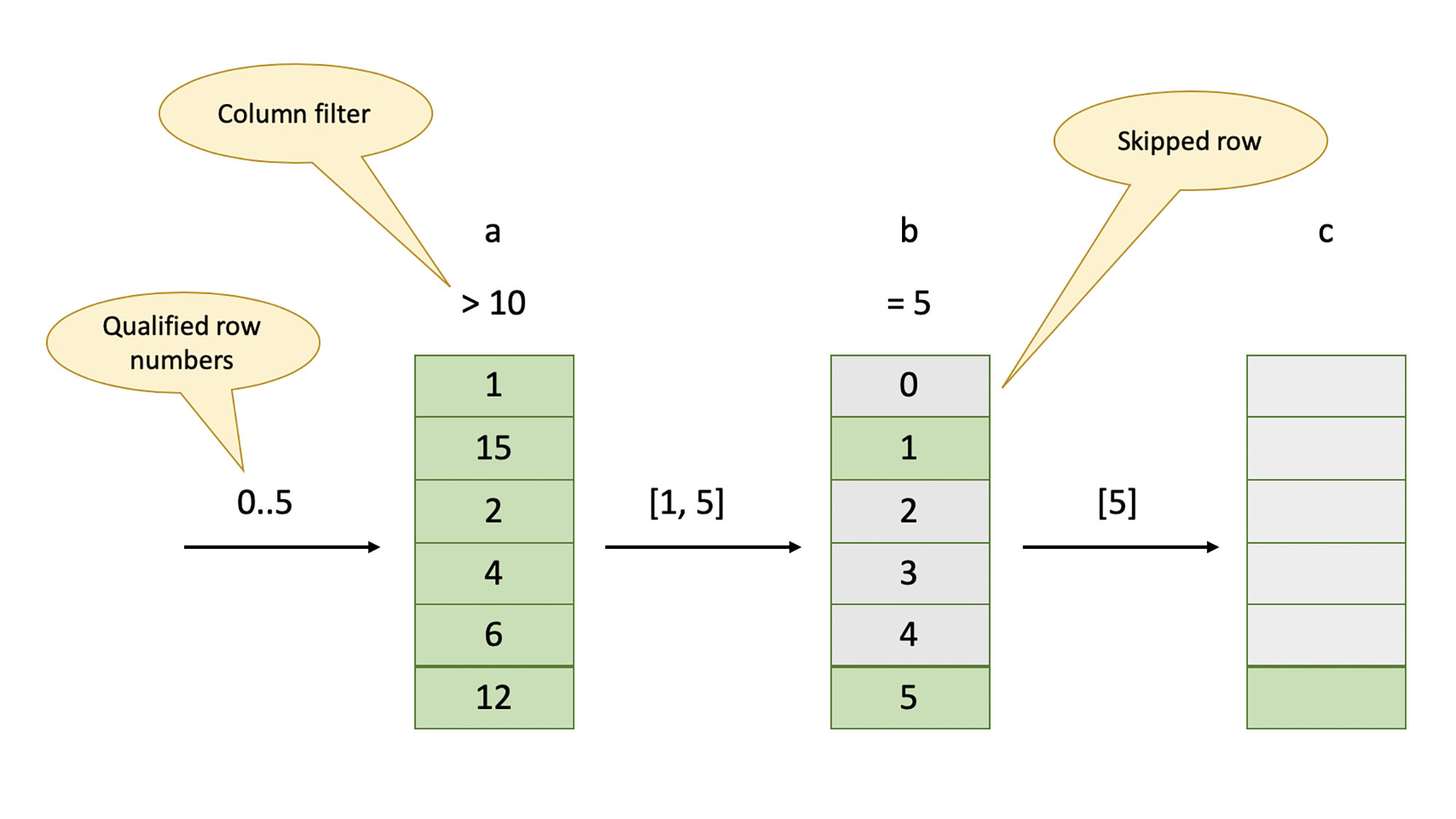
A stream reader is responsible for extracting a chunk of rows from a single column. There are different stream readers for different types of columns and different encodings. In the new implementation, a stream reader is also responsible for applying simple filters to individual columns.
A stream reader takes an array of row numbers as input, extracts the corresponding values from the ORC file, applies a filter (if present), buffers the values that matched the filter, and then produces a new array of row numbers. This new array is a subset of the input array and contains only rows that passed the filter. The output array will be the same if a column doesn’t have a filter. The next stream reader consumes the row numbers produced by a stream reader. The first stream reader receives a contiguous range of row numbers. Below is an illustration of scan for a SELECT b, c FROM t WHERE a > 10 AND b = 5 query.
.
