Enabling developers to prototype, test, and iterate on new features quickly is important to Facebook’s success. To do this effectively, it’s key to have a stable infrastructure that doesn’t introduce unnecessary friction. This gets significantly more challenging when the infrastructure in question must also scale to support more than 3 billion people around the world, leverage an increasing amount of computational power, and handle an extremely large and growing codebase.
Two of the ways we address this challenge are better abstractions and automated testing. The abstractions include a service-oriented infrastructure that allows structuring our business logic into independently written, deployed, and scaled components. While this is important for fast iterations, it also increases testing complexity: Unit tests are useful for checking the logic within a service but fail to test the dependencies between services. Integration testing comes to the rescue, but as opposed to the well-standardized unit testing frameworks, there was no off-the-shelf integration testing framework that we could use for our back-end services. Therefore, we designed and built one.
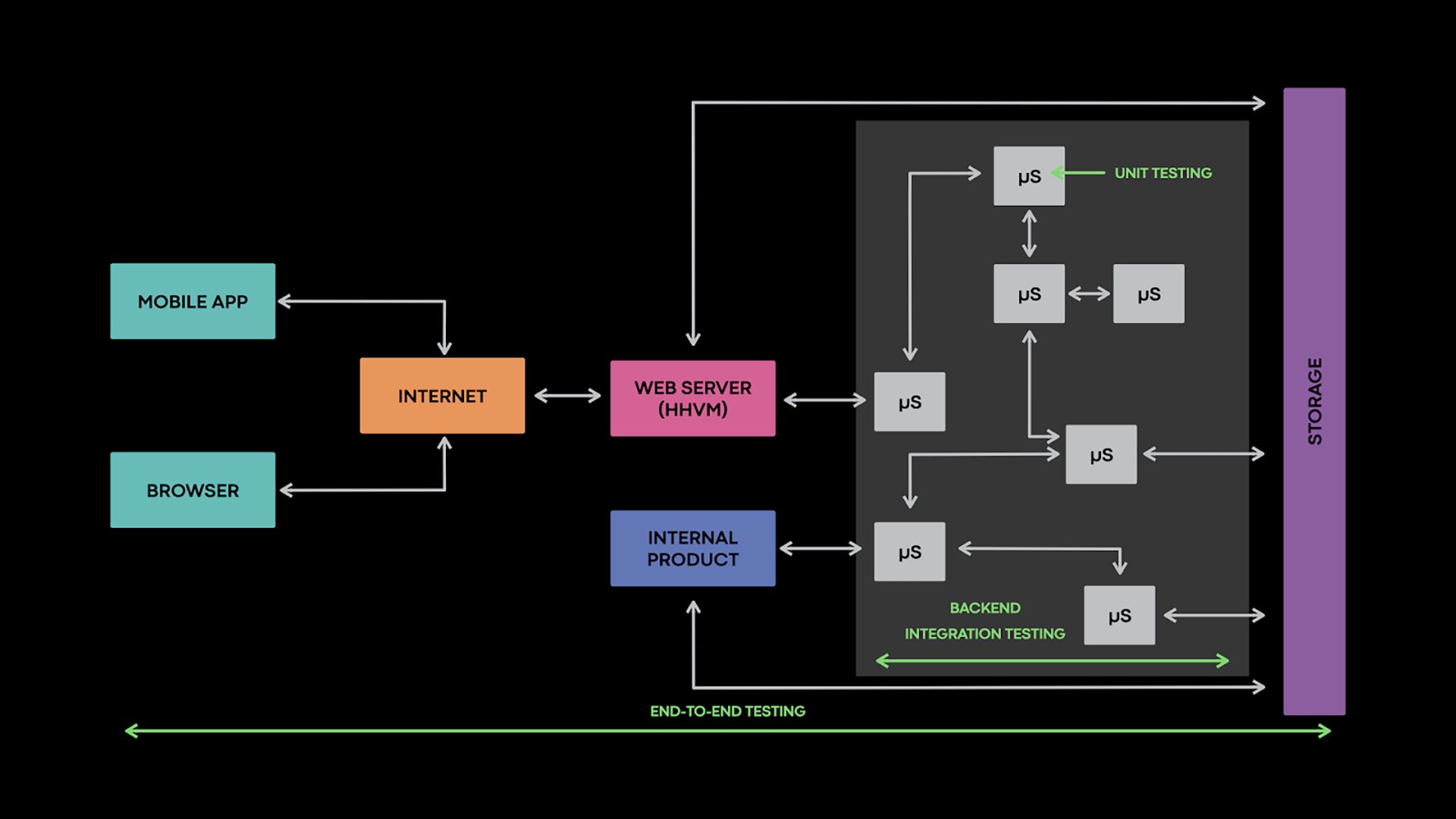
Today, we are detailing a new autonomous testing extension that we’ve built on top of this integration testing infrastructure, as well as a behind-the-scenes look at the infrastructure itself. This extension borrows ideas from fuzz testing, an automated technique that uses random inputs to find bugs, and leverages the homogeneity of our software stack to provide a seamless developer experience and encourage quick iterations. To date, most of Facebook’s autonomous testing has focused on our frontends or security through tools like Infer, Sapienz, and Zoncolan. Here, we’ll discuss how we autonomously test back-end services.
