")
Thousands of engineers write the code to create our apps, which serve billions of people worldwide. This is no trivial task—our services have grown so diverse and complex that the codebase contains millions of lines of code that intersect with a wide variety of different systems, from messaging to image rendering. To simplify and speed the process of writing code that will make an impact on so many systems, engineers often want a way to find how someone else has handled a similar task. We created Aroma, a code-to-code search and recommendation tool that uses machine learning (ML) to make the process of gaining insights from big codebases much easier.
Prior to Aroma, none of the existing tools fully addressed this problem. Documentation tools are not always available and can be out of date, code search tools often return myriad matching results, and it is difficult to immediately find idiomatic usage patterns. With Aroma, engineers can easily find common coding patterns without the need to manually go through dozens of code snippets, saving time and energy in their day-to-day development workflow.
In addition to deploying Aroma to our internal codebase, we also created a version of Aroma on open source projects. All examples in this post are taken from a collection of 5,000 open source Android projects on GitHub.
What is code recommendation and when do you need it?
Let’s consider the case of an Android engineer who wants to see how others have written similar code. Let’s say the engineer writes the following to decode a bitmap on an Android phone:
Bitmap bitmap = BitmapFactory.decodeStream(input);This works, but the engineer wants to know how others have implemented this functionality in related projects, especially what common options are set, or what common errors are handled, to avoid crashing the app in production.
Aroma enables engineers to make a search query with the code snippet itself. The results are returned as code recommendations. Each code recommendation is created from a cluster of similar code snippets found in the repository and represents a common usage pattern. Here is the first recommendation returned by Aroma for this example:
Code Sample 1
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 2;
// ...
Bitmap bmp = BitmapFactory.decodeStream(is, null, options);This piece of code recommendation is synthesized from a cluster of five similar methods found in the repository. Only the common code among the cluster of methods is shown here, with the specific details of individual methods removed in the gap (the … part).
What is this code recommendation trying to say? Well, it says that in five different cases, engineers set additional options when decoding the bitmap. Setting the sample size helps reduce the memory consumption when decoding large bitmaps, and, indeed, a popular post on Stack Overflow suggests the same pattern. Aroma created this recommendation automatically by discovering a cluster of code snippets that all contain this pattern.
Let’s look at another recommendation.
Code Sample 2
try {
InputStream is = am.open(fileName);
image = BitmapFactory.decodeStream(is);
is.close();
} catch (IOException e) {
// ...
}This code snippet is clustered from another four methods. It shows a customary usage of InputStream in decoding bitmaps. Furthermore, this recommendation demonstrates a good practice to catch the potential IOException when opening the InputStream. If this exception occurs in runtime and is not caught, the app will crash immediately. A responsible engineer should extend the code using this recommendation and handle this exception properly.
![Aroma code recommendations integrated in the coding environment. [Image: aroma_nuclide.png]](https://code-dev.fb.com/wp-content/uploads/2019/04/aroma_nuclide.jpg)
- Aroma performs search on syntax trees. Rather than looking for string-level or token-level matches, Aroma can find instances that are syntactically similar to the query code and highlight the matching code by pruning unrelated syntax structures.
- Aroma automatically clusters together similar search results to generate code recommendations. These recommendations represent idiomatic coding patterns and are easier to consume than unclustered search matches.
- Aroma is fast enough to use in real time. In practice, it creates recommendations within seconds even for very large codebases and does not require pattern mining ahead of time.
- Aroma’s core algorithm is language-agnostic. We have deployed Aroma across our internal codebases in Hack, JavaScript, Python, and Java.
How does Aroma work?
