
Hash tables provide a fast way to maintain a set of keys or map keys to values, even if the keys are objects, like strings. They are such a ubiquitous tool in computer science that even incremental improvements can have a large impact. The potential for optimization led to a proliferation of hash table implementations inside Facebook, each with its own strengths and weaknesses. To simplify the process of selecting the right hash table, we built F14, a 14-way probing hash table within Folly, our open source library of C++ components. The F14 hash tables outdo our previous specialized implementations while avoiding their pathologies. F14 is a good default — usually a great choice and never a bad one, regardless of the use case.
On a programming forum, when engineers ask “What’s the best C++ hash table?” they really mean “Which C++ hash table has the best set of trade-offs for my scenario?” For us, this question used to lead to a litany of follow-up questions, such as:
- Do you keep long-lived references or pointers to the entries?
- Do you care more about CPU or memory?
- How big are your keys?
- How big are your tables?
- What is the operation mix between insertions, searches, and iteration?
- Are the keys strings?
- How often do you erase?
- … Can you post a link to your code?
Clearly, it’s hard to make the best choice when there are so many factors to consider. With F14, we have condensed this list to one simple choice: If you don’t keep long-lived references to entries, start with folly::F14FastMap/Set. Otherwise, start with folly::F14NodeMap/Set. F14 is part of Folly, Facebook’s open source library of C++ components.
Improving hash table implementation with F14
Hash tables are useful because they are fast. The theoretical average running time for find, insert, and erase is the optimal O(1) — meaning no matter how big the hash table gets, the average number of steps needed to perform those operations on any hypothetical computer has a fixed limit. In practice, of course, one hash table implementation might be consistently better than another. We can’t improve on the theory of hash tables, but we can improve on the practice. In particular, F14 provides practical improvements for both performance and memory. It does this by exploiting the vector instructions available on modern CPUs, providing multiple memory layouts, and paying careful attention to detail. It is easy to use well, integrates with testing tools, and enables advanced features by default.
Hash tables start by computing a numeric hash code for each key and using that number to index into an array. The hash code for a key is always the same, and hash codes for different keys are likely to be different. That means that the keys in a hash table are distributed randomly across the slots in the array. Much of the variation between hash table algorithms comes from how they handle collisions (multiple keys that map to the same array index). Algorithms generally use either chaining, which uses a secondary data structure such as a linked list to store all the keys for a slot, or probing, which stores keys directly in the main array and then keeps checking new slots if there is a collision.
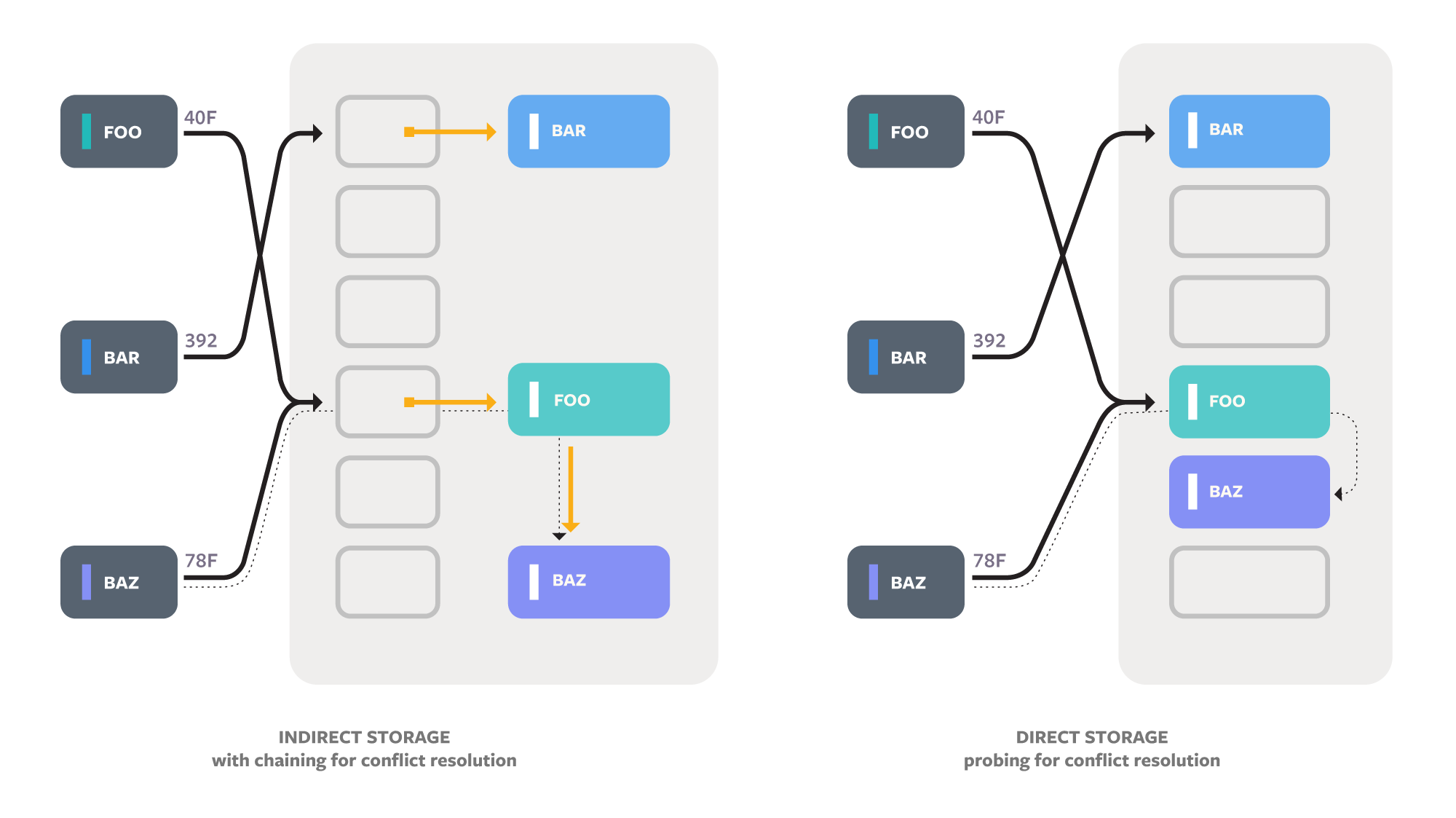
If we divide the number of keys by the size of the main array, we get a number called the load factor, which is a measure of the hash table’s fullness. Decreasing the load factor by making the main array larger reduces the number of collisions but wastes memory. General-purpose hash tables keep the load factor from getting too high by rehashing, or moving entries to a new, larger array.
