
An integral part of Facebook’s engineering culture has always been our development work on open source solutions that solve real-world production issues and address key challenges in modern large-scale cloud computing. Today, we are announcing a suite of open source Linux kernel components and related tools that address critical fleet management issues. These include resource control, resource utilization, workload isolation, load balancing, measuring, monitoring, and much more.
Kernel and kernel application developers at Facebook partner with various internal teams to develop technologies that resolve issues and concerns in Facebook’s data centers — the same challenges that many throughout the industry share. The following products are now in production on a massive scale throughout all of Facebook’s infrastructure, as well as at many other organizations.
BPF
BPF is a highly flexible, efficient code execution engine in the Linux kernel that allows bytecode to run at various hook points, enabling safe and easy modifications of kernel behaviors with custom code. Although it’s been widely used for packet filtering, BPF’s instruction set is generic and flexible enough to support and allow for a wide variety of use cases beyond networking such as tracing and security (e.g., sandboxing).
At Facebook, ensuring fast, reliable access for our users is a top priority. To achieve this goal, our infrastructure engineers have developed traffic optimization systems in which BPF plays a prominent role. One such case is Katran, a software-based load-balancing solution with a completely reengineered forwarding plane that takes advantage of the BPF virtual machine. The Katran forwarding plane software library powers the network load balancer used in Facebook’s infrastructure and has helped improve the performance and scalability of network load balancing while drastically reducing inefficiencies.
Btrfs
Btrfs is a next-generation file system built with today’s data centers in mind. It is a copy-on-write (CoW) filesystem focused on advanced feature implementation, fault tolerance, repair, and easy administration. Btrfs is designed to address and manage large storage subsystems and supports features such as snapshots, online defragmentation, pooling, and integrated multiple device support.
Btrfs has played a role in increasing efficiency and resource utilization in Facebook’s data centers in a number of different applications. Recently, Btrfs helped eliminate priority inversions caused by the journaling behavior of the previous filesystem, when used for I/O control with cgroup2 (described below). Btrfs is the only filesystem implementation that currently works with resource isolation, and it’s now deployed on millions of servers, driving significant efficiency gains.
Netconsd
Netconsd is a UDP-based netconsole daemon that provides lightweight transport for Linux netconsole messages. It receives and processes log data from the Linux kernel and serves it up as structured data in a way that helps production engineers rapidly identify issues in the fleet.
At Facebook, netconsd provides vital data center statistics. It logs data continuously from millions of hosts and allows engineers to extract meaningful signals from the voluminous log data noise generated in the kernel, helping on-call production engineers rapidly identify and diagnose misbehaving services.
Cgroup2
Cgroup2 is the next-gen Linux kernel mechanism for grouping and structuring workloads, and controlling the amount of system resources assigned to each group. It has controllers for memory, I/O, central processing unit, and more. It also allows you to isolate workloads and prioritize and configure the distribution of resources for each one.
Resource control using cgroup2 is driving multi-tenancy improvements in Facebook’s data centers through better handling of memory overcommit and strategies such as load shedding when memory becomes scarce. It is improving resource utilization in Facebook’s fleet by isolating and protecting a system’s main workload from widely distributed system binaries and other system services that run on Facebook hosts.
The resources reserved for these system binaries were nicknamed the fbtax, which later became the name of the project to fix priority inversions and other resource distribution issues in Facebook’s fleet. The fbtax project demonstrated the possibility of comprehensive resource isolation while using operating system features such as memory management and file systems, opening the door to increased fleet efficiency by making workload stacking straightforward and safe. Check out the fbtax2 case study in the cgroup2 documentation for details.
PSI
Pressure Stall Information (PSI) provides for the first time a canonical way to quantify resource shortages with new pressure metrics for three major resources: memory, CPU, and I/O. These pressure metrics, in conjunction with other kernel and userspace tools that are part of this open source release, allow detection of resource shortages while they’re developing and responding intelligently. PSI stats provide early warning of impending resource shortages, enabling more proactive, granular, and nuanced responses.
We use PSI at Facebook in conjunction with cgroup2 to provide per-cgroup insight into resource use (and misuse) of a wide variety of different workloads, enabling increased utilization and reliability in situations in which resources are insufficient.