Integration testing infrastructure
An integration testing infrastructure needs to encourage engineers to write effective tests, automatically run them when needed, and present the results in an intuitive fashion. It does this by providing a code framework, test scheduling and execution capabilities, and appropriate hooks into the continuous integration system. The code framework encapsulates boilerplate and provides common abstractions and patterns that eliminate common pitfalls, such as using flaky constructs, when writing tests. We’ll cover three aspects of writing a test, focusing on the bits specific to integration testing: defining the test environment, specifying the inputs, and checking the outputs.
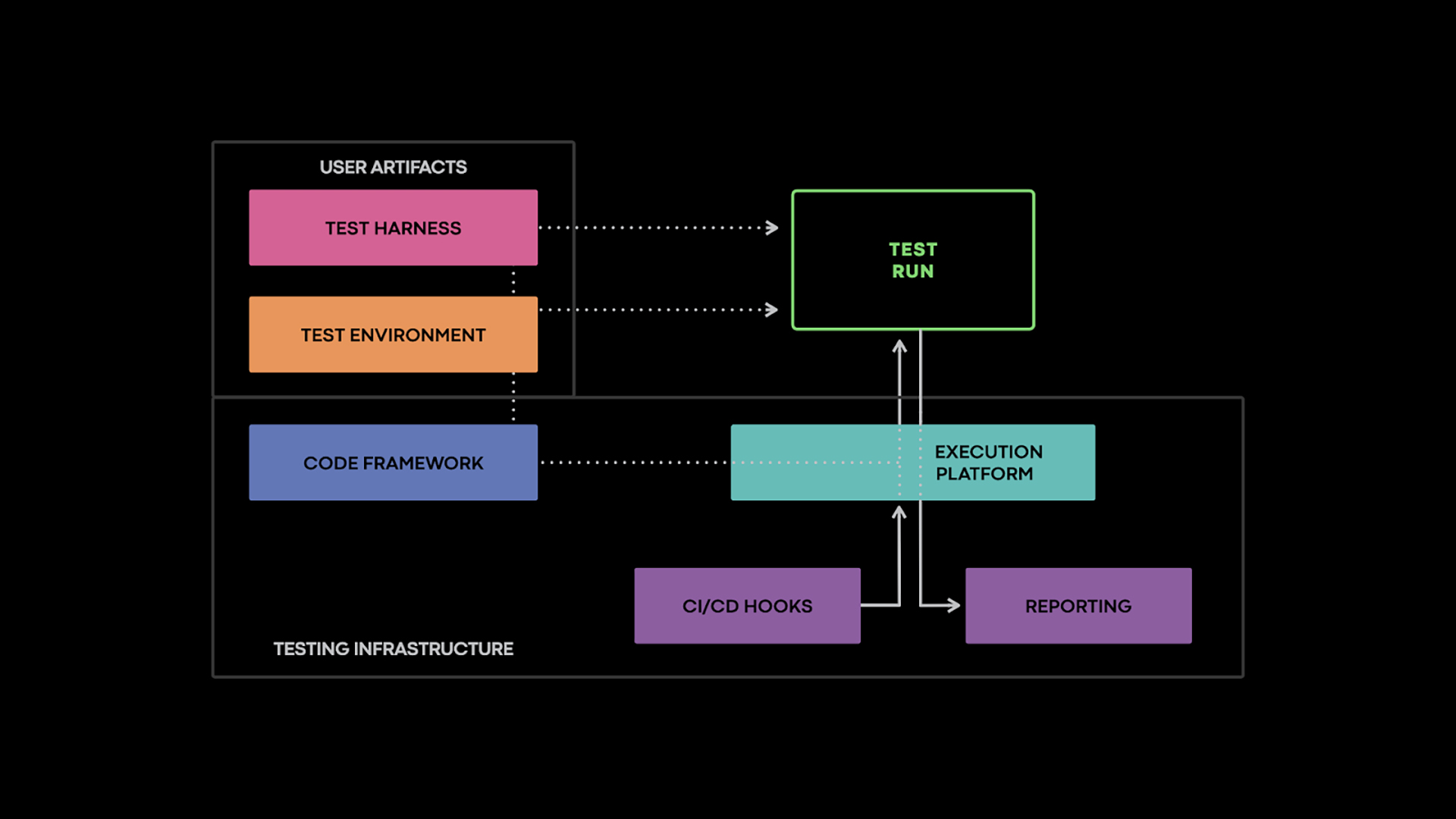
Defining the test environment
To provide deterministic results and avoid side effects, tests don’t typically run in production environments. This holds particularly true for unit tests, which focus on a small unit of code and replace external dependencies with mocks or fakes. While this avoids side effects, it has the downside of underapproximating the system under test. The mocks inherently implement only some of the behaviors from the real dependencies. As a result, some bugs can go undetected. Maintaining the mocks also requires a considerable engineering effort.
Integration tests rely less on mocking. Testing back-end services typically involves one or more unmodified services. There are a couple of advantages to not having to modify the services for testing. For one, it avoids burdening the service owners, but, more important, it makes the tests exercise the same code that will run in production, which therefore makes them more representative.
This raises two important challenges that must be addressed. The first involves creating test environments that are suitable for running unmodified services. Next, it must be determined how to set the boundaries of the test environment and how to handle connections that cross these boundaries.
These challenges require a pragmatic approach. Our solution reuses the production infrastructure, in particular the containerization and routing systems, to build test environments. However, we create separate ephemeral entities within the infrastructure for each test. This results in test environments that receive no production requests without being automatically restricted from connecting to production systems. This enables certain tests to share read-only assets or APIs with the production environment. At the same time, we use an additional isolation layer to restrict other tests from connecting to production systems.