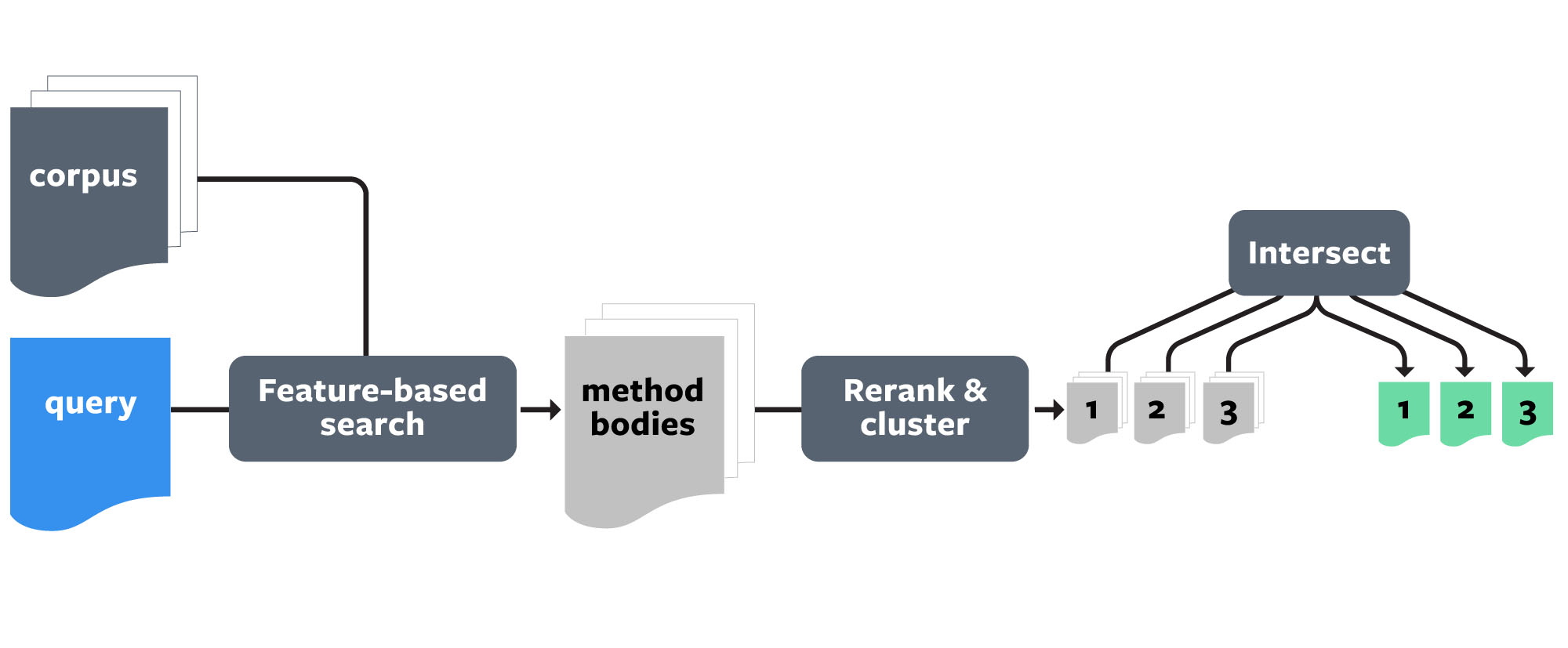 Aroma creates code recommendations in three main stages:
Aroma creates code recommendations in three main stages:
1) Feature-based search
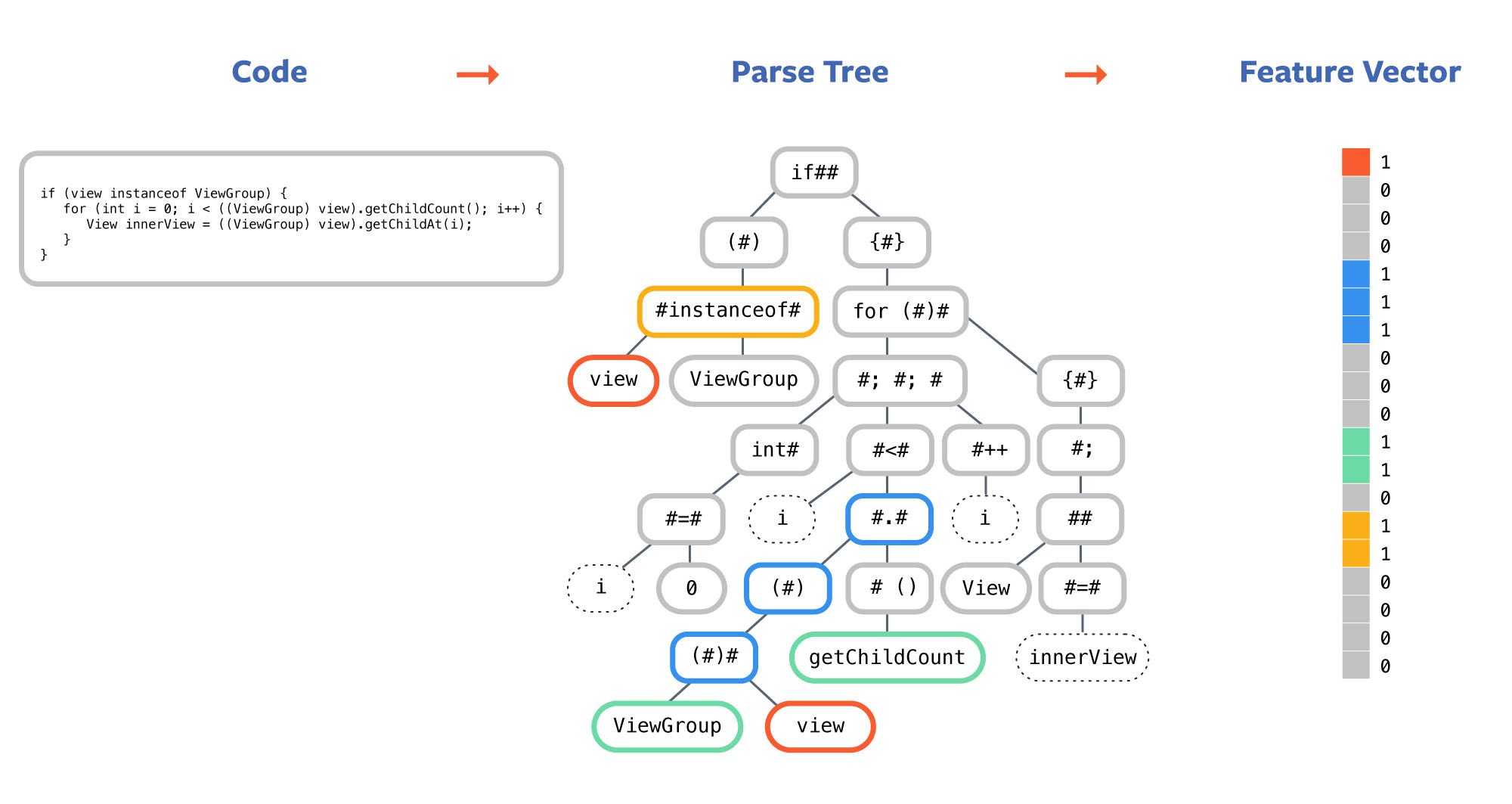
First, Aroma indexes the code corpus as a sparse matrix. It does this by parsing each method in the corpus and creating its parse tree. Then it extracts a set of structural features from the parse tree of each method. These features are carefully chosen to capture information about variable usage, method calls, and control structures. Finally, it creates a sparse vector for each method according to its features. The