
Facebook’s MySQL databases are spread across our global data centers, and we need to be able to recover from an outage in any of these locations, at any given point in time. In such a disaster event, not only do we have to recover the service as quickly and reliably as possible, but we also need to ensure we don’t lose data in the process. To that end, we’ve built a system that continuously tests our ability to restore our databases from backups.
Our restore system consists of two main components:
- Continuous Restore Tier (CRT) – Responsible for all scheduling and monitoring around restores. It looks for databases with new backups and creates restore jobs for them, monitors the restore’s progress, and ensures each backup is successfully restored.
- ORC Restore Coordinator (ORC) – Comprises the restore workers (peons) and a load balancer (warchief). The warchief receives new restore jobs from CRT and assigns them to peons. Peons host a local MySQL instance where they perform the actual restore.
The data CRT collects about each restore job’s progress helps us understand our resource requirements for database restores, and ORC helps us verify backup integrity. This post will focus on ORC’s internals — specifically the internal peon state machine and some of the challenges we had to overcome when coming up with the restore process for a single database.
Backups overview
Before building a continuous restore pipeline, we first need to understand the nature of backups available to us. Currently, we take three kinds of backups, all of which are stored in HDFS:
- Full logical backups are taken every few days using
mysqldump - Differential (diff) backups are taken on days we don’t take full backups. We do these by taking another full dump and only storing the difference between it and the last full backup that was taken. Metadata records which full backup the diff was created against.
- Binary log (binlog) backups are constantly streamed to HDFS from the database master.
Both full and diff backups pass the --single-transaction option to mysqldump so we get a consistent snapshot of the database and can both be taken from secondary as well as primary instances. I’ll refer to diff and full backups as dumps for the remainder of this post.
Since dumps are only taken once a day, having binlog backups means we get full coverage of every transaction executed against the database being backed up. This then enables us to perform point-in-time restores by replaying transactions from binlogs on top of a restored dump to bring the database’s state up to a certain point in time. All of our database servers also use global transaction IDs (GTIDs), which gives us another layer of control when replaying transactions from binlog backups.
In addition to storing backups in HDFS, we also write them to an off-site location. Shlomo Priymak’s talk at Code as Craft covers our backup architecture in much greater detail.
ORC: ORC Restore Coordinator
Architecture
ORC has three components:
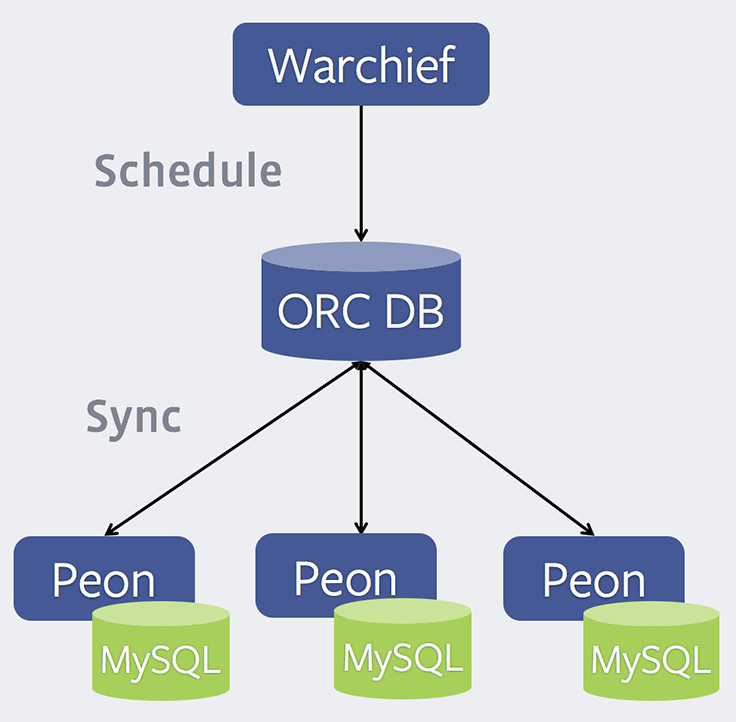
- Warchief – The load balancer. It’s a Python program exposing a Thrift interface, through which it receives new restore requests and schedules them onto available peons.