The standard template library (STL) for C++ provides hash tables via std::unordered_map and std::unordered_set. The standard guarantees reference stability: References and pointers to the keys and values in the hash table must remain valid until the corresponding key is removed. In practice, this means the entries must be indirect and individually allocated, which adds a substantial CPU overhead. Folly has chosen to expose a fast C++ class without reference stability as well as a slower C++ class that allocates each entry in a separate node. The node-based version is not fully standard compliant, but it is drop-in compatible with the standard version in all the real code we’ve seen.
Reducing collisions with vector instructions
Collisions are the bane of a hash table: Resolving them creates unpredictable control flow and requires extra memory accesses. Modern processors are fast largely because of pipelining — each core has many execution units that allow the actual work of instructions to overlap. This strategy works well only if the CPU can accurately predict the outcome of if statements and loops, and it’s hard to predict whether a key will have a collision.
The core idea of F14 is to use the hash code to map keys to a chunk (a block of slots) instead of to a single slot, then search within the chunk in parallel. The intra-chunk search uses vector instructions (SSE2 or NEON) to filter all the slots of the chunk at the same time. We call our algorithm F14 because it filters 14 slots at once (this chunk size is a good trade-off between cache alignment and collision rate). F14 performs collision resolution if a chunk overflows or if two keys both pass the filtering step. The two-step search is a bit more work than in a normal hash table algorithm when neither has a collision, but F14 is faster overall because there’s a much lower probability that a collision will interfere with instruction pipelining.
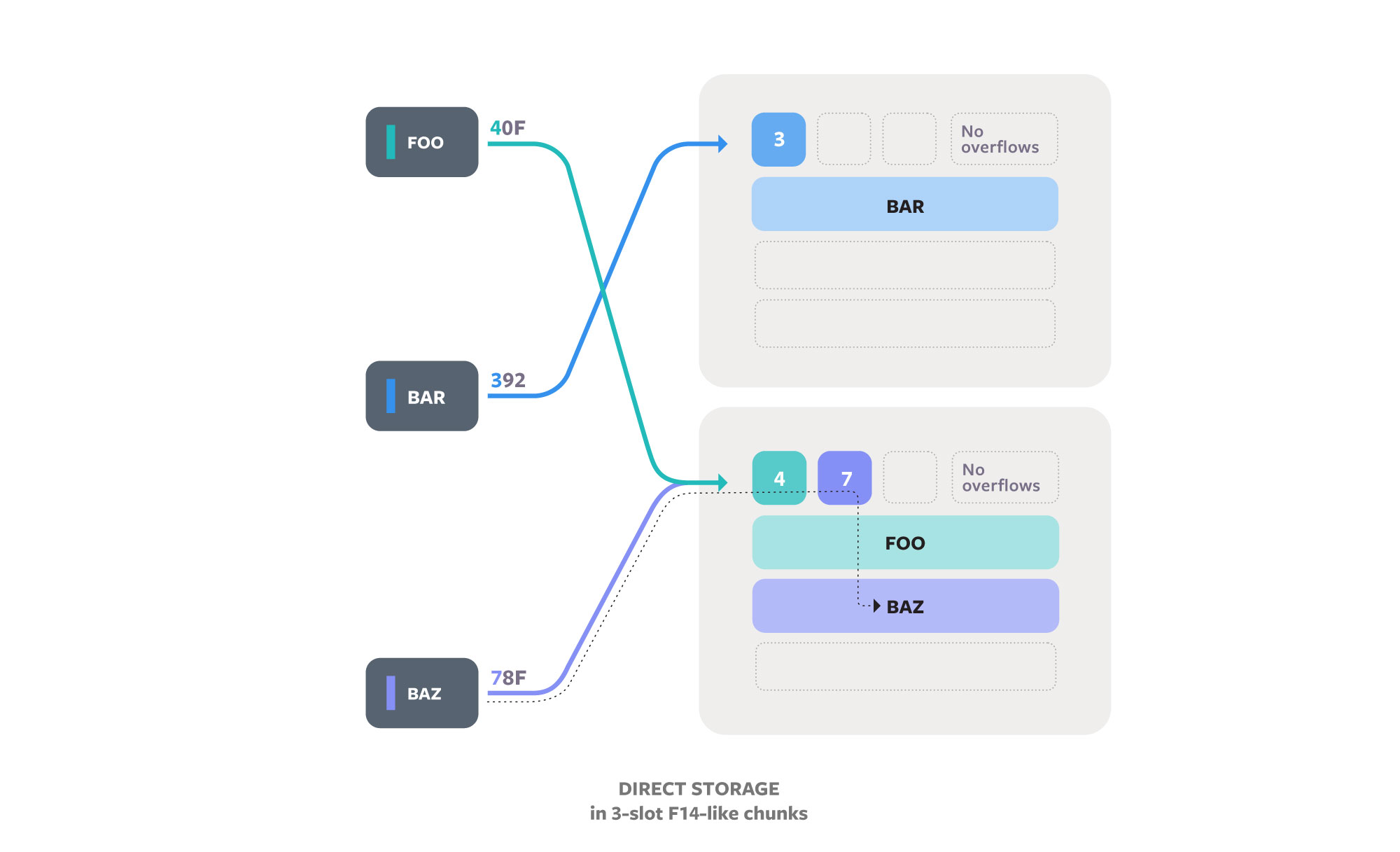
Chunking is an effective strategy because the chance that 15 of the table’s keys will map to a chunk with 14 slots is much lower than the chance that two keys will map to one slot. For instance, imagine you are in a room with 180 people. The chance that one other person has the same birthday as you is about 50 percent, but the chance that there are 14 people who were born in the same fortnight as you is much lower than 1 percent. Chunking keeps the collision rate low even for load factors above 80 percent. Even if there were 300 people in the room, the chance of a fortnight “overflow” is still less than 5 percent.