We empower service owners to define the boundaries of their test environment depending on what service interactions they want to check. Network requests are preferentially served by services running in the same environment as the caller. If an appropriate service does not exist within the environment, requests can either go to a mock, go to an in-memory replica of a production system, get blocked, or be forwarded to the production environment, such as for read-only requests.
In this setting, mocking works by creating and starting — on the fly — a service with the same interface as the original service but with a trivial implementation. The mock service runs in the same address space as the test harness. This lets the two easily interact. Mock implementation can be changed at runtime, similarly to how we would change a unit test mock. We wrap each mock method handler into a standard Python MagicMock or StrictMock. Doing so makes it easy to inspect the number of times it got called and what arguments it received.
In-memory replicas are useful for common dependencies, such as storage. In addition to these options, the testing infrastructure can block connections made from within the test environment. We discuss this in more detail later, in the context of autonomous testing.
Test inputs
In the most general form, test inputs are provided in an imperative fashion as a test harness, a program that gets executed in the test environment alongside the service(s) under test. The harness exercises the services either directly, possibly through a remote procedure call (RPC), or indirectly by making changes in the test environment. For example, it can apply new global configuration settings or shut down a test service replica. While the testing framework provides the primitives for these operations, building the test is the responsibility of service owners.
The mocks are another source of input involved in integration testing. They may be configured to send specific responses that fundamentally act as inputs to the service under test. Dependency failures represent a special case of input that can be simulated by throwing an exception from the mock.
Test oracles
Most test oracles are custom assertions about the service’s behavior. While these are similar in principle to unit test assertions, they are only able to inspect the externally visible behavior of the service under test, not its internal state. This includes RPC responses, arguments passed to mocked calls, and data written to ephemeral test databases, among other examples.
The testing infrastructure also detects generic failures, such as crashes or errors flagged by sanitizer instrumentation and service health problems flagged by the monitoring infrastructure.