Record reader
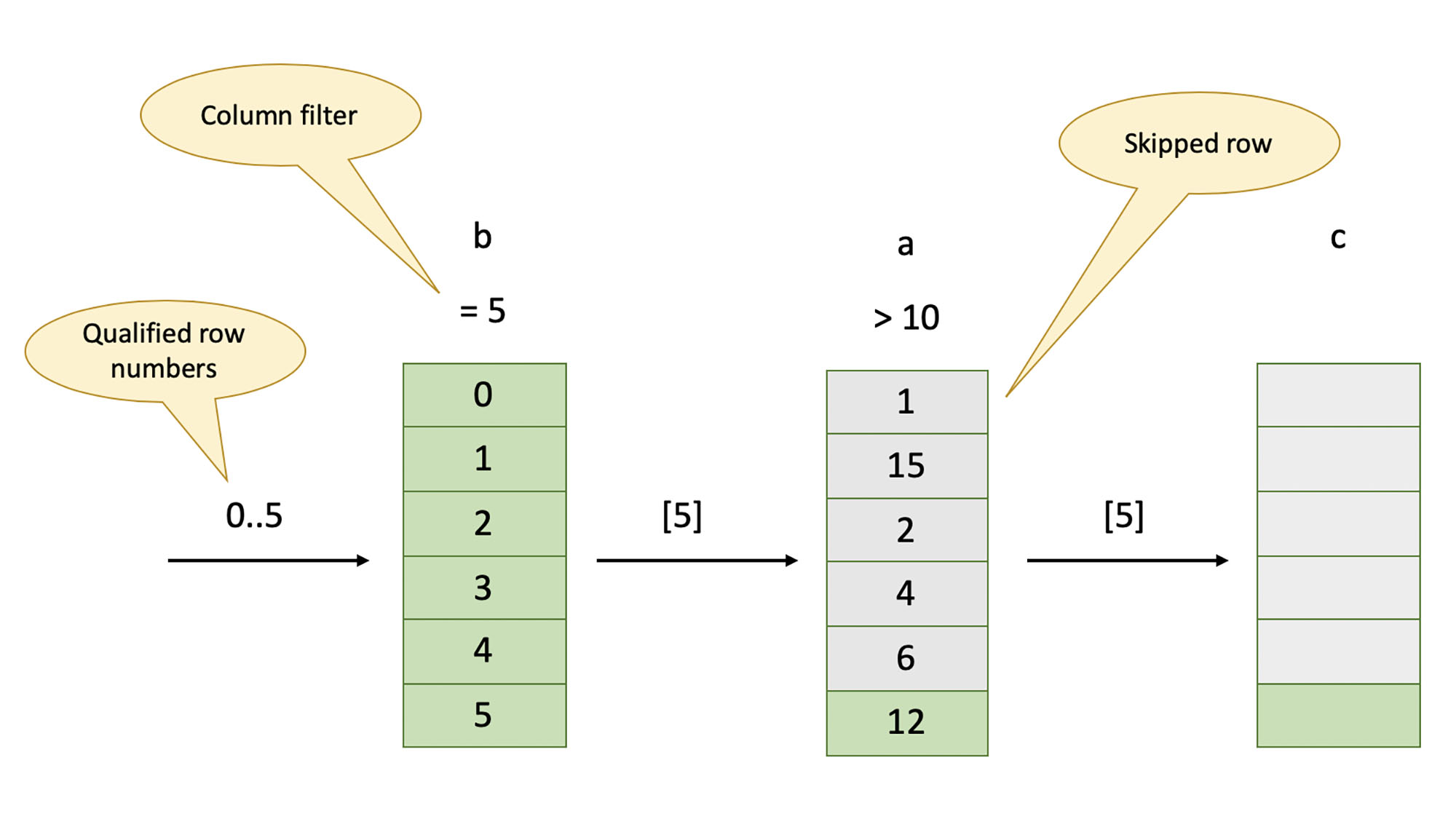
Record reader drives the scan by coordinating the work of individual stream readers. It also tracks filter efficiency and changes the order in which columns are scanned to allow the most efficient filters to be applied first, and ensures that columns with no filters are scanned last. Record reader instructs individual stream readers on whether they should buffer the extracted data or discard it as soon as the filter has been evaluated (e.g., if the column is not projected out) and passes the arrays of row numbers between the stream readers. The following diagram shows the scan after a change in filter order.
Record reader is also responsible for evaluating filters that require multiple columns or use nontrivial expressions. We refer to these as filter functions. The full set of filters (simple and complex) is considered when choosing the optimal order of scanning. Consider this query:
SELECT b, c FROM t WHERE a > 10 AND b = 5 AND a + b mod 2 = 0 There are two simple filters on columns a (a > 10) and b (b = 5) and a filter function that involves 2 columns: a + b mod 2 = 0. Stream readers evaluate simple filters, and the record reader evaluates filter functions.