feature vectors for all method bodies become the indexing matrix, which is used for the search retrieval.
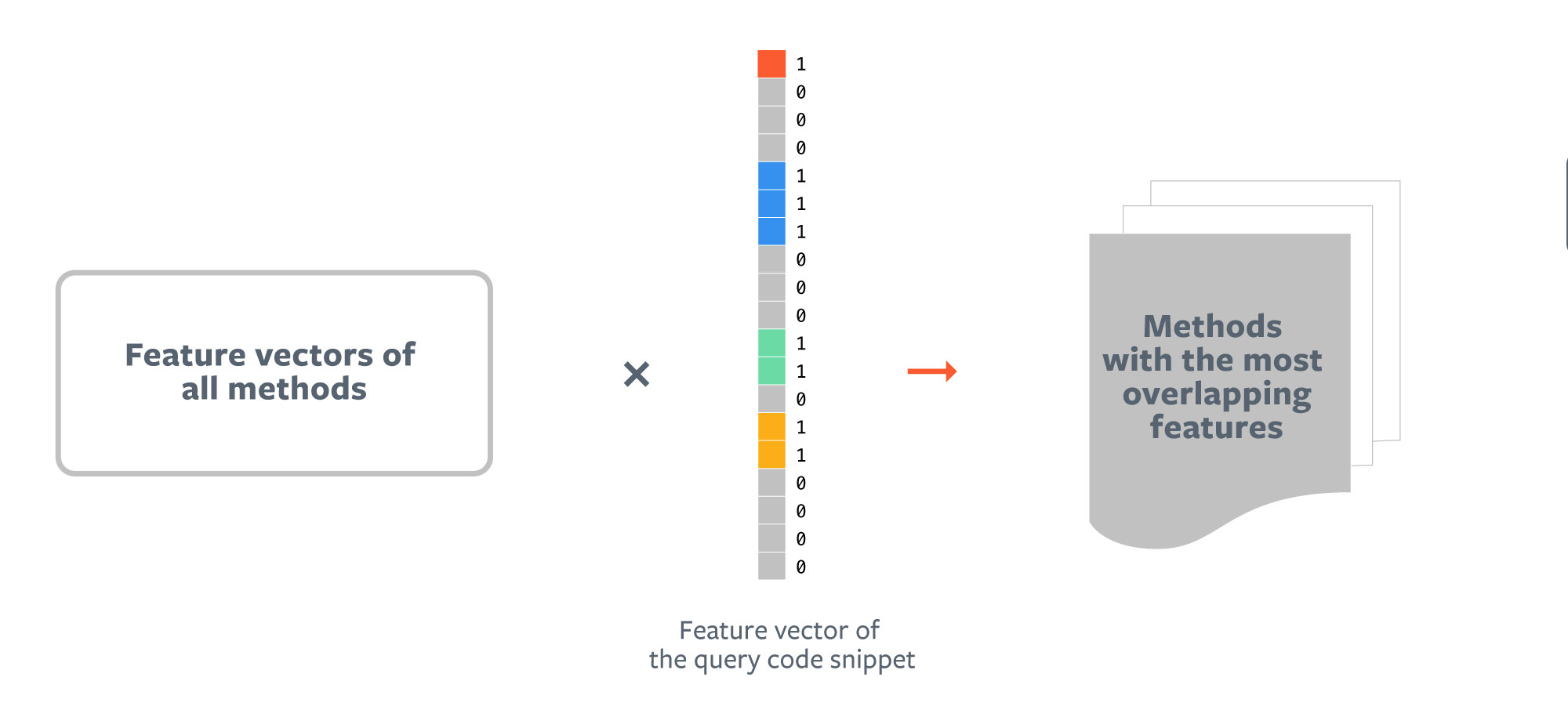
When an engineer writes a new code snippet, Aroma creates a sparse vector in the manner described above and takes the dot product of this vector with the matrix containing the feature vectors of all existing methods. The top 1,000 method bodies whose dot products are highest are retrieved as the candidate set for recommendation. Even though the code corpus could contain millions of methods, this retrieval is fast due to efficient implementations of dot products of sparse vectors and matrices.