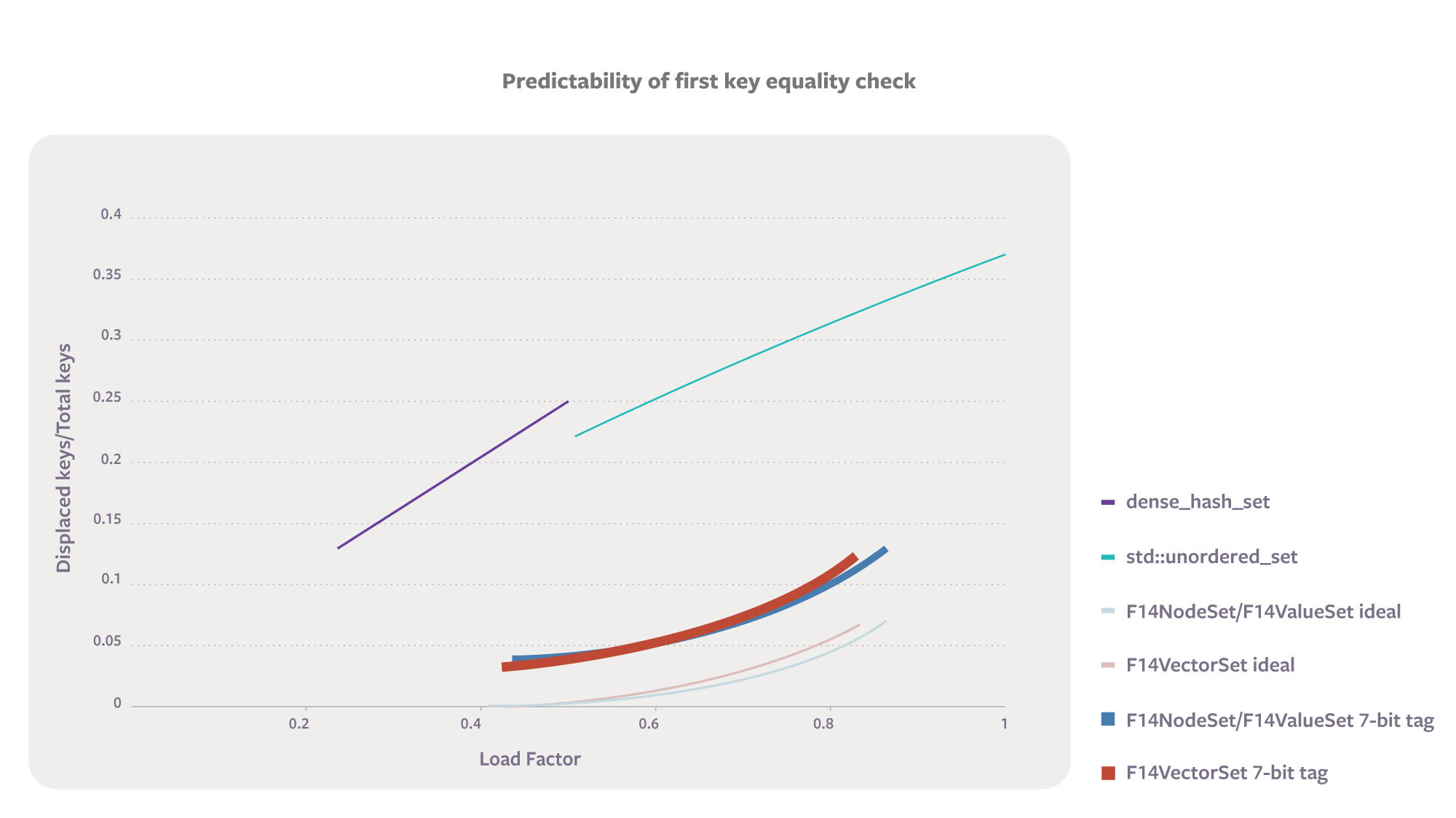
Below is a plot of the likelihood that an algorithm won’t find a search key in the very first place it looks. The happiest place on the graph is the bottom right, where the high load factor saves memory and the lack of collisions means that keys are found quickly with predictable control flow. You’ll notice that the plot includes lines for both “F14 ideal” and “F14 with 7-bit tag.” The former includes only chunk overflow, while the latter reflects the actual algorithm. There’s a 1/128 chance that two keys have the same 7-bit tag even with a high-quality hash function.
Reference-counted tombstones
Most probing strategies keep looking until they find an empty slot. That makes erasing keys tricky. The algorithm must either leave a tombstone (an empty slot that doesn’t terminate the probe search) or slide down the later keys in the probe sequence, which becomes very complex for robust probing strategies. In workloads that mix insert and erase, tombstones can accumulate. Accumulated tombstones act like a high load factor from the performance perspective and a low load factor for memory utilization, which is the worst of both worlds.
F14 uses a novel strategy that acts like something similar to reference-counted tombstones. It’s based on an auxiliary bit for each slot suggested by Amble and Knuth in their 1974 article “Ordered hash tables.” The bit was set whenever their insertion routine probed past a slot that was already full; the bit records that a slot has overflowed. A tombstone roughly corresponds to an empty slot with the overflow bit set. The overflow bit makes searches faster, because the search for a key can be stopped at a full slot whose overflow bit is clear, even if the following slot is not empty.