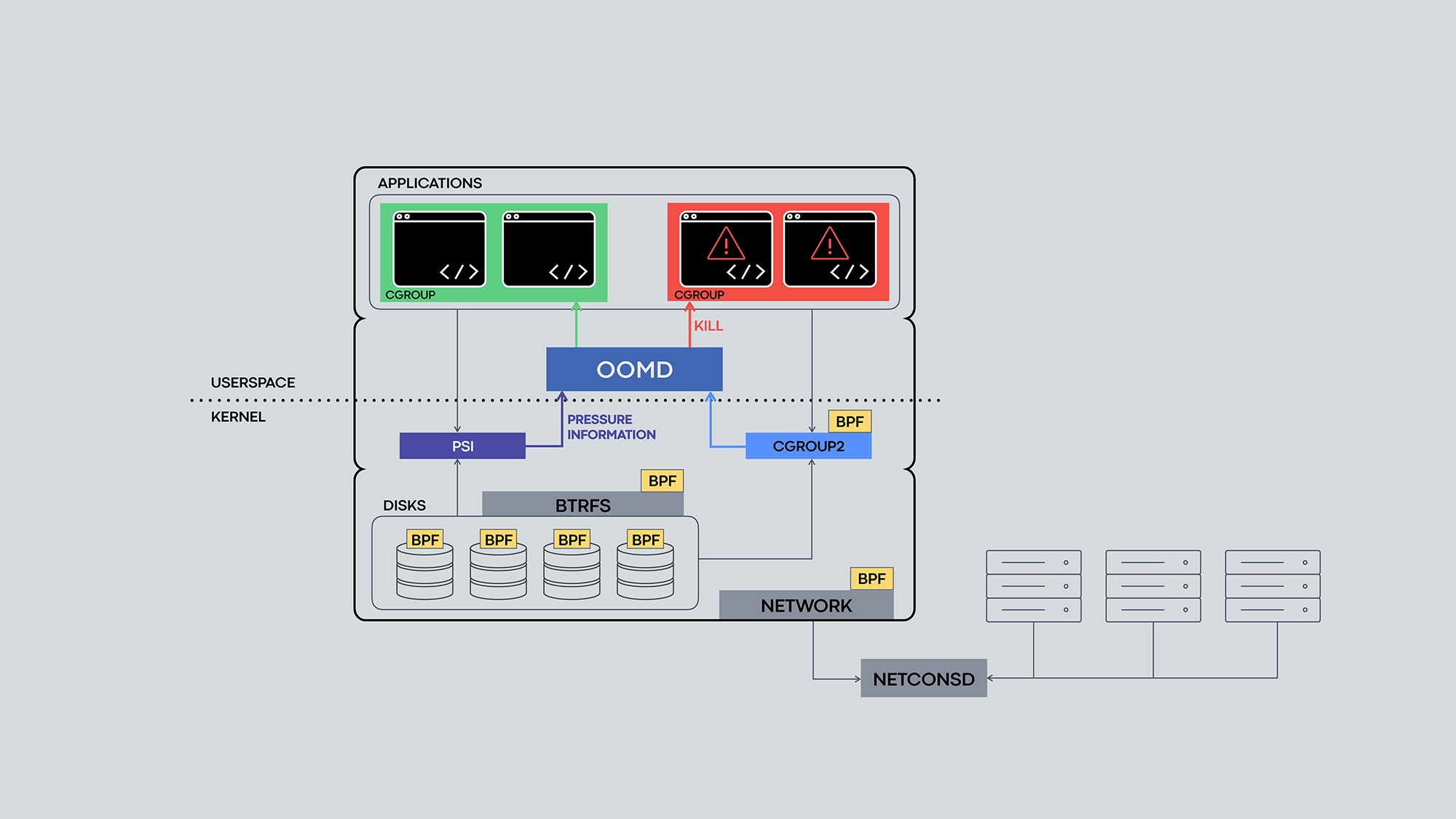
Visual showing how the various components and tools work together.
Oomd
Oomd is a userspace OOM (out-of-memory) process killer that acts with greater awareness of the context and priority of processes running on a system. It allows you to configure responses to OOM conditions, such as pausing or killing nonessentials, reallocating memory in the system, or other actions.
OOM killing traditionally happens inside the kernel. If a system runs out of physical memory, the Linux kernel is forced to OOM-kill one or more processes. This action is typically slow and painful because the kernel triggers only when the kernel itself can’t make forward progress: It lacks any way of knowing an application’s health, often resulting in thrashing behavior, in which the kernel thinks conditions are OK, but applications are suffering. On top of this behavior, configuring policy is complicated and inflexible. Oomd solves these problems in userspace by taking corrective action before an OOM occurs in kernel. A flexible plugin system that supports custom detection logic configures these actions. Oomd allows you to write custom protection rules for each workload.
In Facebook’s data centers, Oomd, in conjunction with PSI metrics and cgroup2, is increasing reliability and efficiency, driving large-capacity gains and significant increases in resource utilization.
Limitless possibilities
The use cases described here are just the beginning. The kernel components and tools included in this release can be adapted to solve a virtually limitless number of production problems. Facebook continues to develop and deploy solutions using these tools. We believe that this collection of services and products will be helpful for any developer building apps to serve millions of users on multiple platforms.
We are excited to release these solutions to the open source community and hope they will empower others to address similar production issues and develop innovative uses.








