
As more and more people around the world start logging on to Facebook, we have an increasingly large responsibility to keep things fast. This is especially true in developing areas, where devices stay in the market longer and people have longer upgrade cycles for new devices. We want to make sure we look into possible opportunities for performance improvements across all of our major mobile platforms.
Android is one of our biggest platforms, and it’s also the mobile platform with the greatest diversity of devices. Any performance or efficiency improvements on these devices could better the experience for millions of people around the world.
Today, we wanted to share some of our efforts to optimize Java bytecode for Android through a project we call Redex. Redex is a pipeline for optimizing Android .dex files. By applying a series of customizable transformations, a source .dex can be optimized before inclusion in an APK.

At the beginning of our optimization project, we decided that the best place to do our optimizations was after the .dex files were created and before assembling the .dex files into an APK. The advantage of doing our optimizations at the bytecode level (as opposed to, say, on the source code directly) is that it gives us the maximum ability to do global, interclass optimizations across the entire binary, rather than just doing local class-level optimizations. We opted to perform the transform on dex bytecodes rather than Java bytecodes because certain transforms can only be done post-DXing. This would be analogous to the post-linking stage in a C-style compilation process, where you can make global optimizations across your entire binary.
We realized that engineers would likely continue to come up with new and creative bytecode optimizations over time. Facebook engineers tend to move fast, so we wanted to architect something that would benefit from multiple engineers working on lots of optimizations. We organized our optimization pipeline as a series of stages, with the “original” .dex entering at the beginning of the pipeline and the “transformed” .dex exiting at the end. Each stage in the pipeline can be thought of as a stand-alone “optimization plugin” that snaps into place behind the previous stage, allowing us to chain multiple different, potentially unrelated transforms behind one another. This makes it really flexible from an engineering perspective, as multiple engineers can experiment with different optimizations in parallel and then plug them into the final pipeline only when they are ready.

The Redex pipeline is generalized to allow any kind of .dex transformation, but today we want to focus on using Redex to minimize how much bytecode ships in the APK.
Reducing bytecode
There are many good reasons to reduce the amount of bytecode in a shipping app. In developing countries, flash size is often limited to keep device costs affordable — even a few megabytes can make a difference on a phone that has less than 1 GB of storage. Fewer bytes also means faster download times, faster install times, and lower data usage for cell users. Lastly, less bytecode also typically translates into faster runtime performance. All other things being equal, less bytecode means fewer instructions to execute and fewer code pages to fault into memory, which is going to be a performance improvement for resource-intensive scenarios, like application cold start.
At the onset of this project, we started looking at some of the raw .dex files generated using the default compilation toolchain. As we stared at the bytecode, we began to find some common patterns of things that we could optimize out with Redex. Let’s look at a few optimization stages we’ve added to the pipeline to reduce .dex file size.
Minification and compression
Minification is commonly done for web languages such as Javascript and HTML to reduce bytes over the wire by reducing and minimizing strings without changing functionality. These techniques are effective in Java, with some qualifications.
Human-readable strings are extremely valuable for engineers during development time — for things like class paths, file paths to source files, function names, and so on — but strings actually take up quite a lot of bytes in the compiled bytecode. Furthermore, the runtime doesn’t typically care about these descriptively named strings: It will call function “abc()” just as easily as it calls function “MyFooSuccessCallback()”.
For that reason, we can typically go through and replace long human-readable strings with any (shorter) placeholder strings. This reduces how many bytes are dedicated to strings without affecting the application functionality.

There are some qualifications to this, though. Source file paths, while not explicitly necessary for code execution at runtime, are extremely useful for engineers when something goes wrong. If we were to replace them with some short but random placeholder string, or even to strip them out entirely, we’d lose an important hint when following up on bug reports.

As with pure minification, we can go through our .dex and replace file path strings with a shorter placeholder string. However, we need to maintain the back-map to the original strings so we can reconstruct the file’s paths to source when we need them, such as during a bug report. We don’t actually need to ship this back-map in the APK itself, since for all practical purposes it will never be used by the machine code in the field, so this ends up being an improvement for our shipping APK size.
Inlining
Inlining is a general technique for moving the functionality of a called function into its caller function, to reduce the overhead of a function call without changing functionality. In addition to potentially improving performance of code execution, this can also lead to size reductions if done correctly. However, if done incorrectly, inlining can easily increase the size of the final binary instead.
Good software engineering practices typically encourage proper encapsulation of scope and class responsibilities. While these strategies are important during the engineering process, they also can leave some optimization opportunities in the final bytecode.