Our extension to the overflow bit idea is to count the number of active overflows. This is possible because even though they accomplish the same purpose as a tombstone, overflow bits have a different life cycle. They are set when a displaced key is inserted rather than when the key that did the displacing is removed. It’s not practical to figure out how many keys are relying on a tombstone when it is created, but it’s easy to keep track of the number of keys relying on an overflow bit. Each F14 chunk uses 1 byte of metadata to count the number of keys that wanted to be placed in the chunk but are currently stored in a different chunk. When a key is erased, it decrements the overflow counter on all the chunks that are on its probe sequence, cleaning them up. This fits with our goal of making F14 work well in a wide variety of scenarios: Long-lived maps/sets with continual insert and erase work fine. Overflow counts also speed up F14 tables that don’t call erase; they shorten probe lengths and reduce the chance that copy construction must perform a rehash.
Optimizing memory with multiple layouts
Reducing memory waste is directly useful. It also aids performance by allowing more of a program’s data to fit in cache, which can speed up both the hash table and the surrounding code. Two common strategies for hash table memory layouts are indirect (typically with a pointer stored in the main array) and direct (with the memory of the keys and values incorporated directly into the main hash array). Direct storage algorithms must use probing for conflict resolution unless they store additional metadata. F14 exposes pointer-indirect (F14Node) and direct storage (F14Value) versions, as well as the less common index-indirect (F14Vector).
We can examine the trade-offs of different layouts by separating memory usage into categories. Let’s refer to space for keys and values as data, and space for everything else as metadata. Data space is proportional to the size of the keys and values; metadata space is independent of the key and value types. Categories of memory use:
- Useful data space: The number of bytes that actually hold the entries inserted by the user. There’s no generic way to reduce this component.
- Data space unusable because of the maximum load factor: Conflict resolution with probing becomes inefficient if the main array fills up, so the table must rehash before that happens. For example, a maximum load factor of 0.5 is common for probing, which means no more than half the indexes can be filled before rehashing occurs. Therefore, space for data in the unused indexes is wasted. In the 0.5 load factor case, we can say that for every byte of useful data, there is one byte of waste due to the load factor, or a 100 percent overhead. This is greatly improved with F14Value, which generally uses a max load factor of 12/14.
- Data space unused because of bulk allocation: While pointer-indirect hash tables can allocate data space one key at a time during
insert, those with direct or index-indirect memory layouts bulk-allocate data space during a rehash. While bulk allocation is more CPU efficient, it’s possible that not all the space will end up being used. The most common rehashing strategy is to double the capacity during rehash so that, in the worst case, allocating in bulk results in only half of the usable data space actually being used. If an algorithm doesn’t limit itself to power-of-two table sizes, this overhead can be avoided when the caller usesreserve, but that is not compatible with the common performance optimization of using bitwise-and to evenly distribute hash codes across indexes. - Metadata per table: Hash table data structures have some fundamental overhead, typically at least a pointer and a couple of integers. This category is important for use cases that have many empty or small tables, such as for the hash table inside
folly::dynamic. We have carefully engineered F14 hash tables so that there is no dynamic allocation for empty tables and the C++ type itself is small: only 24 bytes (F14Vector) or 32 bytes (F14Value and F14Node) on 64-bit platforms. - Metadata per
insert: Indirect storage with chaining for conflict resolution must allocate some bytes for the chaining pointer. - Metadata per
rehash: This category includes the bytes allocated during rehash not set aside for future storage of data values, such as the pointers in the main array for a chaining hash table or the secondary hashes used by F14.
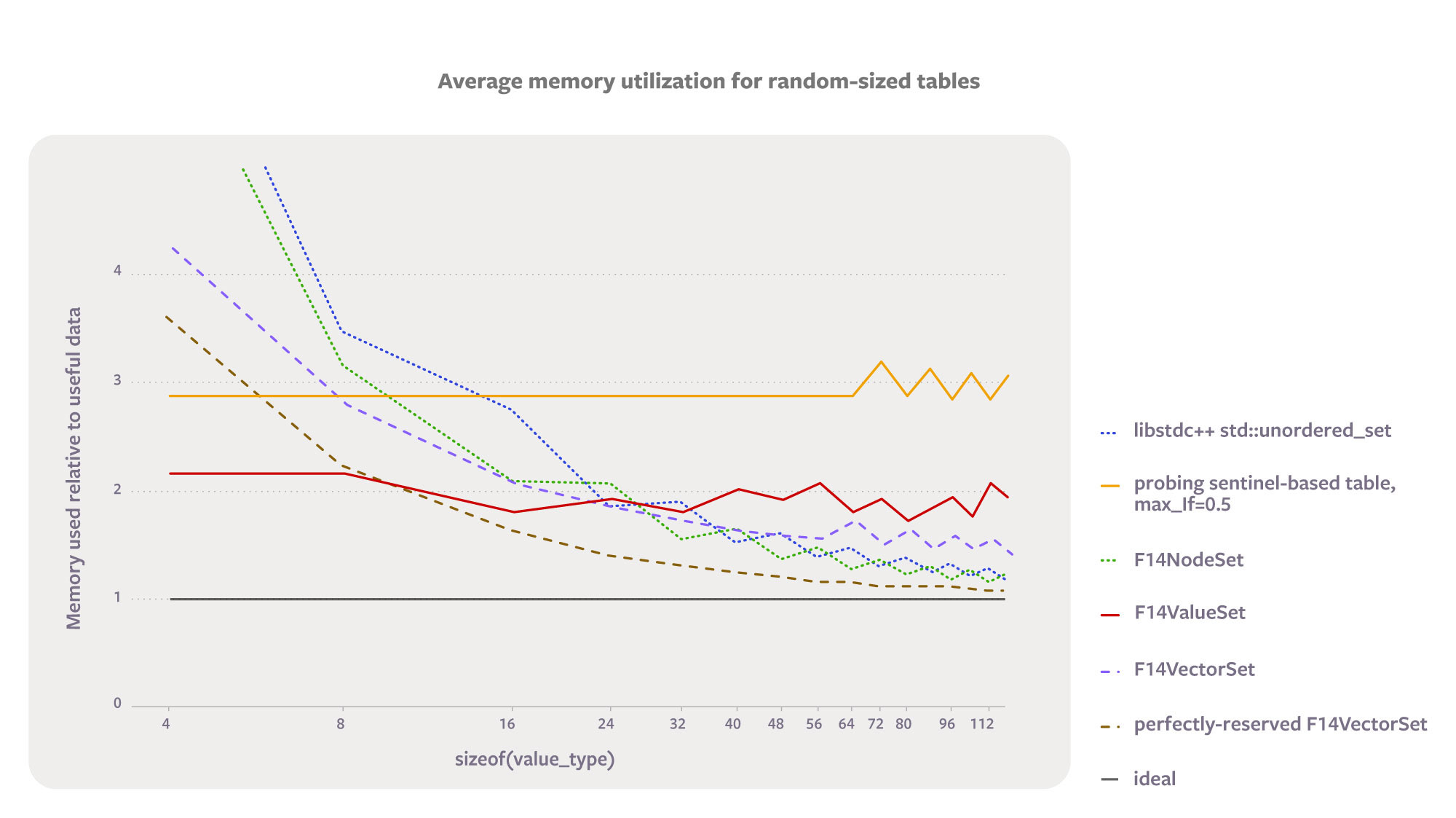
Below are the overheads for hash sets holding 8-byte integers. The probing sentinel-based table here is similar to dense_hash_set but has a minimum capacity of two and doesn’t allocate at all for empty tables.
