
To make it easier to build and deploy natural language processing (NLP) systems, we are open-sourcing PyText, a modeling framework that blurs the boundaries between experimentation and large-scale deployment. PyText is a library built on PyTorch, our unified, open source deep learning framework. It offers several benefits for NLP development:
- A simplified workflow for faster experimentation.
- Access to a rich set of prebuilt model architectures and utilities for text processing and vocabulary management to facilitate large-scale deployment.
- The ability to harness the PyTorch ecosystem, including prebuilt models and tools created by researchers and engineers in the NLP community.
AI researchers and engineers can now use PyText to more quickly and easily experiment with and deploy systems to perform document classification, sequence tagging, semantic parsing, multitask modeling, and other tasks. At Facebook, we’ve used this framework to take NLP models from idea to full implementation in just days, instead of weeks or months, and to deploy complex models that rely on multitask learning. At Facebook today, PyText is used for more than a billion daily predictions, demonstrating that it can operate at production scale and still meet stringent latency requirements.
Engineers working on neural networks have historically faced a trade-off between frameworks optimized for experimentation and those optimized for production. This is particularly true for NLP systems, which can require creating, training, and testing dozens of models, and which use an inherently dynamic structure. Research-oriented frameworks can provide an easy, eager-execution interface that speeds the process of writing advanced and dynamic models, but they also suffer from increased latency and memory use in production. Frameworks that are optimized for production might facilitate deployment by presenting models as static graphs, but this approach makes it difficult to create dynamic representations of text sequences. PyTorch 1.0 accelerates the path from research to production by providing a single unified framework; PyText builds on that foundation to address the specific needs of NLP modeling.
We are now publishing our work, open-sourcing the PyText framework, and sharing pretrained models and tutorials for training and deploying PyText models at scale.
The need for better NLP
AI researchers and engineers have a wide and growing range of applications for systems that can understand our words. At Facebook, NLP is used to deliver more relevant content to people, provide powerful accessibility features, flag policy-violating posts, perform translations, and more. The state of the art in conversational AI is progressing rapidly, and PyText is helping us ship these new advancements more quickly, to improve the quality of our products. PyText is now implemented in Portal, our new video calling device, and in our M suggestions feature in Messenger. We are exploring other ways to use PyText in conversational AI.
Using PyText, Portal supports compositional and nested calling queries in “Hey Portal” voice commands. This feature allows people to use voice commands such as “call my dad,” which requires the system to understand the relationship between the caller and the person he or she is calling. It leverages semantic parsing work first shared in this paper, and we were able to bring the technique to production quickly with PyText.
We have used PyText to iterate quickly on incremental improvements to Portal’s NLP models, such as ensembling, conditional random fields, and a conflated model for all domains. This has improved the accuracy of our models for our core domains by 5 percent to 10 percent. We also used PyText’s support for distributed training to reduce training time by 3-5x for Portal.
The rapid iteration PyText enables also helps us improve the efficiency and scalability of our NLP models. With Portal, Messenger, and many other use cases, we need to run models in real time in order to offer quick responses. We also need NLP systems that operate efficiently at massive scale. PyText has made it easier for Facebook engineers to deploy advanced real-time NLP in systems used by billions of people speaking many different languages.
PyText builds on and complements Facebook’s other NLP systems. It can be used in conjunction with our fastText library, for example. Researchers and engineers can train word embeddings in fastText and then use them in PyText.
PyText also improves in important ways upon DeepText, which, for example, cannot implement dynamic graphs. Some of the semantic parsing and multitask learning models in PyText cannot be built with DeepText, because of conditional execution and custom data structures in the model. PyText also speeds training, because it can utilize GPUs and more easily implement distributed training. We are planning to use PyText as our main NLP platform going forward.
A flexible, modular design
PyText is built on PyTorch, and it connects to ONNX and Caffe2. With PyText, AI researchers and engineers can convert PyTorch models to ONNX and then export them as Caffe2 for production deployment at scale.