Extensibility
One of the design goals of the integration testing infrastructure was to allow teams to build extensions on top of it. We have two main uses for such extensions. The first use is to address common patterns that arise in a team’s services, such as test environment setups or frequently used customizations. These extensions can also define the basis for specialized types of tests, such as disaster readiness tests. These tests verify that we can bootstrap from scratch the most fundamental services in our infrastructure, like ZooKeeper, if needed.
Autonomous integration testing
The framework described above gives service owners the scaffolding for writing integration tests. However, the testing infrastructure can do even better in many situations by providing reasonable defaults or even automatically generating all test components.
To define the test environment, the infrastructure mirrors a service’s production environment. This is defined in a standard fashion for all services designed to be consumed by Facebook’s cluster management system, Twine. However, the other components can also programmatically inspect it. Tests can inspect the environment and sanity-check it before making specific modifications, and passing it back to Twine to instantiate. Sanity checks hold responsibility for informing the service owner if their intervention is required in certain cases, such as if the service requires special hardware that is unavailable in the default testing machine pool. The testing specific modifications include isolating the test instance from production systems, lowering the service’s resource requirements to save capacity, and other small changes.
Isolation is a particularly important element in autonomous testing. This is because the testing infrastructure decides which inputs to use. Regardless of its choices, though, the test must have no side effects. For example, in one situation, data regarding API failures from a test reached the monitoring infrastructure, which mistakenly thought the failures originated from production systems. As a result, it raised spurious alarms.
While straightforward from a technical perspective, completely isolating a test environment from the rest of the infrastructure often leads to a malfunctioning test. This is why we have to take a more nuanced approach:
- We allow known read-only traffic to go through.
- We give service owners the ability to set an allowlist for safe destinations.
- We reroute all standard RPC traffic to a universal mock, which can impersonate any service and return falsy values.
- We block all other network requests.
With this approach, we can run one-third of our services in a safe test environment with zero human intervention.
When it comes to implementing the isolation, we combine two approaches: a granular application-level isolation and a coarser network-level isolation. For RPC calls, we employ application-level isolation. Doing so can block connections based on the API being called. The network-level isolation works at the IP:port level of granularity. We typically use it for allowing connections to services that listen on well-known ports, such as DNS. In addition to making decisions based on the connection destination, the isolation system can make decisions based on the code that initiates the connection. This is valuable, as some code can use a potentially unsafe API in a safe way. The isolation logic identifies callers by inspecting the stack trace at runtime.
When building the isolation layer, we considered two implementation options: BPF and LD_PRELOAD. Ultimately, we decided on the latter because it provides more flexibility. The preload logic retrieves a service-specific isolation configuration from our configuration management system, and blocks connections accordingly by intercepting calls to the libc connect, sendto, sendmsg, and sendmmsg functions.
Test inputs
To explore test automation further, we investigated existing automatic techniques. Fuzzing was a natural match for our integration testing structure. Its dynamic nature fits well within the classic testing paradigm, while its automatic input generation complements manually written tests.
Fuzzing, at its core, is a form of random testing. Still, despite its fundamental simplicity, setting up a fuzz test requires a few manual steps:
- Carve out the code to be fuzzed into a self-contained unit (the test target). Typical fuzz tests operate on a relatively small unit of code, comparable with unit tests.
- Write a fuzz test harness responsible for shaping random data into the types expected by the fuzzed code and calling the right function(s) in the test target.
- Ensure the random data respects the constraints expected by the test target.
The last point deserves additional clarification. Say we want to fuzz the strlen function, which expects a valid pointer to a NULL-terminated string. When fuzzing generates inputs, it needs to assure they are all valid pointers to NULL-terminated strings. Anything else will cause the code to crash — not because a bug exists in the code, but because a mismatch exists between caller arguments and callee expectations. Typically, these expectations (aka API contract) are implicit, hence the need for manual work.
When combining fuzzing with integration testing, we can automate the manual steps above:
- We create the environment based on the production environment as previously described. This eliminates the need to manually carve out the code, which must be tested.
- The API contract of a service is explicit and available programmatically, thanks to Facebook’s Thrift RPC framework. Thrift offers an interface definition language with reflection capabilities, enabling enumeration of APIs and their arguments. Furthermore, the argument types and their attributes, like requiredness, can be recursively inspected. After generating appropriate values based on this information, each argument can be dynamically instantiated. We use this ability in two ways: First, to construct inputs for the service under test. Second, to automatically mock the service’s dependencies and send back to it default values. This allows automatic creation of random data in the right format, and therefore automatic fuzz harness creation.