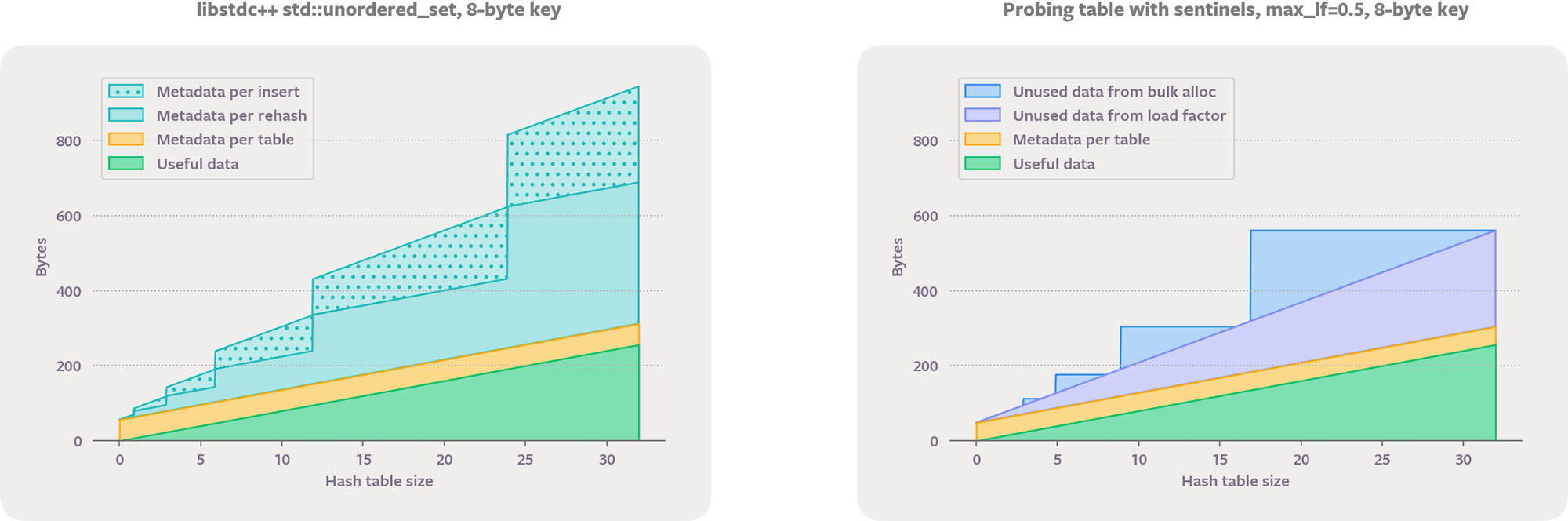
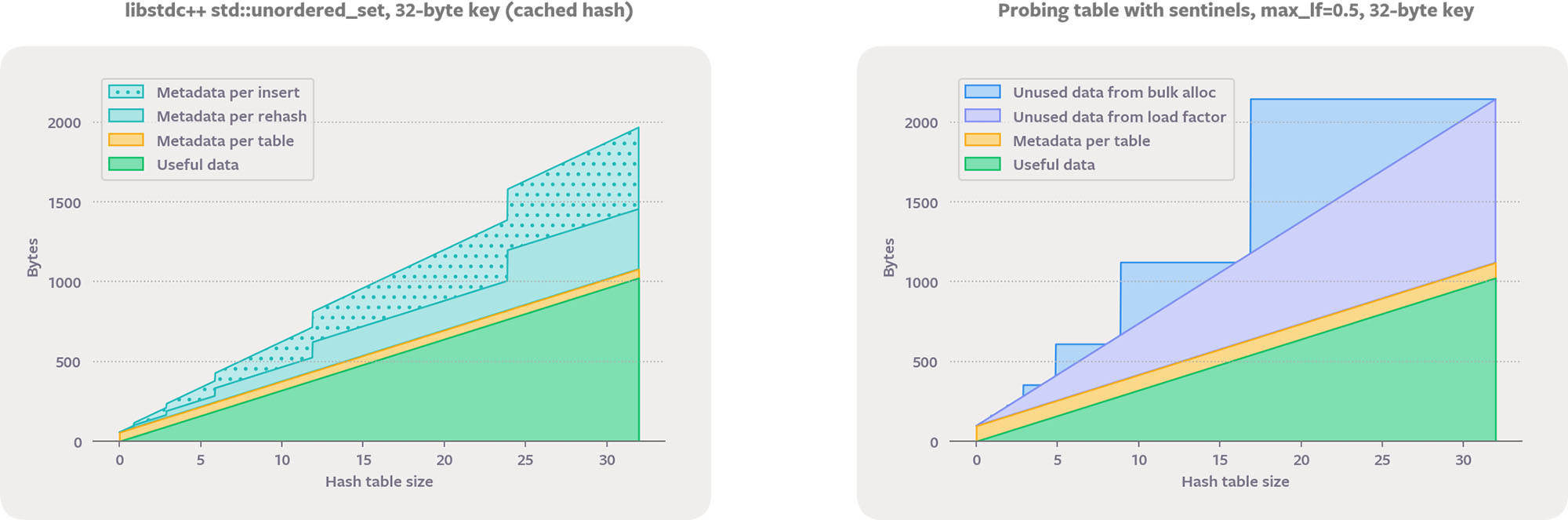
The STL container std::unordered_set never wastes any data space, because it waits until the last moment to allocate nodes. On the other hand, for small elements like these, the metadata overhead is quite high. Each data item is the same size as a pointer, so the metadata ranges from 2x to 3x the size of the data. Despite having a smaller maximum load factor, a probing table that uses sentinels ends up using less overall memory because its data space waste is smaller than the metadata waste of std::unordered_set.