2) Reranking and clustering
After Aroma retrieves the candidate set of similar-looking methods, the next phase is to cluster them. In order to do this, Aroma first needs to rerank the candidate methods by their similarity to the query code snippet. Because the sparse vectors contain only abstract information about what features are present, the dot product score is an underestimate of the actual similarity of a code snippet to the query. Therefore, Aroma applies pruning on the method syntax trees to discard the irrelevant parts of a method body and retain only the parts that best match the query snippet, in order to rerank the candidate code snippets by their actual similarities to the query.
After obtaining a list of candidate code snippets in descending order of similarity to the query, Aroma runs an iterative clustering algorithm to find clusters of code snippets that are similar to each other and contain extra statements useful for creating code recommendations.

3) Intersecting: The process of creating code recommendations
In the final stage, Aroma creates code recommendations from each cluster by intersecting all methods in that cluster. To illustrate how intersecting works, let’s take a look at a few methods in the cluster that becomes the first recommendation.
Code snippet 1 (adapted from this project):
InputStream is = ...;
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 2;
Bitmap bmp = BitmapFactory.decodeStream(is, null, options);
ImageView imageView = ...;
imageView.setImageBitmap(bmp);
// some more codeCode snippet 2 (adapted from this project):
BitmapFactory.Options options = new BitmapFactory.Options();
while (...) {
in = ...;
options.inSampleSize = 2;
options.inJustDecodeBounds = false;
bitmap = BitmapFactory.decodeStream(in, null, options);
}Code snippet 3 (adapted from this project):
BitmapFactory.Options bmpFactoryOptions = new BitmapFactory.Options();
// some setup code
try {
options.inSampleSize = 2;
loadedBitmap = BitmapFactory.decodeStream(inputStream, null, bmpFactoryOptions);
// some code...
} catch (OutOfMemoryError oom) {
}The intersecting algorithm works by taking the first code snippet as the “base” code and then iteratively applying pruning on it with respect to every other method in the cluster. The remaining code after the pruning process will be the code that is common among all methods, and it becomes the code recommendation. Additional details are in our paper on the topic.
In this example, each code snippet contains code that is specific to their projects, but they all contain the same code that sets up the options for decoding the bitmap. As described, Aroma finds the common code by first pruning the lines in the first code snippet that do not appear in the second snippet. The intermediate result would look like this:
InputStream is = ...;
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inSampleSize = 2;
Bitmap bmp = BitmapFactory.decodeStream(is, null, options);The code in the first code snippet about ImageView does not appear in the second snippet and is therefore removed. Now Aroma takes this intermediate snippet and prunes the lines that do not appear in the third snippet, fourth snippet, and so on. The resulting code is returned as a code recommendation. As shown in Code Sample 1, the code recommendation created from this cluster contains exactly the three lines of code that are common among all method bodies.
Other code recommendations are created from other clusters in the same way, and Aroma’s algorithm ensures that these recommendations are substantially different from one another, so engineers can learn a diverse range of coding patterns by looking at just a few code snippets. For instance, Code Sample 2 is the recommendation computed from another cluster.
This is the true advantage of using Aroma. Rather than going through dozens of code search results manually and figuring out idiomatic usage patterns by hand, Aroma can do it automatically and in just a few seconds!
Broader picture
Given the vast amount of code that already exists, we believe engineers should be able to easily discover recurring coding patterns in a big codebase and learn from them. This is exactly the ability that Aroma facilitates. Aroma and Getafix are just two of several big code projects we are working on that leverage ML to improve software engineering. With the advances in this area, we believe that programming should become a semiautomated task in which humans express higher-level ideas and detailed implementation is done by the computers themselves.
We’d like to thank Koushik Sen and Di Yang for their work on this project.








