Here at Facebook, the HipHop team constantly strives to improve the efficiency of PHP execution and increase productivity for our PHP developers. In late 2011 we announced that we were pursuing a just-in-time (JIT) compilation approach called HipHop VM (HHVM) as a successor to the HipHop PHP-to-C++ compiler (HPHPc). The goals of the HHVM project are two-fold: build a production-ready virtual machine that delivers superior performance, and unify our production and development environments.
Below is an update on the state of HHVM, followed by a deep dive into some details on HHVM’s architecture and optimization strategies.
Performance
This year we pushed to make HHVM as efficient as HPHPc for our massive PHP code base. HPHPc was a tough act to follow: a lot of effort had been put into optimizing its performance, and it delivered significant efficiency gains over the years. Matching HPHPc’s performance was a difficult requirement we had to satisfy before HHVM could be used to serve production traffic at scale.
We are happy to announce that HHVM is now as fast as HPHPc. HHVM’s dynamic translation technique (aka the JIT) and an extremely motivated team were key to winning the race. The chart below shows the efficiency of HHVM relative to HPHPc over the past 7 months for generating the home page for www.facebook.com:
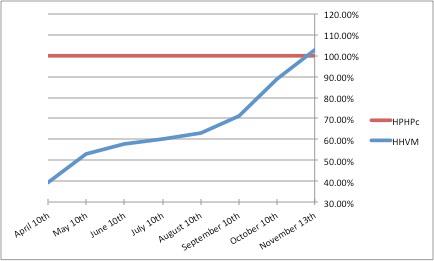
With HHVM’s performance overtaking HPHPc and continuing on an upward trajectory, the HipHop team is gearing up to migrate our production machines from HPHPc to HHVM.
The development environment
Prior to HHVM, our development environments (we call them “sandboxes”) used a custom-built PHP interpreter called HPHPi to shortcut the long and slow HPHPc compilation cycle and provide a rapid “edit, save, run” development workflow. HPHPi was flexible but slow (slower than the Zend engine that HPHPc replaced). Developers around here like to move fast, and we were starting to see HPHPi strain under the load of more complex product features like Timeline and Ticker.

We deployed HHVM to our sandboxes in 2011 and reduced page load times by over 3x compared to HPHPi, all while keeping the rapid workflow that HPHPi provided. When HHVM is fully deployed to production, we will have achieved our goal of unifying our production and development environments. Not only will this enable our PHP developers to debug, tune, and iterate with the same system we run in production, but it also will allow the HipHop team to focus on improving a single system that benefits both environments simultaneously.
Open source
Sharing the benefits of our PHP development stack with the community is important. We rebooted our open source effort in July and have resumed regularly updating our public github repository. We’ve targeted Ubuntu Precise 12.04 x64 and CentOS 6.3 x64 to start, and we’re planning to add support for more x64 platforms (including Mac OS X) in the future.
While efficiency for our Facebook code base is our priority right now, we’ve started investing in making sure we’re able to correctly run popular PHP code bases. HHVM runs the latest version of WordPress (see “Getting WordPress running on HHVM”) and we’re proudly using it to serve our new team blog. By making sure HHVM is able to run common PHP applications and frameworks, we’re hoping to make it more useful to the broader PHP community outside of Facebook. And given that HHVM supports a development and deployment workflow similar to the Zend PHP stack, we think HHVM is an important step forward in reducing friction for adoption.
Improving the JIT
While working to make the JIT more efficient, we faced some interesting challenges. Traditional profiling and optimization techniques aren’t always sufficient for improving a complex software system such as a virtual machine. Finding gains was hard work that required doing a lot of experiments (many of which did not produce positive results), and at times the results were surprising and frustrating.
Here are a few of the things we did in 2012 to improve the JIT:
Instruction set coverage
HHVM runs PHP programs by converting the PHP source into HipHop bytecode (HHBC) and executing the bytecode using both a bytecode interpreter and an x64 JIT compiler that seamlessly interoperate with each other. The JIT is used where possible, and the interpreter is used as an execution engine of last resort. By the end of 2011 the JIT supported most of the common bytecode instructions and input types, but there was a long tail of less common instructions and types that caused the JIT to transfer control to the interpreter. This long tail was limiting HHVM’s performance.