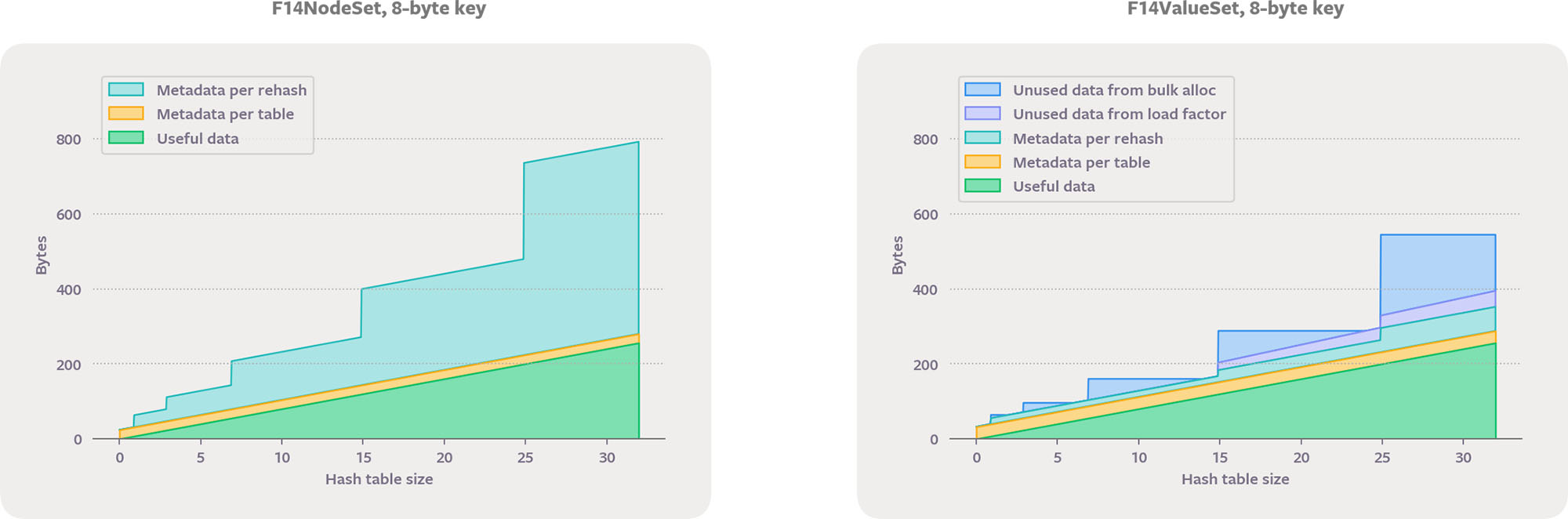
F14NodeSet performs a separate memory allocation for every value, like std::unordered_set. It stores pointers to the values in chunks but uses F14’s probing collision resolution so there are no chaining pointers and no per-insert metadata. F14ValueSet stores the values inline, like a probing sentinel-based table. It has the same data waste from early allocation, which is intrinsic to inline storage, but has much less data waste due to using a higher maximum load factor. F14ValueSet achieves this memory-efficiency win while also avoiding the need for sentinels.
F14Node and F14Value typically use a maximum load factor of 12/14, so they rehash when growing beyond sizes of 12*2^k (like 24 in the above plots). However, if you look closely, you’ll see that rather than rehashing after 12, they rehash after 14. Filtering works fine even in a completely full chunk, so we are careful to use a maximum load factor of 100 percent when there is only one chunk. In fact, the filtering step means that we can support every capacity from 0 to 14 without any special cases in the lookup or insertion logic. If reserve is not called, the initial rehashes occur after sizes 2 and 6. If an initial capacity is available, we can be even more memory-efficient for small tables.
The relative space overhead of metadata is reduced for bigger values. Here are the same four graphs when storing std::string. Note that the per-insert metadata is larger for this case because std::unordered_set chooses to cache the hash values in the nodes.