It offers a flexible, modular workflow, with configurable layers and extensible interfaces for model components. PyText can serve as an end-to-end platform, and developers can apply it out of the box to create entire NLP pipelines. But its modular structure also allows engineers to incorporate individual components into existing systems.
The role of each component, and its interaction with other modules, depends on the specific task. For example, the data handler component works with the trainer, loss, and optimizer components to train a model. But the data handler also interacts with the predictor and model for inference (running a trained model on live traffic). This modular approach reinforces PyText’s versatility — the platform can be used at virtually any point within the research-to-production process — to build entire NLP systems from scratch or to make modifications to existing systems.
PyText includes several other features to improve the workflow for NLP. The framework supports distributed training, which can dramatically speed up NLP experiments that require multiple runs. It also supports multitask learning for training multiple models at once. Other optimizations for training include:
- Portability. PyText models are built on top of PyTorch and can be easily shared across different organizations in the AI community.
- Prebuilt models. With a model zoo focused on common NLP tasks, such as text classification, word tagging, semantic parsing, and language modeling, PyText makes it easy to use prebuilt models on new data with minimal extra work.
- Contextual models. To improve conversational understanding in various NLP tasks, we can use PyText to leverage contextual information, such as an earlier part of a conversation thread. We built two contextual models in PyText: a SeqNN model for intent labeling tasks and a Contextual Intent Slot model for joint training on both tasks. In our tests, introducing contextual information produced significant performance gains on several data sets with M suggestions in Messenger.