- Finally, a service may have no expectations about the inputs it receives over the network. This eliminates all opportunities for crashes caused by a mismatch between input values and service expectations, meaning that all crashes encountered point to actual bugs.
The simplest way to construct inputs is to randomly choose appropriate values for each data type. This approach automatically offers a testing baseline and has the advantage of identifying corner cases that engineers may overlook when manually devising tests. Manually configured “corner case” values for each data type, like MAX_INT for integers, can augment this process.
The weakness of random (and fuzz) testing stems from its ineffectiveness when input validity involves complex constraints, like a checksum. In such cases, naive fuzzing has difficulty coming up with valid inputs. As a result, it does not exercise service logic beyond any initial input validation.
To overcome this problem and improve autonomous test effectiveness, we use request recording. We periodically record a small fraction of requests that hit production services, sanitize them, and make them available to the testing infrastructure. Here, instead of running tests with completely random inputs, the recorded requests get mutated to various extents. The rationale behind this approach is that resulting inputs will preserve enough of the original requests’ valid structure to exercise “deep paths” but also enough randomness to exercise corner cases on these paths.
At the opposite end of the spectrum from pure fuzzing, we use the recorded requests without mutating them. This verifies that a new version of a service can handle the traffic received by the previous version without behaving abnormally, similar to a classic canary test. Approaching the problem through record and replay has the advantage of not requiring separate testing infrastructure and not affecting production systems.
Test oracles
In addition to crashes and sanitizers like ASAN, we look for undeclared exceptions and inspect logs for suspicious messages. One interesting example involves the MySQL ProgrammingError exception. This exception is typically triggered by the fuzzer’s ability to affect a SQL query. It does this by calling an API with unexpected arguments, which is indicative of a SQL injection vulnerability. A similar situation involves the Python SyntaxError exception. In this case, the fuzzer is able to modify a string that gets passed to eval, pointing to a potential arbitrary code execution.
Deployment and lessons learned
Our deployment strategy for the autonomous integration tests involved two steps. First, we started by running them in the background for as many services as possible without service owner involvement. This allowed us to understand what improvement opportunities exist and the best way to report issues. Next, we encouraged service owners to opt in to run this test automatically before deploying a new version of their service. We chose an opt-in model because a test failure requires immediate action to unblock the service’s deployment pipeline. We are now moving from step 1 to step 2.
In the first step, using the isolation applied to fuzz integration tests, we were able to safely and automatically fuzz test about one-third of Facebook’s Thrift services. Fuzzing identified more than 1,000 bugs. For each bug, we assigned a report to the service owners. The remaining two-thirds of services had either a nonstandard setup or strict permissions that prevented us from reusing their production artifacts, or they failed due to the strict isolation that we enforced. We engaged with service owners only through bug reports at this step.
We learned several things in this process. First, through our testing, we learned that significant opportunities exist for improvement in isolating test environments. This led us to support a more fine-grained and scalable approach for labeling read-only APIs. Separately, we continue considering ways to provide first-class abstractions for integration testing environments and offer the ability to reuse test environments through composability.
Second, we learned that it is essential to offer service owners as much information as possible about the bugs we detect. Debugging is inherently difficult with integration test failures, in comparison to unit tests. While a stack trace can help understand a crash, efficient debugging also requires a good understanding of the service that crashed and the libraries it uses. We have noticed that, overall, API contract violations were easier to debug than crashes.
Third, we noticed that random inputs make it more difficult to explain bugs, and engineers have a harder time reasoning about them and identifying their root cause. We can solve this by using recorded traffic more extensively and providing mostly well-formed inputs. In some situations, engineers may also assume that services can break their API contract when given random inputs, by throwing undeclared exceptions or crashing. We advocate against such practices and instead rely on thorough input validation.
Finally, having visibility into fuzz test effectiveness is crucial. So far, we have considered bugs found only as an effectiveness metric, and we are now starting to measure whole-service coverage. We anticipate that this will give service owners insights on what parts of the service require additional testing. It also points to changes we can make to the integration fuzz testing infrastructure to increase overall coverage moving forward.