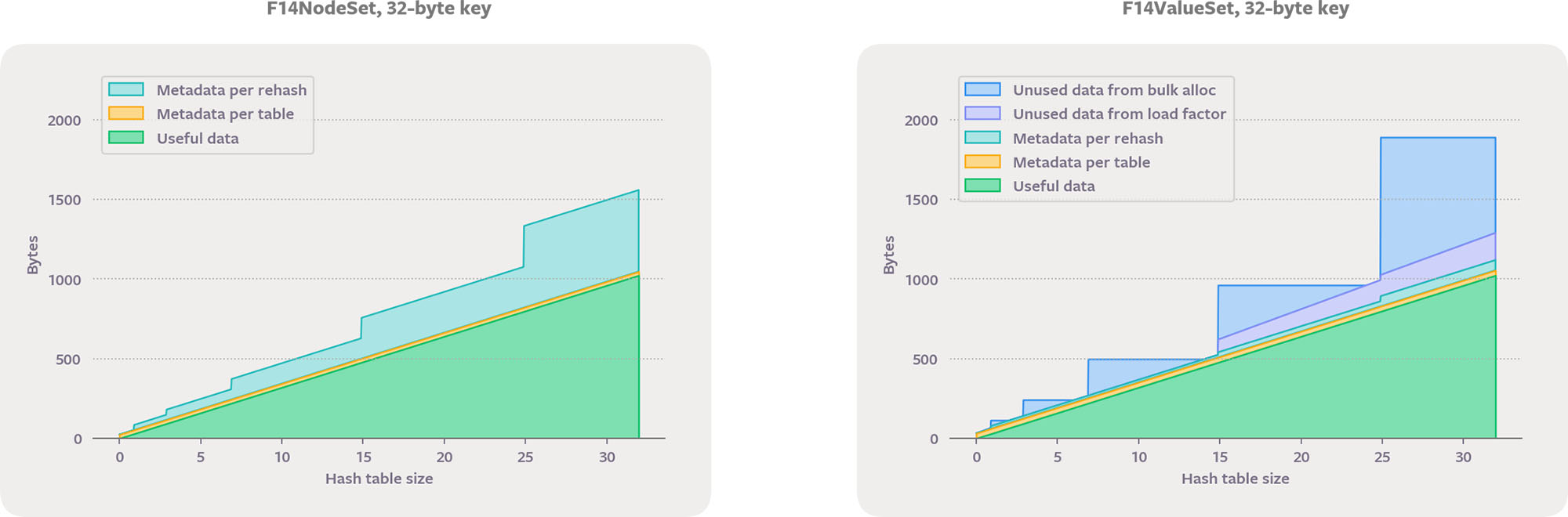
F14 also provides an array-indirect memory policy. F14Vector stores values in a densely packed vector with a 4-byte index in the main hash array. When a key is removed, the last vector element is moved into its place and the corresponding index entry is adjusted. F14Vector provides very fast iteration and destruction. For large values it is also more memory-efficient than F14Value, because the data vector can be sized to have no load factor waste. When the final size is known in advance, we get further savings by sizing the data vector and chunk array independently. This lets us keep the number of chunks a power of two, which is important for lookup performance, while entirely eliminating data waste.
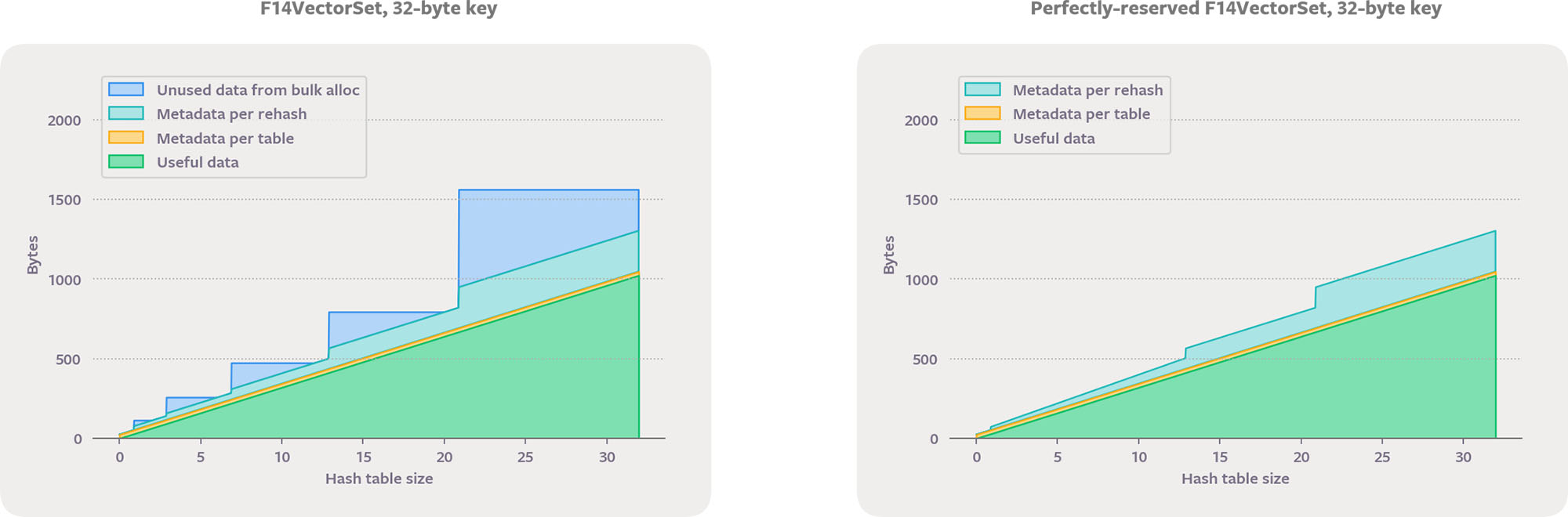
F14VectorSet could actually be more accurately called F12VectorSet — we use chunks of 12 to store the 4-byte indexes so that a chunk fits perfectly in a cache line, and we use a maximum load factor of 10/12.
F14Fast: A hybrid memory policy
The graphs let us compare the memory efficiency at a particular size, but what about general conclusions? For 32-byte keys, F14ValueSet uses less memory to hold 24 keys than F14VectorSet, but is it more efficient on average? Benford’s law lets us compute the answer. Hash table sizes in production seem to follow Benford’s law across a range of sizes, which implies that the probability of finding a table with a particular load factor f is proportional to 1/f. This lets us weight the memory overheads independent of the exact rehash points.
