
With thousands of engineers working across a range of products at Facebook, we face some unique challenges when it comes to code quality.
Not only are we dealing with a large codebase, but things are also moving fast — new features are being added, existing ones are being improved, and things are being reorganized.
For CSS, this means having thousands of files that are in a continuous state of flux.
While we already try to ensure CSS code quality on different levels — through code reviews, style guidelines, and refactoring — unintentional mistakes can also be eliminated with static analysis before they’re even committed.
Until recently, we used a homegrown CSS linter to catch basic errors and ensure consistent style. While it served its purpose well over the years, we wanted a more robust solution.
Regex is not enough
The old linter was essentially a number of regex search-and-replace rules. Properly parsing CSS is not a trivial problem, and accounting for custom vendor extensions and specification changes is even more challenging.
Here’s an example of what old code might have looked like:
preg_match_all(
// This pattern matches [attr] selectors with no preceding selector.
'/\/\*.*?\*\/|\{[^}]*\}|\s(\[[^\]]+\])/s',
$data,
$matches,
PREG_SET_ORDER | PREG_OFFSET_CAPTURE);
foreach ($matches as $match) {
if (isset($match[1])) {
raiseError(...);
}
Maintaining rules with these kind of cryptic matchers is no fun. It was difficult to change and to understand. It was also a performance issue. For each rule, we had to iterate over the entire input again and again, matching various regular expressions.
Abstract Syntax Tree
We decided the new solution would be based on a real, spec-compliant CSS parser. Since the code would have to be syntactically valid for this type of parser to work, we could no longer treat our entire CSS codebase as a giant blob of text. This new approach would be a significant improvement in CSS code quality by catching typos that would have otherwise gone unnoticed and resulted in silently incorrect rendering or behavior.
What kind of behavior?
Some of the bits lurking in the shadows of our large codebase might have been things like:
{
display: none:
background-color: #8B1D3;
padding: 10px,10px,0,0;
opacity: 1.0f;
}
Can you spot the subtle differences? Typo in a property name, incorrect hex, wrong separators — browsers simply ignore all of these, which is far from the original developers’ intent.
It didn’t take long to realize that PostCSS would be a great tool for the job — a proper, standard-based CSS parser with an excellent modular architecture. We then selected Stylelint as our CSS linter. It’s powered by PostCSS, just as flexible, and well-supported.
Similar to JavaScript-based parsers/linters like Esprima and ESLint, PostCSS and Stylelint give you access to the entire AST (Abstract Syntax Tree). AST makes it easy to access any nodes with any conditions: Are we using the right class names? Are we including correct abstractions? Are there any deprecated or non-supported extensions? Are there localization issues?
In this example, we’re iterating over all declarations and finding any “text-transform: uppercase” pairs:
root.walkDecls(node => {
if (node.prop === 'text-transform' && node.value === 'uppercase') {
report({
...
});
}
});
We can even parse and deconstruct lower-level “functions” like linear-gradient. Here’s a more involved example that finds the linear-gradient “function” and checks its first argument:
// disallow things like linear-gradient(top, blue, green) w. incorrect first valueroot.walkDecls(node => {
const parsedValue = styleParser(node.value);
parsedValue.walk(valueNode => {
if (valueNode.type === 'function' && valueNode.value === 'linear-gradient') {
const firstValueInGradient = styleParser.stringify(valueNode.nodes[0]);
if (disallowedFirstValuesInGradient.indexOf(firstValueInGradient) > -1) {
report({
...
});
}
}
});
});
The code is relatively easy to understand and update. And all this will work no matter the formatting of CSS, and no matter where the rules and declarations are located (e.g., top level, inside media blocks, inside keyframe blocks).
It felt good to see the prowess of PostCSS and Stylelint crunching through our files. The two caught things like the typos mentioned earlier, values inside linear-gradients or keyframes, things like “! important” (which is apparently treated the same as “!important”), complex selectors, non-standard properties, and many more potential issues.
Custom rules
We were able to use a few of the existing Stylelint rules, such as declaration-no-important, selector-no-universal, and selector-class-pattern.
The custom rules were ported via a convenient built-in plugin mechanism. Some of what we have are:
- slow-css-properties to warn against performance-sensitive properties like opacity or box-shadow (just to be mindful of them)
- filters-with-svg-files to warn against filters not being supported in Edge when referencing SVG files
- use-variables to warn against values that could be replaced with existing constants (we use custom
var(...)abstraction) - common-properties-allowlist to catch potentially nonexistent properties (i.e., typos)
- mobile-flexbox to catch multi-value flex that’s not supported in older mobile browsers
- text-transform-uppercase to warn against “text-transform: uppercase” (which is not internationalization-friendly)
We’ve also contributed some rules and additions back to Stylelint and are planning to eventually release all of them, either in a stand-alone repository or directly to Stylelint’s existing lineup.
Automatic replacement
One important aspect of our linting process is auto-formatting. Linter has support for patching, and if something doesn’t conform, it asks if you’d like things replaced according to the rule. This can be a powerful and time-saving concept. The last thing you want to do during a commit is to see lint errors, and then go back and fix all of them, across multiple files, especially if it’s something as mundane as alphabetic rule reordering. It’s usually better to let an auto-formatter do its job and save developers time.