During 2012 we added JIT support for many of the less common instructions and input types. Most notably, we implemented full JIT support for all the member instructions (instructions for accessing array elements and object properties). PHP’s semantics for element access and property access are complex, and the design of the member instructions reflects that complexity. PHP’s evaluation order for expressions involving a chain of element or property accesses does not fit nicely into HHBC’s stack model, so the member instructions were crafted so that a chain of element accesses and property accesses can be executed by a single member instruction. Furthermore, the behavior of element and property expressions depends on context, so HHBC has several different member instructions to accommodate different contexts. For example, the statement “$x[f()][g()] = $y[j()][k()];” is converted into bytecode like so:
0: FPushFuncD 0 "f"
6: FCall 0
8: UnboxR
9: FPushFuncD 0 "g"
15: FCall 0
17: UnboxR
18: FPushFuncD 0 "j"
24: FCall 0
26: UnboxR
27: FPushFuncD 0 "k"
33: FCall 0
35: UnboxR
36: CGetM
49: SetM
62: PopC
The first 12 instructions evaluate the expressions f(), g(), j(), and k(). The CGetM instruction at offset 36 performs the element accesses on the right-hand side, and the SetM instruction at offset 49 performs the element accesses on the left-hand side. The SetM instruction then performs the assignment.
Since HHBC has 10 different member instructions and each one can encode arbitrarily long chains of element and property accesses, adding full JIT support for these instructions essentially required writing a “mini-translator” that could handle any combination of element and property access in any context. Each member instruction is broken up into a series of simpler operations, and then x64 machine code is generated for each operation, passing the intermediate result of one operation to the next.
All told, implementing full JIT support for the member instructions reduced CPU time by more than 13%, and there is still room for further optimization in this area.
Side exits
HHVM’s JIT uses a trace-based form of compilation that limits each trace to a single basic block where the input types are known at translation time (the “tracelet” approach). As we pushed to make the JIT robust enough to use for developer sandboxes, we came across some tricky bugs that challenged the JIT’s single-entry/single-exit model.
Consider the following example and suppose the JIT needs to generate a translation for lines 3 and 4:
1: function doSomething($val, $extra) {
2: global $base;
3: $extra = null;
4: return $base + $val;
5: }
The tracelet approach works by observing the types of locals at the beginning of line 3 and generating specialized code based on the types of locals like so:
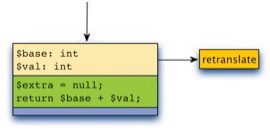
The tracelet begins with guard code (shown in yellow) that makes sure that $base and $val are integers before entering the body (shown in green). One might assume these checks would be sufficient for the lifetime of the tracelet, but many simple operations in PHP are capable of having side effects that can affect correctness and safety. For example, the assignment operation on line 3 may have invoked a __destruct method, which in turn may have changed the type of $base, which means that we cannot safely assume that $base is still an integer on line 4.
While the doSomething() function is a contrived example, we encountered real-world instances of this bug in a variety of forms and we needed a way to fix it, preferably without hurting performance. We decided to address the issue by enhancing the JIT to be capable of generating “side exits” like so:
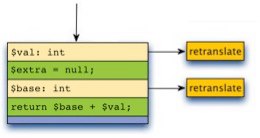
The idea behind side exits is to allow execution to bail out of a tracelet part way through if some rare condition arises, such as the type of an aliased local changing. Conceptually, the JIT still limits traces to a single basic block with a main exit that is usually taken, but now it’s also capable of generating side exits to handle uncommon cases.
Type prediction for return types
After implementing the “side exit” mechanism, we sought out other opportunities where we could leverage side exits to make tracelets longer (thereby reducing the performance overhead of tracelet boundaries and extending the CPU “mechanical sympathy” effect of longer chains of continuous code execution). For basic blocks that contained several PHP method calls, we noticed that the JIT often generated several short tracelets because the return types of the method calls were not known at translation time. Consider the following example:
PHP code
abstract class C {
function addTwoNumbers() {
return $this->one() + $this->two();
}
}
HipHop bytecode
0: This
1: FPushObjMethodD 0 "one"
7: FCall 0
9: UnboxR
10: This
11: FPushObjMethodD 0 "two"
17: FCall 0
19: UnboxR
20: Add
21: RetC
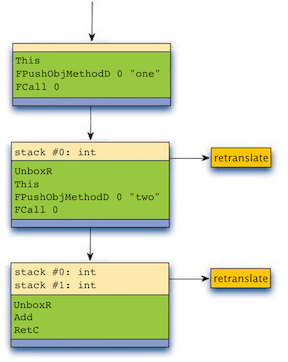
Suppose that one() and two() will return integers at run time and that their return types are not known at translation time. When translating the addTwoNumbers() method, our original implementation would generate a series of tracelets as shown in Figure 1 below.