One of the easiest examples is that of wrapper functions. These are typically small functions added to provide a simpler class API to engineers or adapt functions to accept different lists of parameters. This also might include simple accessor functions (setter/getters) that are necessary to include in a class API but that might never even be called during runtime. During the initial compilation of class files, it isn’t immediately obvious which of these functions are superfluous, but by the time we have our initial .dex file, we can see which global optimizations are available.
Additionally, for classes calling into other classes, there may potentially be wrapper functions calling into other wrapper functions — we should just cut out the middleman. In many cases, that is exactly what we do. Whenever we inline one function into another, we can reduce the overhead (and bytecode) associated with a function jump.
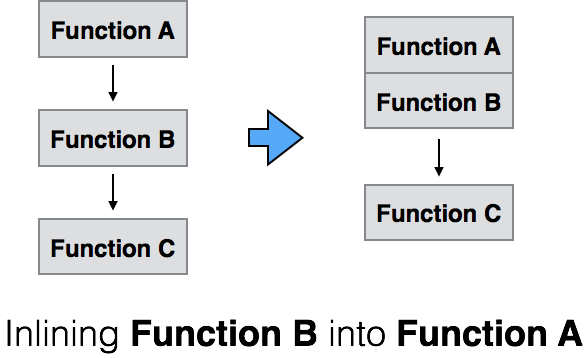
Naturally, this needs to be done very carefully. Many times there is still some value provided by accessor or wrapper functions — runtime access checking or polymorphism — but in the instances when we can assure that this technique will not cause any correctness errors, then the upside is bytecode reduction.
There is another situation where inlining may be possible. Say that a parent is calling into a child function but needs to make a detour through an intermediate function first. This might be the case for type covariance checking, where we want to run some simple runtime checking. Unlike the previous example, this intermediate function might be trivial, but we can’t completely strip it out; it is doing something useful for us at runtime. However, many of these functions are so small that the bytecode overhead of calling into them is nearly as large as the functions themselves.
In a simple case where we have a 1:1 calling relationship between the parent and child function, we can potentially just inline the detour function into either the parent or the child function, as discussed above.
However, this gets more complicated when the calling relationship between parent and child is 1:N or N:1 — or even N:N. In these cases, reckless inlining could increase our binary size instead of decreasing it! The trick in these situations is to figure out whether to inline the detour function into the parent(s) or child(ren), or whether there is no opportunity for improvement and we should abort inlining altogether. These are the decisions that are largely impossible to make at compile time but can be done by analyzing the global state of the .dex files.
Dead code elimination
In any large project, it is inevitable that dead or unreachable code will accumulate in the source code. Removing dead code is usually a pretty straightforward technique for reducing binary size without any other downside.
In some ways, dead code elimination is similar to mark-and-sweep garbage collection. If you start with a few entry points that you know are reachable, such as the main activity defined in the manifest file, you can run through the branches and function calls. While traversing this graph of function calls, we can mark each function we visit along the way. After we’ve traversed through every possible branch and function call, we can assume that all the unmarked functions are dead code that is safe for removal.
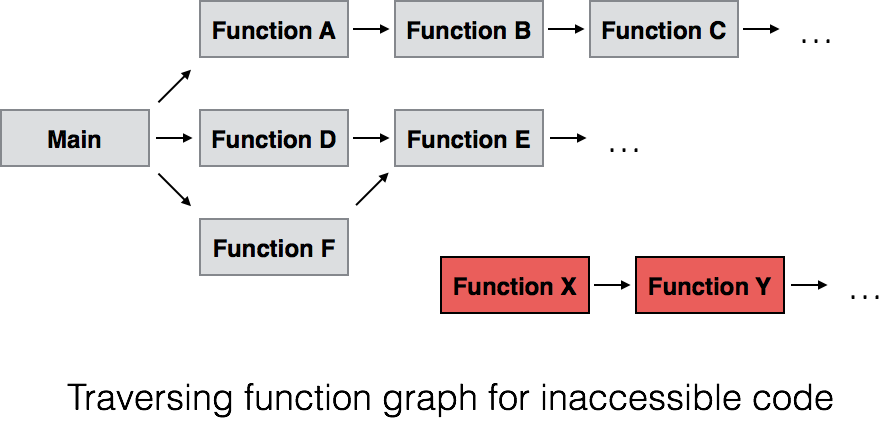
This technique for removing dead code is simple in theory, but there are a few practical complexities that need to be considered as well. You need to be careful when dealing with reflection, since it might not be obvious at build time that a function is being called by indirect means. You also need to be careful about classes and functions that are referenced via layouts or other resources — analyzing just the Dalvik bytecode itself isn’t sufficient to identify all the different entry points into a class. These examples require their own specialized techniques to identify dead code, but fundamentally they function similarly to the simple case.
Summary
We hope this gives you a taste of what Redex has to offer. In this post, we focused on the bytecode size reduction, but we’ve been working on a few other exciting optimization pipelines that we’d like to share in the future. Until then, stay tuned!
Thanks to David Alves, David Tarjan, and others for their help writing this post.