For optimized inference in production, PyText uses PyTorch 1.0’s capability to export models for inference via the optimized Caffe2 execution engine. Native PyTorch models require Python runtime, which is not sufficiently scalable due to the multithreading limitations of Python’s Global Interpreter Lock. Exporting to Caffe2 provides the performant and efficient multithreaded C++ backend to serve huge volumes of traffic efficiently with high throughput. Other PyText features also make it easy to move a model to production and deploy it, including:
- Unified resources that apply to both research and production-oriented NLP work, such as simple APIs for training and inference, and text preprocessing that’s consistent for training and inference.
- Vocabulary management, so PyText can attach the vocabulary to a model after it’s been exported to Caffe2.
- Added support for string tensors to work efficiently with text in both training and inference.
Moving more easily from research to production
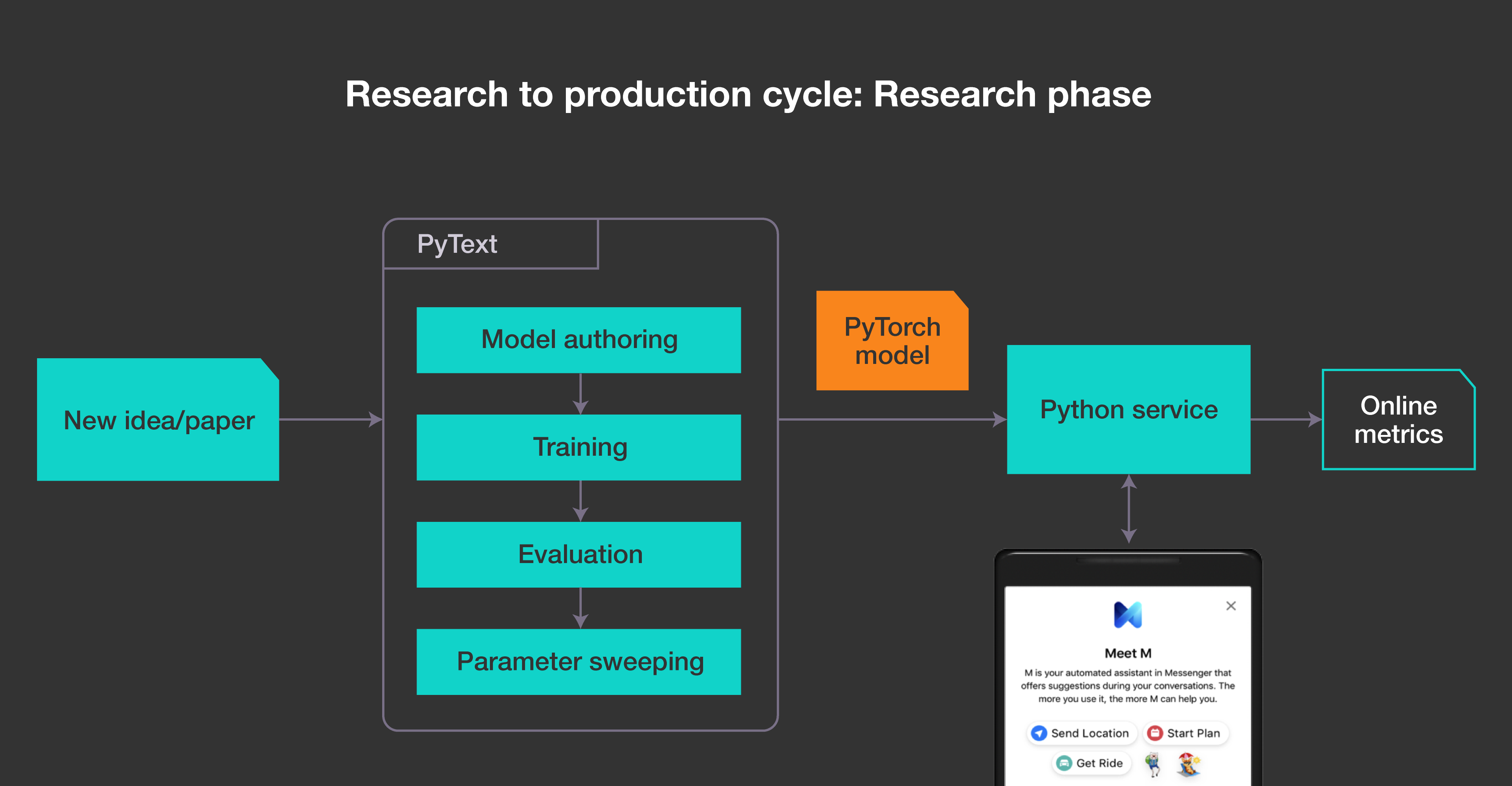
Starting with an idea for a new NLP model, PyText provides the necessary abstractions for easily authoring new models or editing existing models. It’s simple to train and evaluate them, and then perform parameter sweeping to determine the best model. PyText is designed to let AI developers focus on the specific component or model that they want to change, and use out-of-the-box components for the rest of the system.
This produces a PyTorch model that can be run in a Python environment. With PyText’s Python service, AI developers can get online metrics quickly by deploying their models and receiving traffic from a small percentage of people using the product.