- ORC DB – Central MySQL database that maintains state about jobs assigned to each peon, current state of each job, peon health stats, and more. The information stored here is used by the warchief to decide which peon a job should be assigned to, as well as by peons during crash recovery.
- Peon – The restore workers. These are also written in Python and expose a Thrift interface, through which various stats about the peon can be obtained. Periodically, each peon syncs with the ORC DB to look for new jobs assigned to it, and reports its own health status. Servers running peons also have a local MySQL instance running on them, to which the backups are restored.
Under the hood: Peons
Peons contain all relevant logic for retrieving backups from HDFS, loading them into their local MySQL instance, and rolling them forward to a certain point in time by replaying binlogs. Each restore job a peon works on goes through these five stages:
- SELECT – Decide which backup needs to be restored for this shard (i.e. full or diff, HDFS or offsite, etc.)
- DOWNLOAD – Download the selected files to disk. If a full backup is being restored, it’s just a single file. For diff backups, we first download the full and diff backups, then apply the diff on top of the full backup, and finally store the result on disk. At this point, we have on disk a single
mysqldumpoutput, irrespective of the backup type. - LOAD – Load the downloaded backup into the peon’s local MySQL instance. Individual tables are restored in parallel by parsing out statements pertaining to those tables from the backup file, similar to Percona’s mydumper.
- VERIFY – Perform sanity checks on the data loaded into MySQL.
- REPLAY – Download and replay transactions from binary log backups on top of the restored backup, if required. We use the
mysqlbinlogprogram to filter out binlog events from other collocated databases and empty transactions, and then replay the required transactions on the same MySQL instance.
Each stage also has a corresponding failure state, so if a job fails at DOWNLOAD, it moves to the DOWNLOAD_FAILED state and doesn’t progress to LOAD.
Binlog selection logic
Perhaps the most challenging portion of the restore process is determining which binlogs to download and replay. Full and diff backups can be taken from the primary or a secondary; however, we only take binlog backups from the primary. This means simple timestamp comparisons cannot be used to determine which binlogs need to be replayed.
We deployed GTIDs across our fleet in 2014, and that gives each transaction a globally unique identifier. In addition, each running MySQL server maintains a gtid_executed (GTID set) variable, which acts as a counter of transactions executed by that instance so far.
With GTIDs in place, a transaction replicated from primary to secondary maintains its GTID, which means we know definitively whether or not it is included in a GTID set. We can also perform superset/subset comparisons against a server’s gtid_executed value since it is just a monotonically increasing counter and functions as a mathematical set.
Putting these together, we can record the gtid_executed value from the server when the dump is being taken and also record the GTID set contained in each binlog file to perform a consistent comparison and determine which transactions in a binlog need to be replayed. Further, once the first transaction to be replayed is identified, we know every subsequent transaction needs to be replayed and can avoid any additional GTID comparisons. We also use the --stop-datetime option to mysqlbinlog to determine where the binlog stream should be stopped.
Conclusion
Backups are the last line of defense in the event of a disaster; having them gives us confidence in our ability to recover from outages. However, just taking backups isn’t enough. ORC helps us continuously test our backups to verify their integrity and also gives us an understanding of the resources we’d require to successfully restore from them.
Making a system like ORC operate at Facebook scale requires adding a lot of alerting, monitoring, and automated failure detection and remediation. All of these are implemented in CRT and will be covered in a follow-up post outlining how we scale our restore process to tens of thousands of databases.
In an effort to be more inclusive in our language, we have edited this post to replace the terms “master” and “slave” with “primary” and “secondary”.