The following plot shows the average memory efficiency as a function of the size of the entries. Load factors are weighted using Benford’s law. The lines are not smooth because they also take into account the memory wasted because of the spacing between jemalloc’s default allocation classes. These microtable benchmarks have code to compute this graph.
Both F14Vector and F14Value provide excellent performance. Since our goal is to make a good default, we decided to splice them together into a hybrid storage policy, called F14Fast. This strategy acts like F14Vector whenever value_type is 24 bytes or larger; otherwise, it acts like F14Value. The folly::F14FastMap and folly::F14FastSet types are by far the most commonly used across our codebase.
Testability
When converting existing code to F14, we encountered both unit test failures and production crashes. A majority of these were tests that hard-coded a specific iteration order, or code that implicitly relied on the specific behavior of a hash table implementation. For example, iterators work fine after a rehash in libstdc++’s std::unordered_map, even though it is undefined behavior in the standard.
To make sure code doesn’t take implicit dependencies on F14’s iteration order, we randomize it for debug builds. In this mode, F14 randomly chooses among all the empty slots in a chunk when inserting a new key. Entry order isn’t completely randomized, but the shuffle is good enough to catch a regressing test with only a few runs.
F14 also has ASAN integration that can probabilistically detect reference and iterator stability issues. In this mode, all the non-node memory is reallocated with probability 1/size on each insert. This catches code fragments such as:
F14FastMap<.., ..> m;
auto& v1 = m[k1];
m[k2] = foo(v1); // m might rehash before calling foo!One way to fix this pattern is to use reserve:
m.reserve(m.size() + 2); // space for k1 + k2 to be added
auto& v1 = m[k1];
m[k2] = foo(v1);When there is a call to m.reserve(m.size() + d), spurious reallocations will be disabled for the next d insertions that happen on that thread. So far, this simple heuristic has been sufficient to avoid any false positives.
C++ optimizations
The best way to speed up code is to run less of it. F14 reduces the need for object construction and copies both inside the hash table and in the surrounding code:
1. Heterogeneous lookups and mutations: Facebook code often uses string views (folly::StringPiece and std::string_view) to boost the performance of code that processes text. These classes don’t manage memory themselves, so they are not a good key type for a hash table. It is common, however, to want to use a std::string_view to search in a hash table with std::string keys. By using a hash function that can hash both std::string_view and std::string, F14 avoids the need to copy the content of the string in this case, allowing the calling code to do a lot less work. C++20 will let you opt in to this type of heterogeneous lookup for read-only APIs, such as find. F14 has heterogeneous lookup for both the read and write APIs wherever it makes sense. operator[] is especially important; its convenient syntax means it is heavily used to find existing keys. We’ve also made heterogeneous lookup the default for all stringlike key types.
2. Destructuring for insert and emplace arguments: The operator[] API and the newer unordered map APIs try_emplace and insert_or_assign pass the search key as a separate argument, making it easy to check the hash table for an existing entry without doing the work of constructing the std::pair entry. emplace is trickier because its arguments are forwarded through to one of std::pair‘s eight constructors. The F14 maps are careful to match against all of those forms internally; if they find that a single parameter will be used to initialize the first element of the pair, then it can be used directly for the initial search. This is especially powerful when combined with heterogeneous lookup. F14’s map insert method just forwards to emplace, relying on destructuring to extract the key.
3. const field key workaround: Constant fields can’t be used as the source of a move constructor. This is unfortunate, because std::unordered_map (and std::map) hold std::pair<K const, T>. It’s not a big issue for node-based containers, since they never need to move an entry, but a hash table with direct storage must make a hard decision. There are four options: copy all the keys during every rehash, hand out mutable references to a std::pair<K,T>, hand out a proxy class, or rely on undefined C++ behavior. Those options are slow, risky (clients can change the key), incompatible (maybe we can try again after proxy iterators work), and ugly, respectively. After careful deliberation, we chose ugly, using const_cast to make the key mutable just prior to its destruction during rehash.
4. [[deprecated]] warning instead of std::move_if_noexcept: Each time we tried to put a type that is not noexcept movable into an F14FastMap or F14FastSet, the missing noexcept annotation was a mistake rather than an attempt to use copying to get the strong exception guarantee. On the other hand, forcing users to modify their code before trying F14 would put up barriers to adoption and experimentation. As a compromise, we always move keys and values, but if those constructors are not marked noexcept, then we trigger noisy deprecation warnings.
5. Allowlisting trusted hashers: Some hash functions distribute information evenly across all their bits — any change to the input causes an avalanche of changes to the hash code. Ideally, any one-bit change in the input is expected to change about half the bits of the output. These hash functions can be mapped onto a power-of-two range by just zeroing the top bits. For example, we might map hash codes across 32 chunks by zeroing all but the bottom five bits.
At the other end of the spectrum are hash functions like std::hash for integral types, which is often the identity function. It meets the C++ standard’s requirements for hash quality (hash codes are very unlikely to be equal unless the inputs are also equal), but it doesn’t spread information at all. If we just took the bottom five bits, for example, then we would experience a large number of collisions if all the integer keys were multiples of 32. If the hash function doesn’t distribute information, then F14 must postprocess the hash code with a bit mixer.
The bit mixer adds only a few cycles of latency, but it is still worth optimizing because hash tables are used at the core of some very hot loops. Folly has an extensible compile-time allowlisting mechanism that can be used to bypass the mixer, such as for std::hash<std::string>. The allowlist can also be used to disable the mixer when the keys are known to be uniformly distributed.
Folly’s F14 is widely used inside Facebook. F14 works well because its core algorithm leverages vector instructions to increase the load factor while reducing collisions, because it supports multiple memory layouts for different scenarios, and because we have paid attention to C++ overheads near the API. F14 is a good default choice — it delivers CPU and RAM efficiency that is robust across a wide variety of use cases.
In an effort to be more inclusive in our language, we have edited this post to replace “whitelist” with “allowlist.”