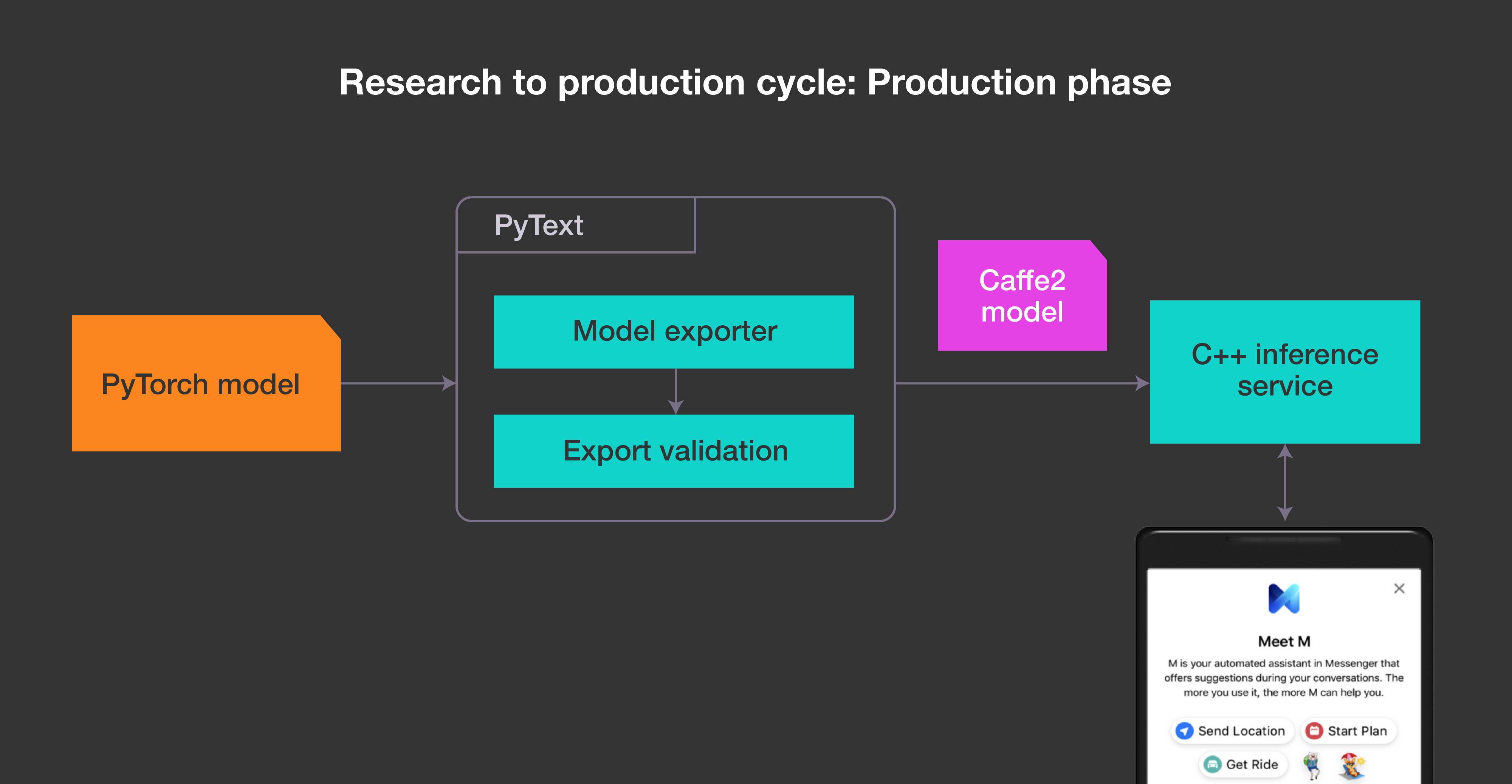
Once an engineer is satisfied with the model’s performance, he or she can use the exporter module in PyText to transform the model to Caffe2 via ONNX. The Caffe2 model can then be evaluated and deployed in a C++ inference service that can handle production traffic.