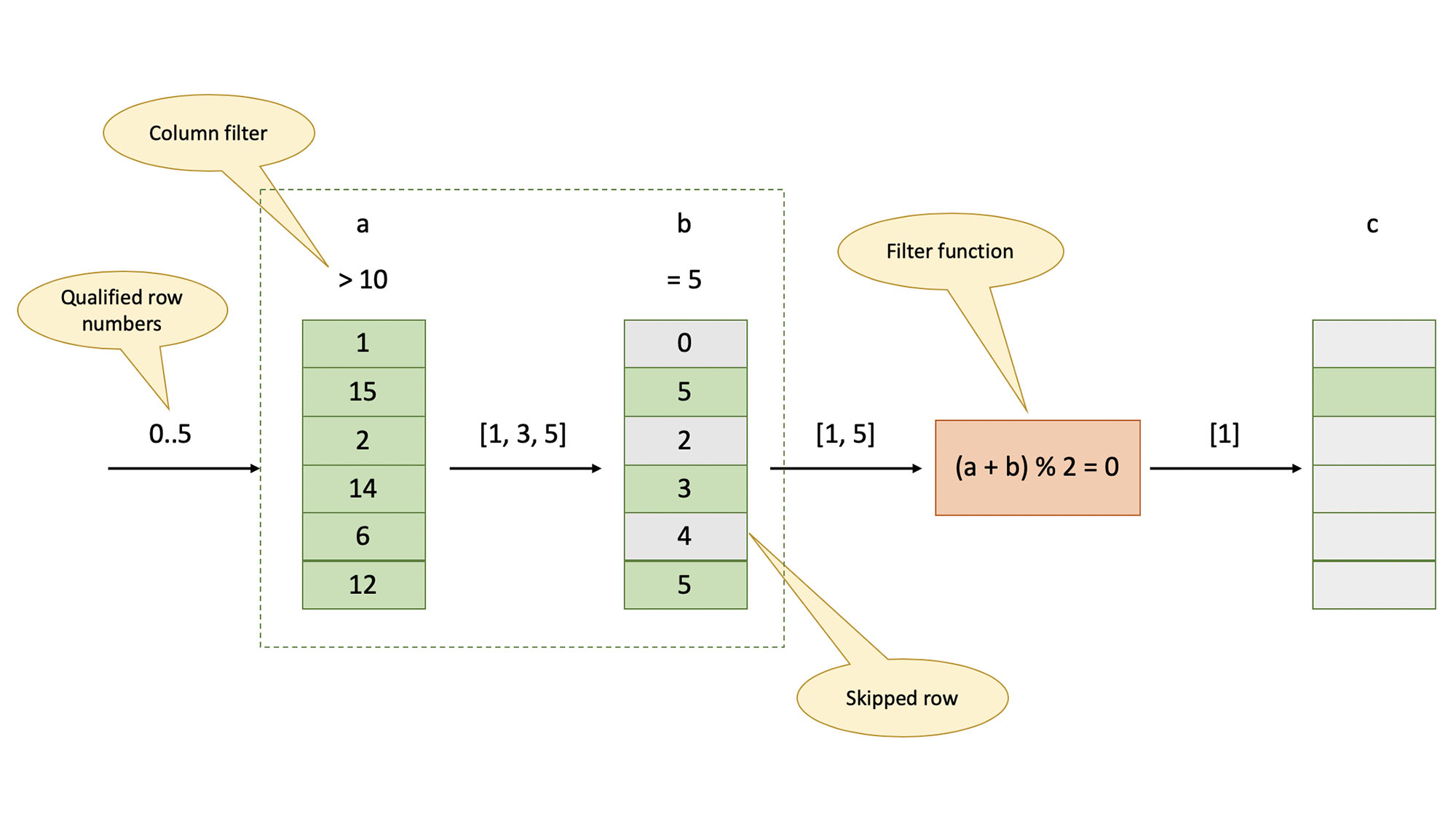
In the presence of filters, stream readers that run first may extract more rows than subsequent readers. After the last stream reader has run, record reader uses the array of surviving row numbers to extract only necessary data from all the readers and form a result.
Next steps for Aria
We are now working on productionizing our prototype. The optimizations we describe here can be applied to scanning data stored in Parquet format as well. We are also pursuing improvements for repartitioning (exchange, shuffle) and hash join. Those optimizations will benefit all queries, regardless of the storage format. To follow our progress on Aria, contribute to the project, or share feedback, please join us on GitHub.