As an experiment, we modified HHVM to profile method call return types during the first few web requests (running them under the bytecode interpreter) and we modified the JIT to make conservative type predictions based on this profile information, using side exits to handle cases where predictions fail. By using type prediction, the JIT can generate a single tracelet that covers the entire body of addTwoNumbers(), as shown in Figure 2.
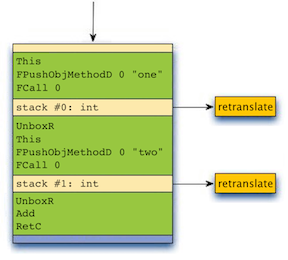
Using type prediction for function call and method call return types produced a ~2% reduction in CPU time for running the facebook.com site.
Changing how parallel tracelets link together
One of the core ideas behind the JIT’s tracelet approach is the ability to generate multiple tracelets for a given source location to accommodate different input types. Multiple tracelets generated for the same source location are referred to as “parallel tracelets” and are linked to each other in a chain via conditional branches.
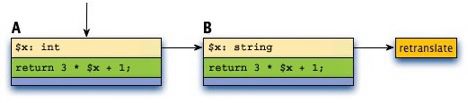
In our original implementation, when a new parallel tracelet was generated it was linked to the head of the chain. For example, suppose you have a simple function foo($x) that is called twice, passing in an integer the first time and passing in a string the second time. The tracelet generated by the first invocation (A) and the tracelet generated for the second invocation (B) would be linked together in a chain like so:
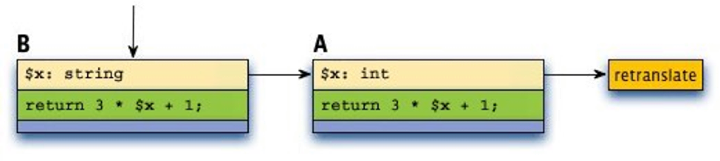
As an experiment, we tried changing the JIT to link new parallel tracelets to the end of the chain instead of linking them to the head. Under this new scheme, tracelets A and B would chain together like so:
Linking new parallel tracelets to the end of the chain produced an unexpectedly large reduction in CPU time – approximately 14% at the time we ran the experiment. We were surprised by this result, so we did some digging into hardware counters and HHVM internal counters to understand where the win came from.
HHVM has counters that track how many times tracelet guards were entered and how many times tracelet bodies were entered. Dividing the latter by the former, we can compute the tracelet “success” rate. When generating the home page for www.facebook.com, linking new tracelets to the head of the chain produces a ~79.9% tracelet success rate, while linking them to the end of the chain produces a ~91.6% tracelet success rate. This helps explain why this change produces a win, but it doesn’t fully explain why it has such a large effect.
The x64 hardware counters give some more insight into what’s happening at the processor level. Many of the hardware counters showed improvements, but the 30%-50% drop in iTLB misses really stood out. A lower tracelet success rate means the processor is performing more jumps across different pages of memory, which puts more pressure on the iTLB and increases the miss rate. Each iTLB miss causes the processor to do a walk over the page table (called a “page walk”). Page walks can be particularly compute-intensive for large applications (like Facebook’s site) where the page table is so big that it exceeds the capacity of the last-level cache (LLC). So it makes sense that cutting iTLB misses in half would have such a large effect on CPU time.
This surprising win inspired us to spend more energy looking into LLC misses, code locality, and other hardware resource issues to see if there’s more low hanging fruit in this area.
The road ahead

Deploying HHVM to production is not the end goal, but rather a means to continue improving the performance of our PHP code base going forward. HHVM enables us to pursue a broader range of optimization strategies for our PHP development stack, from the runtime and base library APIs down to the bare-metal machine code we generate. We plan to leverage this flexibility to make Facebook’s web tier even more efficient in the coming years.
We’re also excited to continue improving the HHVM development experience by making our installation and development workflow easier and more flexible and by supporting a wider range of popular PHP applications and frameworks.
Find out more about HHVM
HHVM is an open source project developed at Facebook. For the latest news on HHVM, find us at hhvm.com.
Related articles and links
- “The HipHop Virtual Machine” by Jason Evans
- HHVM blog
- HHVM open source on github
Drew Paroski is a software engineer on the HipHop team at Facebook.