Unfortunately, Stylelint doesn’t have built-in auto-formatting (and, arguably, a linter shouldn’t be concerned with such a task), so we had to reimplement a few of the existing Stylelint rules to add support for replacement via our existing infrastructure. Meanwhile, we’re discussing potential generic changes to Stylelint to make this easier for all users in the future.
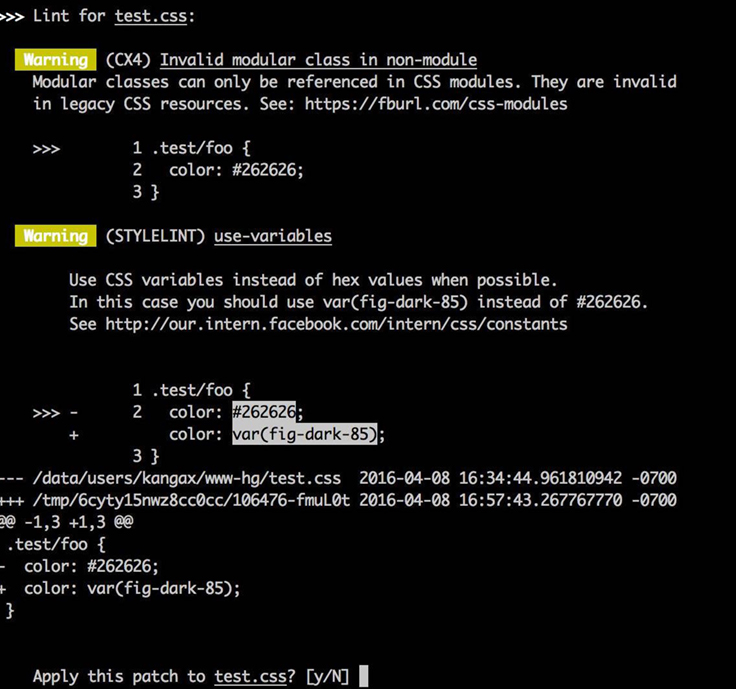
Test all the things
One of the problems with our old linter was that we had no unit tests. This is concerning, since we’re dealing with something that parses almost arbitrary text. When rewriting our linter to use Stylelint, we added tests for each single rule, ensuring that the rule catches the right things, ignores irrelevant things, and suggests the right replacements.
We used a trusted Jest framework (and worked with Stylelint to add better support for it ) and now have a nice set of easy-to-understand tests like this:
test.ok('div { background-image: linear-gradient( 0deg, blue, green 40%, red ); }',
'linear gradient with valid syntax');
test.notOk('a { background: linear-gradient(top, blue, green); }',
message,
'linear-gradient with invalid syntax');
What’s next
This rewrite is only a first step toward higher-quality CSS. There are a number of useful rules we’re planning to add (both built-in and custom ones) — all of them aimed to catch common errors, enforce best practices, and control code style conventions. We already do this with JavaScript (via ESLint) so there’s no reason we shouldn’t be able to do it with CSS.
The linter is already integrated with Phabricator, our code collaboration tool. The warnings/advice are shown right in the revision.
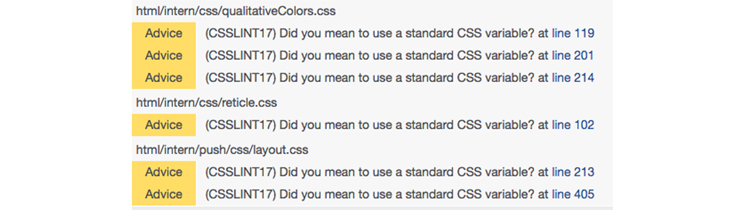
This makes the linting process an important step in the collaborate-and-commit workflow.
Another great thing about having a proper CSS parser is that it’s possible to gather accurate statistics about the codebase. What are the least used properties/values? Perhaps they should be removed or replaced (sending fewer bytes over the wire). What are the most prevalent colors/font sizes/z-indexes? Perhaps they should be abstracted into reusable components and/or variables. What are the “heaviest” selectors? Perhaps there’s a performance issue.
All of these could help improve both performance and maintenance.
What about React and inline styles?
It’s worth mentioning the CSS-in-JS concept that’s been gaining traction in the React community lately. As it stands now, a CSS linter is largely irrelevant in cases when CSS is defined in this less traditional approach. The linter is currently aimed at parsing traditional CSS files but could later be adapted to parse rules and declarations defined as objects in JS. PostCSS has a native JS API, so this should be fairly straightforward.
While we are currently exploring the CSS-in-JS approach at Facebook, it’s still in its early experimental days, and we still have a large CSS codebase to maintain. Meanwhile, the linter serves its purpose.
Working together
We’re excited to use open source tools and contribute back as much as we can. Hopefully, this will provide a solid set of modern rules and guidelines for everyone to use and collaborate on.
Thank you to the JS infra and webspeed teams, and any others who helped with the rewrite; David Clark and Richard Hallows of Stylelint, who were extremely helpful and responsive; as well as the entire community that made such fantastic tool as PostCSS possible.
This is truly a collaborative effort.
In an effort to be more inclusive in our language, we have edited this post to replace “whitelist” with “allowlist.”