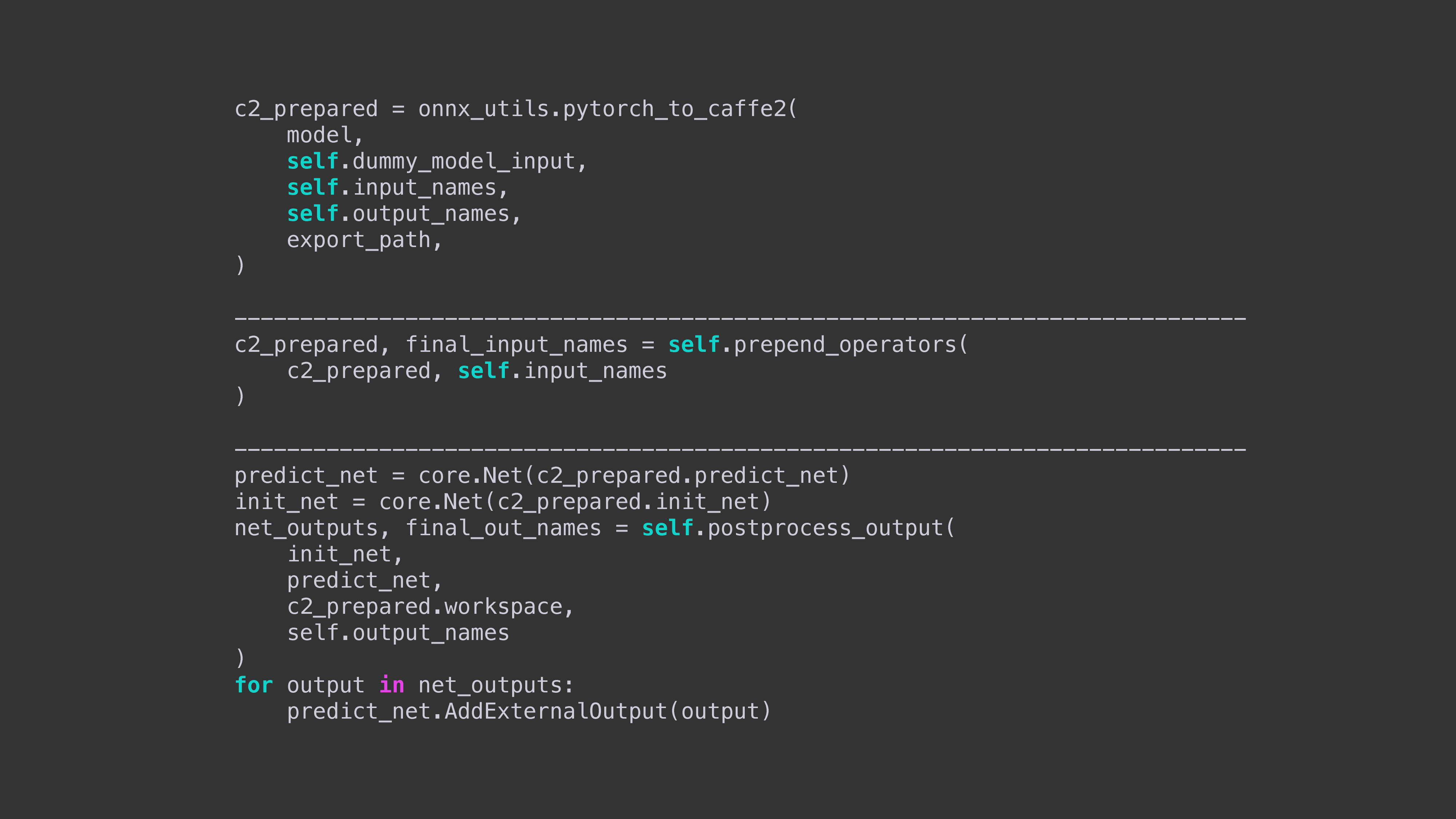
This code sample shows how to export a model to Caffe2 using ONNX, prepend an operator such as string2id, and then perform any necessary postprocessing.
The future of PyText and NLP tools
Our internal deployments have demonstrated that PyText allows engineers to iterate faster on novel NLP modeling ideas and then quickly scale them into production. The field of NLP is large and rapidly evolving, so we’ll continue to improve on PyText’s capabilities to test new state-of-the-art models and deploy them efficiently at scale.
Because putting sophisticated NLP models on mobile devices remains challenging, we are working to build an end-to-end workflow for on-device models. Our immediate plans include supporting multilingual modeling and other modeling capabilities, making models easier to debug, and adding further optimizations for distributed training. PyText has been a collaborative effort across Facebook AI, including researchers and engineers focused on NLP and conversational AI, and we look forward to working together to enhance its capabilities. For more details about PyText, read our full paper.








